
文本风格迁移任务
文本风格迁移任务旨在保留文本内容的基础上通过编辑或生成 的方式更改文本的特定风格或属性(如情感、时态和性别等)1。文本风格迁移可以应用在许多现实场景中,例如文本润色、诗歌创作、人机对话、特定风格标题生成、社区评论环境改善1。

文本风格迁移的方法主要分为监督学习的方法、半监督学习的方法、无监督学习的方法。由于文本风格迁移任务本身缺乏平行语料的问题,当前的研究以无监督学习的方法为主。
基于监督学习的方法与文本摘要和机器翻译任务相同,可以使用Seq2Seq的神经网络。同时也可以引入强化学习的策略,将生成文本的风格正确率得分和内容保留度得分作为奖励,促使模型生成更加符合要求的文本。
基于半监督学习的方法旨在研究如何同时利用少量的有类标签的样本和大量的无类标签的样本改进学习性能。Shang2使用隐空间交叉投影的方法,定义不同风格的隐空间之间的投影函数,并以此完成文本风格的迁移。Zhang 使用三种数据增强的方法扩充语料(回译、正式性判别、多任务迁移)。先使用扩充预料对Seq2Seq模型进行预训练,再使用原始的平行语料对模型进行微调。
无监督学习的方法分为隐式方法和显式方法。隐式方法是指模型自动学习句子内容和属性的潜在表示并进行风格的分离与转换。目前主要采用了解缠、强 化学习、回译、伪平行语料等策略,并基于自编码器、变分自编码器、生成对抗网络等模型学习文本的潜在表示1。显式的方法只改变风格相关的词或短语而保留风格无关的部分。该类方法一般分成三步,第一步找到并删除句中的属性词;第二步检索与文本内容最相似的目标句子;第三步结合目标属性生成目标句子。这类方法统称为DRG方法,如下图所示,也可以不通过检索直接生成目标句子。
