

CPC 是 DeepMind 2018年提出的论文。论文一作是 Aaron van den Oord ,他同时也是 VQ-VAE 的一作。
论文概述
论文提出了一种通用的无监督学习方法CPC(Contrastive Predictive Coding),能够从高维数据中提取有用信息。
模型的关键在于使用自回归模型在潜在空间(latent space)1通过预测未来(的元素)来学得表征(representation)。实验证明这一方法不仅能够学得良好的表示,而且可以应用于语音、图像、文本和3D环境中的强化学习。
这项工作的动机是希望模型能够通过自监督学习的方式建模得到包含高维语义信息的特征表示(比如语音中的音素信息、图像中的物体信息、书本中的故事线信息),同时忽视掉低层的信息和噪声信号2。
latent space是什么?1
Latent Space在机器学习和深度学习中都是一个十分重要的概念。
The concept of “latent space” is important because it is utility is at the core of ‘deep learning’ —learning the features of data and simplifying data representations for the purpose of finding patterns.
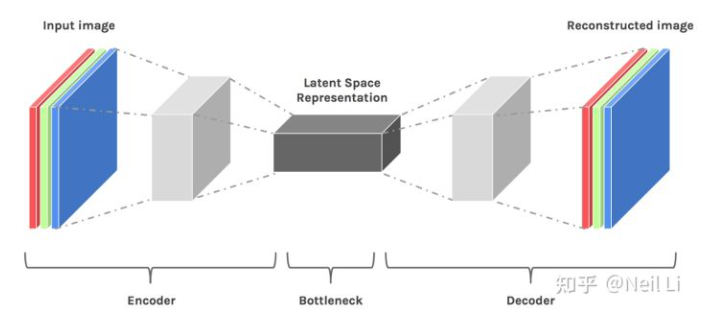
我们来训练一个模型来使用完全卷积神经网络 (FCN) 对图像进行分类。 (即给定数字图像的输出数字编号)。 当模型“学习”时,它只是简单地学习每一层(边缘、角度等)的特征,并将特征组合归因于特定的输出。因为模型需要重建压缩数据,所以它必须学会存储所有相关信息并忽略噪声。 这就是数据压缩的价值——它允许我们摆脱任何无关的信息,只关注最重要的特征。
我们来理解Space的含义。假设我们的原始数据集是为 5 x 5 x 1 的图像。我们将Latent Space的维度是 3 x 1,就能够将一张图片压缩成一个3维数据点,而这个三维数据点就可以在三维空间去可视化表示。
Whenever we graph points or think of points in latent space, we can imagine them as coordinates in space in which points that are “similar” are closer together on the graph.
利用PCA、t-SNE等技术,我们能够将高维度的数据映射到低纬度数据空间。
在Representative Learning中,Latent Space能够将更加复杂形式的原始数据转化为更简单的数据表示,而更有益于去做数据处理。下面祭出瑞士卷的manifold,在瑞士Migros的超市卖的这个东西真的甜到腻。
