
论文提出了一个 DGST 神经网络。该模型抛弃了鉴别器和平行语料,只使用两个生成器就可以完成文本风格迁移的任务。论文设计了一种句子去噪的方法,称为领域采样(neighbourhood sampling)。先给每个句子引入噪声,再使用模型完成去噪操作。
模型结构

以非平行语料X和Y为例,这两条数据的风格为$S_x$和$S_y$。模型的目的是将其中一种风格转换为另一种风格,同时保留与风格无关的语境。
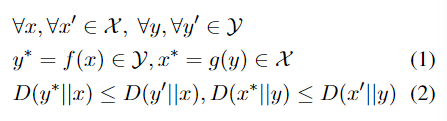
$D(x|y)$是根据最小编辑距离测量句子之间抽象距离的函数,其中编辑操作包括词级替换、插入和删除(汉明距离)。等式1要求迁移的文本应该在目标风格空间内,等式2要求迁移的文本不能更改太多,保留与风格无关的信息。
作者受到CycleGan的启发,同样采用循环的形式进行训练,设计两个转换器:一个转换器将一个风格的数据转换到另一个风格的数据,另一个转换器将另一个风格的数据转换回源风格的数据。训练时设计了两个训练目标,一个确保生成文本的信息尽可能被保存;另一个将输入文本风格转换为目标风格。
模型代码
模型训练部分代码如下:
data0_ = conbine_fix(data0, p1)
data1_ = conbine_fix(data1, p1)
optimizer.zero_grad()
prod_0to1 = T_to1(data0) # 数据0进入第一个模型
prod_0to1 = conbine_fix(T_to1.argmax(prod_0to1), p2) # 以 p2 的概率给模型输出添加噪声
prod_0to1to0 = T_to0(prod_0to1) # 数据进入第二个模型
prod_1to0 = T_to0(data1) # 对第二个数据进行相似的处理
prod_1to0 = conbine_fix(T_to0.argmax(prod_1to0), p2)
prod_1to0to1 = T_to1(prod_1to0)
L_t = T_to0.loss(data0, prod_0to1to0) + T_to1.loss(data1, prod_1to0to1)
prod_0to0 = T_to0(data0_) # 添加噪声的数据分别进入两个模型进行处理
prod_1to1 = T_to1(data1_)
L_c = T_to0.loss(data0, prod_0to0) + T_to1.loss(data1, prod_1to1)
(L_t + L_c).backward() # 两个 loss 相加后反向传递
这两个模型采用的是相同的结构:
# 模型
T_to1 = Trans(vocabulary_size, embedding_size).to(device)
T_to0 = Trans(vocabulary_size, embedding_size).to(device)
作者采用了三种编码器,4 层的 BiLSTM 、1 层的 BiLSTM 和 Transformer 。
数据处理代码
论文在数据处理部分的代码也很有意思,尤其是数据持久化部分。
class DataPair(Dataset):
def __init__(self, data0_path, data1_path, min_word_count=4, base_corpus=None, model_path="./model_save/", amount=1,
device=None):
with open(data0_path) as f: # 读取文件
data0 = [s.strip().lower() for s in f.readlines()]
with open(data1_path) as f:
data1 = [s.strip().lower() for s in f.readlines()]
corpus = " ".join(data0 + data1) # 直接合并为以空格切分的字符串
# 数据持久化 使用哈希算法进行加密
xcode = hashlib.sha1(
f"{corpus}-{min_word_count}-{device}-{base_corpus.xcode if base_corpus is not None else 0}".encode('utf-8'))
self.xcode = int(xcode.hexdigest(), 16) % 10 ** 8
model_file_path = f"{model_path}DataPair_{self.xcode}.pk" # 比如: DataPair_56625810.pk
if os.path.exists(model_file_path): # 数据存在则直接进行存储
info = torch.load(model_file_path)
print(model_file_path)
self.xcode = info["xcode"]
self.data0 = info["data0"]
self.data1 = info["data1"]
self.word_id = info["word_id"] # token to id
self.id_word = info["id_word"] # id to token
else: # 不存在持久化后的数据
self._make_dic(corpus, min_word_count, base_corpus) # 构建词典
label0 = torch.tensor([1.0, -1.0], device=device)
label1 = torch.tensor([-1.0, 1.0], device=device)
# 将文本转化为 tensor,数据按照空格切分
self.data0 = [self.sentence_to_tensor(s.split(" "), device=device) for s in data0]