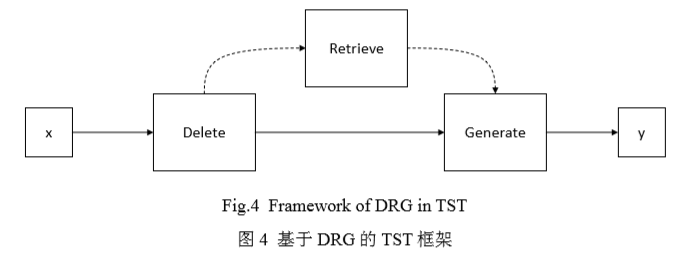
缠绕的策略主要是通过编码器将文本映射到隐空间得到潜在的表示,从而分离内容和属性并进行属性迁移。
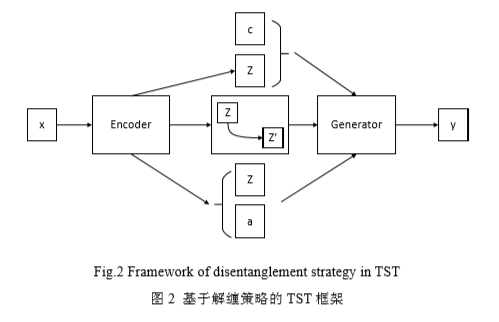
缠绕的策略分为三种,第一种使用对抗学习的方式将生成的目标句子送入属性判别器,再通过判别器优化生成器,从而是的目标属性完全由编码$c$控制,属性无关的文本内容完全由编码$z$控制;第二种则是在属性分类器的指导下下对潜在表示进行编辑,迭代执行这一过程 直到潜在表示具有目标属性类别为止。其中, $z$ 表示为经过编码器编码后得到的潜在表示, $z’$ 表示在属性分类器监督 下优化后得到的潜在表示;第三种解缠策略是先将输入的文本编码为两个潜在表示,一个包含源属性信息,另一个包含文本的内容信息,然后将a 替换为目标属性,最后使用 z 和c 的组合进行解码。
主流无监督的文本风格迁移方法对比图如下:
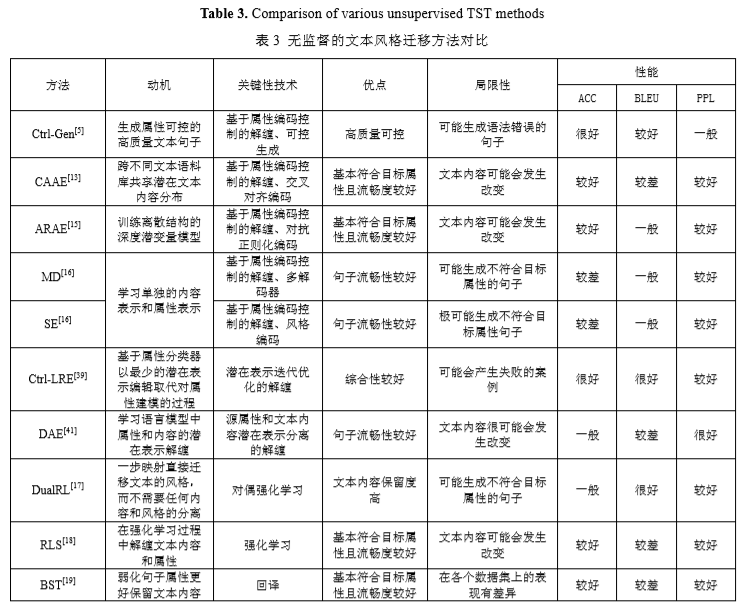
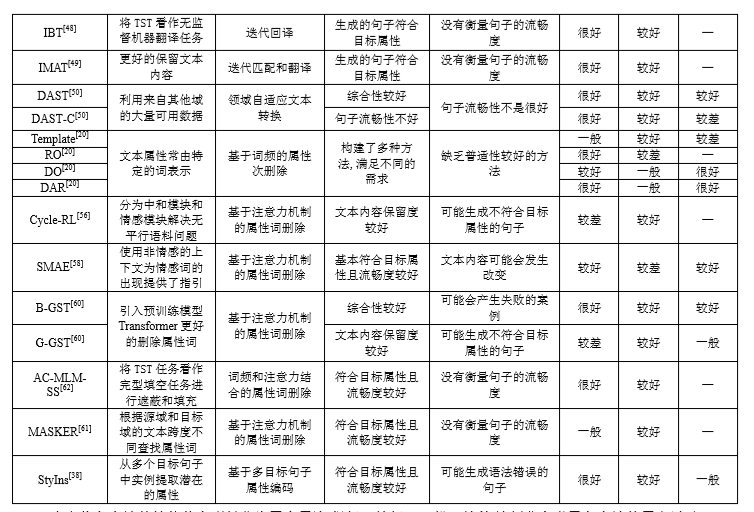
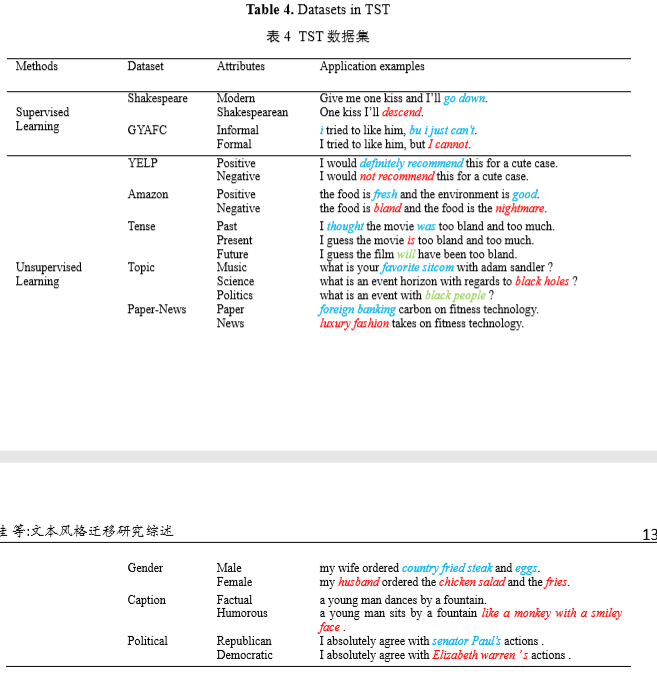
文本风格迁移任务的数据集分为平行语料数据集和非平行语料数据集。

Yelp数据集的例子:
-
test.0: ever since joes has changed hands it ‘s just gotten worse and worse .