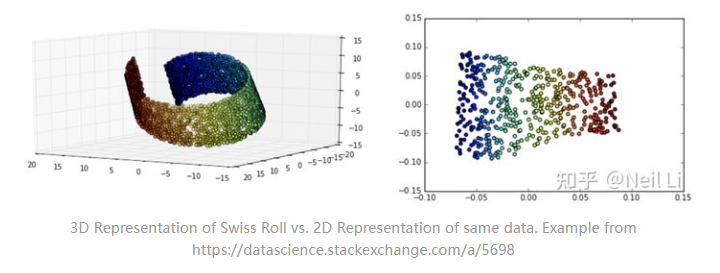
可以看到将3维数据映射到2维空间后,通过添加分割线可以很好地区分开不同颜色的点,而在原来3维空间内,就很难找到一些合适平面去做分割。
接下来是自然而然地就想到了Autoencoders and Generative Models,这个在图像压缩,图像降噪,包括近几年很火的GAN等很多技术中都有应用。
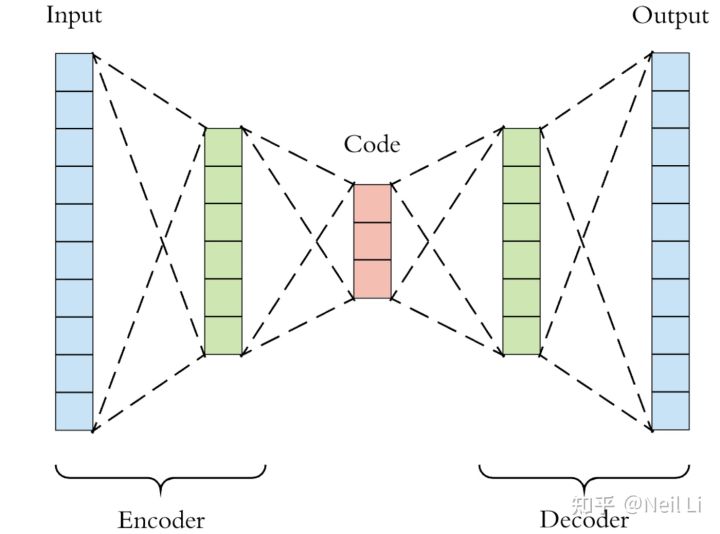
比如下面这个可以通过对Latent Space进行插值来生成不同的面部结构,并使用deconder将Latent Space表示重构为与原始输入具有相同维度的二维图像。

模型结构
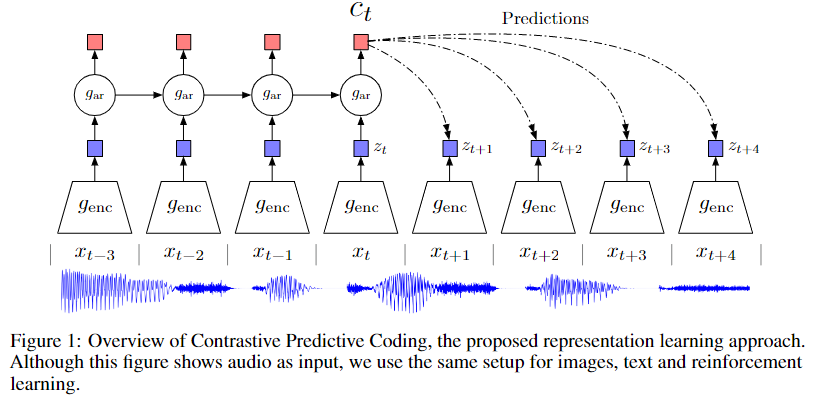
具体的网络架构如上图所示,作者首先使用非线性编码层 $g_{enc}$(实验使用5层CNN+ReLU)对于输入信号 下采样编码得到隐变量
,再使用自回归模型
(一层GRU RNN)编码历史时刻的隐变量
得到上下文特征
。
对于互信息的优化目标,作者基于NCE提出一种叫做InfoNCE的对比学习损失函数,并且证明了最小化InfoNCE loss 等价于最大化上述互信息
的一个下界(lower bound)。
InfoNCE loss的具体公式为:
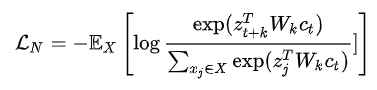
我们可以发现这其实是相似度计算公式再加上多分类交叉熵(categorical cross-entropy)损失函数公式。 每个位置上的上下文特征向量 通过线性变换 $W_k$,与未来k时刻的隐变量 $z_{t+k}$计算点乘相似度,作为对比学习的正例。对比学习的负例是从数据集中随机采样得到,实验部分发现从与正例相同的utterance或者speaker中采样负例得到的效果最好。这其实也符合直观印象,当挑选的负例与正例有着相似的噪声信号时,对比学习的优化目标可以使得模型去更好地学习能够区分正例和负例的高维度语义信息。
模型实验
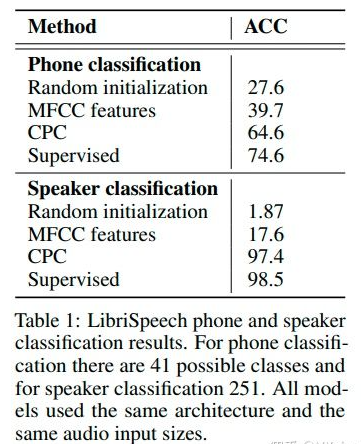
上图为CPC模型在语音领域的实验结果。作者通过训练一个线性分类器来验证CPC提取的特征中包含的音素/说话者信息。我们可以发现通过使用自监督学习得到的特征,我们可以在音素分类和说话者分类任务上都能够取得比人工定义的声学特征MFCC特征更好的结果,并且也能够取得接近于使用同样的模型结构进行有监督训练的结果。
论文结论
除了语音领域,CPC还在图像、NLP和强化学习领域里进行实验并且取得了很好的结果,可谓大一统的经典自监督学习方法。
参考资料
Til next time,
gqjia
at 10:31