self.data1 = [self.sentence_to_tensor(s.split(" "), device=device) for s in data1]
info = {}
info["xcode"] = self.xcode
info["data0"] = self.data0
info["data1"] = self.data1
info["word_id"] = self.word_id
info["id_word"] = self.id_word
torch.save(info, model_file_path) # 数据保存
self.data0 = info["data0"][:int(len(self.data0) * amount)]
self.data1 = info["data1"][:int(len(self.data1) * amount)]
self.vocab_size = len(self.word_id)
self.data0_len = len(self.data0) # 数据的长度
self.data1_len = len(self.data1)
def _make_dic(self, corpus, min_word_count, base_corpus=None): # 构建词典
if base_corpus is not None:
self.word_id = base_corpus.word_id
self.id_word = base_corpus.id_word
else:
corpus = corpus.split(" ") # 以空格切分为词
words = sorted(corpus)
group = groupby(words)
word_count = [(w, sum(1 for _ in c)) for w, c in group]
word_count = [(w, c) for w, c in word_count if c >= min_word_count]
word_count.sort(key=lambda x: x[1], reverse=True)
word_id = dict([(w, i + 4) for i, (w, _) in enumerate(word_count)])
word_id["<pad>"] = 0 # 词典前四个为特殊字符
word_id["<unk>"] = 1
word_id["<sos>"] = 2
word_id["<eos>"] = 3
self.word_id = word_id
self.id_word = dict([(i, w) for w, i in word_id.items()])
def sentence_to_tensor(self, sentence, device):
v = [self.word_id.get(w, 1) for w in sentence]
v = [2] + v + [3] # 添加首尾 token
v = torch.tensor(v, device=device)
return v
def shuffle(self): # 打乱顺序
random.shuffle(self.data0)
random.shuffle(self.data1)
def __getitem__(self, index):
index0 = index1 = index
b_size = index.stop - index.start
if index0.stop > self.data0_len:
s = random.randint(0, self.data0_len - b_size - 1)
index0 = slice(s, s + b_size)
if index1.stop > self.data1_len:
s = random.randint(0, self.data1_len - b_size - 1)
index1 = slice(s, s + b_size)
return self.data0[index0], self.data1[index1]
def __len__(self):
length = max(self.data0_len, self.data1_len)
return length
def totext(self, sen):
text = [self.id_word[i] for i in sen]
return " ".join(text)
CycleGan 模型
CycleGAN主要用于域迁移(Domain Adaption)领域,如图片风格迁移(image style transfer)。

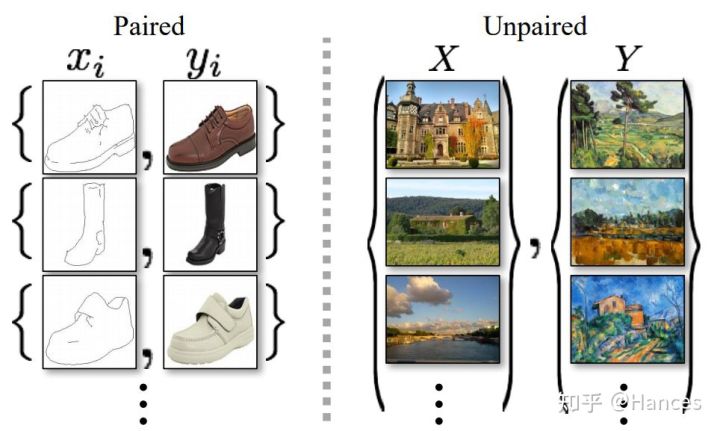
像这样,CycleGAN能将真实照片转换成不同风格,但转换后的图片又能保留原始照片中的各种内容。在此之前如pix2pix等其他网络能够实现Domain Adaption,但需要的训练数据必须是成对的,即在训练时,将一张样本照片输入给模型,就必须输入其对应风格的图片,这对训练数据的要求是较高的,因为往往现实中不存在这么多成对的数据,而CycleGan可以做到“unpaired image-to-image translation”,具体来说,我们有一堆照片(但之前并没有这些照片的梵高风格表示),一堆梵高的画作,我们同时喂给机器,机器就能将照片转换成梵高的风格。关于成对数据和不成对数据,原论文给出下图。
为了平衡模型保存内容的能力和风格迁移的能力,模型首先按照DAE(denoising autoencoders)的方式,这样的方式有助于保存除风格外的内容。模型将带噪声的句子进行还原。
模型如何增加噪声的?