自从乔斯易手后,情况就越来越糟了。
test.1: it ‘s small yet they make you feel right at home .
它很小,但它们会让你感觉自己很宾至如归。
-
test.0: there is definitely not enough room in that part of the venue .
那部分场地肯定没有足够的空间。
test.1: i will be going back and enjoying this great place !
我会回去享受这个很棒的地方的!
-
test.0: so basically tasted watered down .
所以基本上尝起来都被冲淡了。
test.1: the drinks were affordable and a good pour .
这些饮料价格实惠,倒酒量也很好。
-
test.0: she said she ‘d be back and disappeared for a few minutes .
她说她会回来,然后消失了几分钟。
test.1: my husband got a ruben sandwich , he loved it .
我丈夫买了一个鲁宾三明治,他很喜欢。
-
test.0: i ca n’t believe how inconsiderate this pharmacy is .
我不敢相信这家药店居然这么不体贴。
test.1: i signed up for their email and got a coupon .
我注册了他们的电子邮件,并得到了一张优惠券。
-
Shakespeare数据集的例子:
-
vaild.modern: Now , you lie there on the path .
现在,你就躺在那条小路上。
vaild.original: Lie thou there ( throwing down a letter ) , for here comes the trout that must be caught with tickling .
-
vaild.modern: She said if she were interested in someone , it would be someone who looked like me .
她说,如果她对某人感兴趣,那就会是一个长得像我的人。
vaild.original: Maria once told me she did affect me , and I have heard herself come thus near , that , should she fancy , it should be one of my complexion .
-
vaild.modern: Besides , she treats me more respectfully than the other servants .
此外,她对我比其他仆人更尊重我。
vaild.original: Besides , she uses me with a more exalted respect than anyone else that follows her .
此外,她对我的尊敬比任何跟随她的人都更崇高。
-
文本风格迁移的自动化评价一般包含准确率(Accuracy)、BLEU 以及困惑度(Perplexity, PPL)等。
Unsupervised (Non-parallel Data)
DGST: a Dual-Generator Network for Text Style Transfer [EMNLP 2020]
论文提出了一个 DGST 神经网络。该模型抛弃了鉴别器和平行语料,只使用两个生成器就可以完成文本风格迁移的任务。论文设计了一种句子去噪的方法,称为领域采样(neighbourhood sampling)。先给每个句子引入噪声,再使用模型完成去噪操作。
Supervised (Parallel Data)
Thank you BART! Rewarding Pre-Trained Models Improves Formality Style Transfer [ACL 2021]
由于平行语料的稀缺导致文本风格迁移任务在内容保存部分效果较差。作者使用 GPT-2 和 BART 提高了内容保存的能力。实验证明,对预训练语言模型进行微调是在数据量比较少的情况下也能取得比较好的效果。通过对文本风格和文本内容两方面进行奖励,模型在数据上取得SOTA。
Formality Style Transfer with Shared Latent Space [COLING 2020]
平行语料下的文本风格迁移通常借助机器翻译的模型,但是这通常需要大量的平行数据进行训练,而文本风格迁移的数据集通常都比较小。论文提出一种基于 Shared Latent Space 的 Seq2Seq 模型 S2S-SLS。这个方法引入了两个辅助损失,并且采用了双向迁移(bi-directional transfer)和自动编码(auto-encoding)的联合训练。实验表明,S2S-SLS 无论使用 RNN 还是 Transformer 架构,在数据有限的情况下效果始终优于基线。
Automatically Neutralizing Subjective Bias in Text [AAAI, 2020]
论文提出了一个将带有偏见(主观观点)文本转换为中立文本的任务。作者整理了一个带偏见文本和中立文本的平行语料库。该语料库总共包含180,000条来自维基百科的句子对。作者最后还设计了两个基线。
Harnessing Pre-Trained Neural Networks with Rules for Formality Style Transfer [EMNLP-2019]
将口语文本转换为正式文本的任务早先的做法是使用规则将非正式的文本进行规范化。即使在使用神经网络时期,基于规则的处理仍然是必要的预处理,但是这样的做法可能会引入噪声。论文研究了如何将规则应用在一个神经网络中,并提出了 三种微调方法。
参考资料
Til next time,
gqjia
at 10:10
