
论文概述
wav2vec 是 Facebook AI Research 2019 年提出的模型。
wav2vec 需要对音频数据进行采样,频率为16k Hz。
在DeepMind的CPC模型验证了自监督预训练方法得到的特征向量在语音领域的有效性能之后,FAIR的Steffen Schneider等人也提出了wav2vec模型,通过使用自监督预训练的方法关注于提升有监督语音识别的效果。自此也开启了FAIR的wav2vec一系列的工作。
模型结构
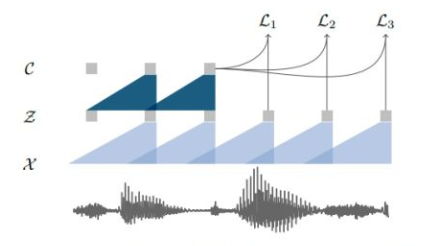
给定输入语音信号 ,我们首先使用encoder网络(如CPC一样使用5层CNN)进行编码得到隐变量 $Z$ ,再使用context网络(不同于CPC的RNN,wav2vec使用CNN)编码历史时刻的隐变量得到上下文特征向量
。由于wav2vec模型摒弃了RNN,完全使用CNN网络,模型可以很容易地实现并行训练,大大提升自监督预训练的效率。
类似于CPC模型,wav2vec模型也使用对比学习的优化目标,将当前时刻的上下文特征向量 通过线性变换与未来
时刻的隐变量
计算点乘相似度作为对比学习的正例。相应的负例以均匀分布从隐变量序列中采样得到。
优化目标公式为:
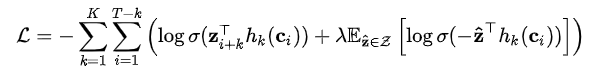
不同于CPC模型使用多分类交叉熵(categorical cross-entropy)损失函数,wav2vec模型使用的是二分类交叉熵(binary cross-entropy)损失函数。
模型试验
不同于CPC文章中作者只训练一个线性层来评估预训练特征向量中包含的语义信息,wav2vec的作者们将预训练的wav2vec模型作为特征提取器,代替人工定义的声学特征输入给ASR模型,并且直接在多个语音识别数据集上直接与baseline ASR模型以及SOTA结果进行比较。
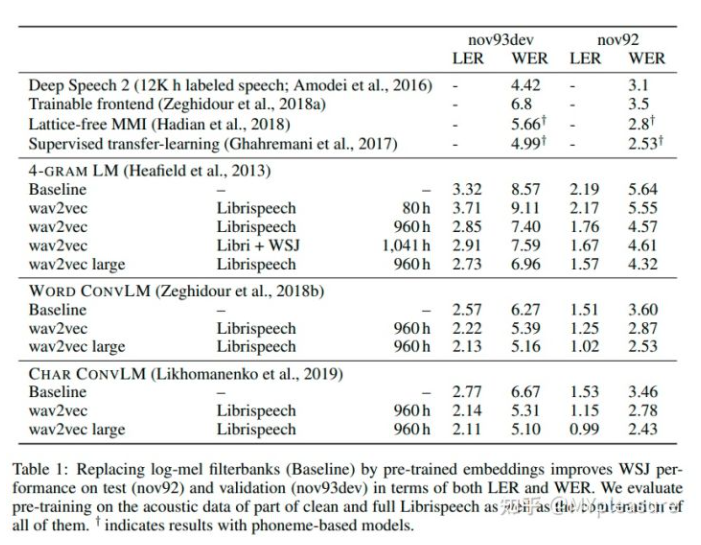
通过上表wav2vec在WSJ数据集上的结果,我们可以发现使用预训练的wav2vec模型提取的特征可以有效地提升baseline ASR模型的结果。尽管使用的ASR模型相对较差,wav2vec提供的特征仍能够取得比SOTA的基于字符的方法(Deep Speech 2)更好的结果。并且与基于音素且使用了Librispeech标注数据的方法(Supervised transfer-learning)相比,wav2vec large只使用Librispeech无标注数据仍能够取得更好的结果。
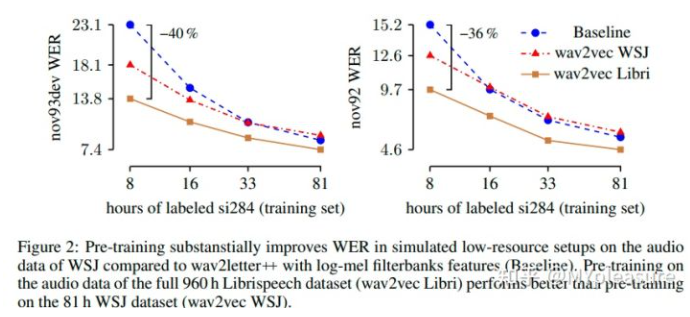
上表显示的是不同的预训练数据(WSJ或者Librispeech)以及不同的标注数据量对于结果的影响。我们可以发现用Librispeech数据进行训练要明显好于WSJ数据集,并且在仅有8小时训练数据的时候相较于baseline能够实现36%之多的结果提升。
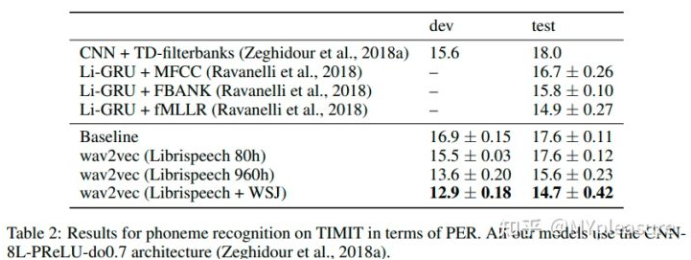
在TIMIT数据集上,wav2vec预训练模型提供的特征可以成功达到SOTA的结果,并且使用越大的自监督预训练数据集得到的wav2vec模型提供的特征可以取得越好的结果。
wav2vec文章中虽然使用了Librispeech训练集作为无标注数据集进行自监督预训练,却没有将Librispeech数据集作为下游语音识别任务与前人工作进行比较。
wav2vec系列的后续工作逐渐将语音识别任务的重心从较为简单的WSJ数据集转移到更为困难的Librispeech数据集,并在wav2vec 2.0中终于可以成功地在Librispeech数据集上实现SOTA的结果。
参考资料
Til next time,
gqjia
at 10:56