添加噪声部分代码如下:
def random_replace(data, p=0.4):
# data = data.clone()
shape = data.shape # shape = [256, 17]
for _ in range(int(shape[0] * shape[1] * p)): # 从 256x17 个 token 中选择 256x17x0.4 个 token
# random.randint(0, shape[0] - 1) 从 bsz 维度选择一个数,
# random.randint(0, shape[1] - 1) 从 max_len 维度选择一个数,
# random.randint(3, vocabulary_size - 1) 从词典中选择一个数
data[random.randint(0, shape[0] - 1), random.randint(0, shape[1] - 1)] = random.randint(3, vocabulary_size - 1)
return data
def conbine_fix(data, p=0.4): # 加噪声,随机替换
data = data.clone()
data = random_replace(data, p)
return data
# 输入数据维度为 256x17 ,第一个维度是 bsz 第二个维度是 max_len
data0_ = conbine_fix(data0, p1)
data1_ = conbine_fix(data1, p1)
损失函数设计这部分没看懂,感觉不如代码简单明了。
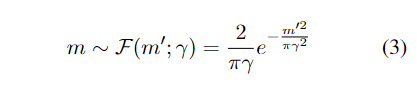
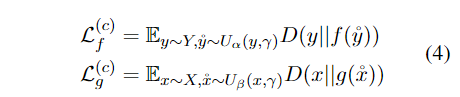
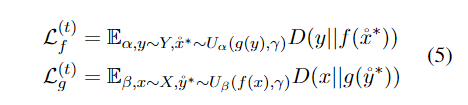
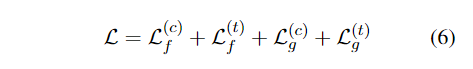
模型实验
模型在Yelp数据集和IMDb数据集上验证效果。作者从迁移强度(Transfer Intensity)和保存程度(Content Preservation)两个方面对模型进行评估。作者用fasttext训练了一个分类器来评估迁移强度;用BLEU分数来评估保存内容的程度。
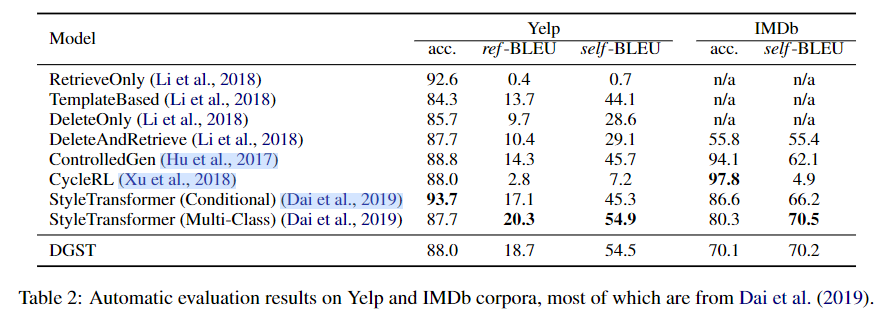
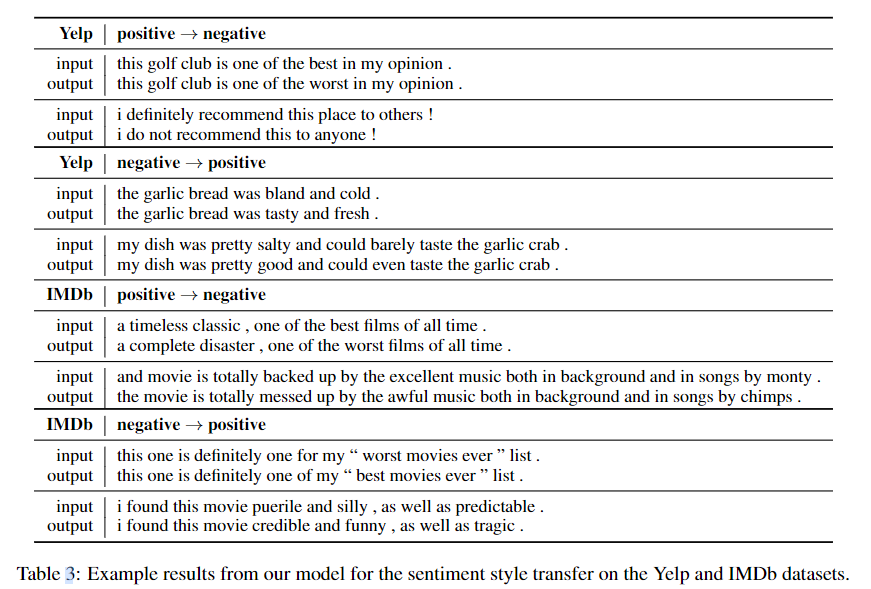
在不借助对抗训练、强化学习、外部离线情感分类器的情况下,DGST在Yelp数据集上超越了除StyleTransformer以外的基线模型。而且相比StyleTransformer来说,DGST使用的是BiLSTM。在IMDb数据集上,DGST的迁移能力处于中等水平,而BLEU评分只低于StyleTransformer。模型实验的样例如下:
消融实验
作者设计了消融实验,分别为:
- (1)no-res 去除了重建的训练目标;
- (2)rec-no-noise 在重建时不加入噪声;
- (3)no-tran 去除了迁移的训练目标;
- (4)tran-no-noise 在迁移时不加入噪声。
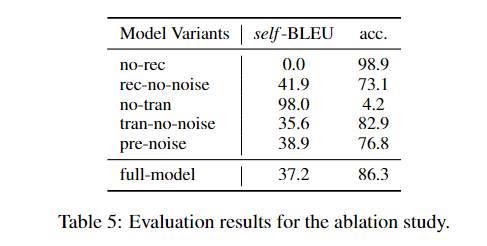
根据实验,取消重建和迁移的训练目标会分别降低保存能力和迁移能力。在重建的训练目标使用噪声可以平衡模型保存和迁移的能力;对于迁移的训练目标,不使用噪声或者在错误的位置放置噪声将会降低模型的迁移能力。
参考资料
Til next time,
gqjia
at 09:54
