
中科院的紫初太东模型。
如果不是工作需要,谁又会看这篇论文呢?
论文概述
OPT是一个包含三个模态的预训练语言模型。模型由一个 Seq2Seq 的框架构建,包含三个单模态编码器,用于生成每个模态的嵌入;一个跨模态编码器,用于捕获三个模态之间的关联性;两个跨模态解码器,用于生成文本和图像。预训练数据集采用 Open Images 数据集,预训练任务从三个不同粒度学习多个模态的对齐和转换。实验表明,OPT 不仅可以学得较强的多模态表征还可以在跨模态理解和生成任务上取得良好得结果。
模型结构
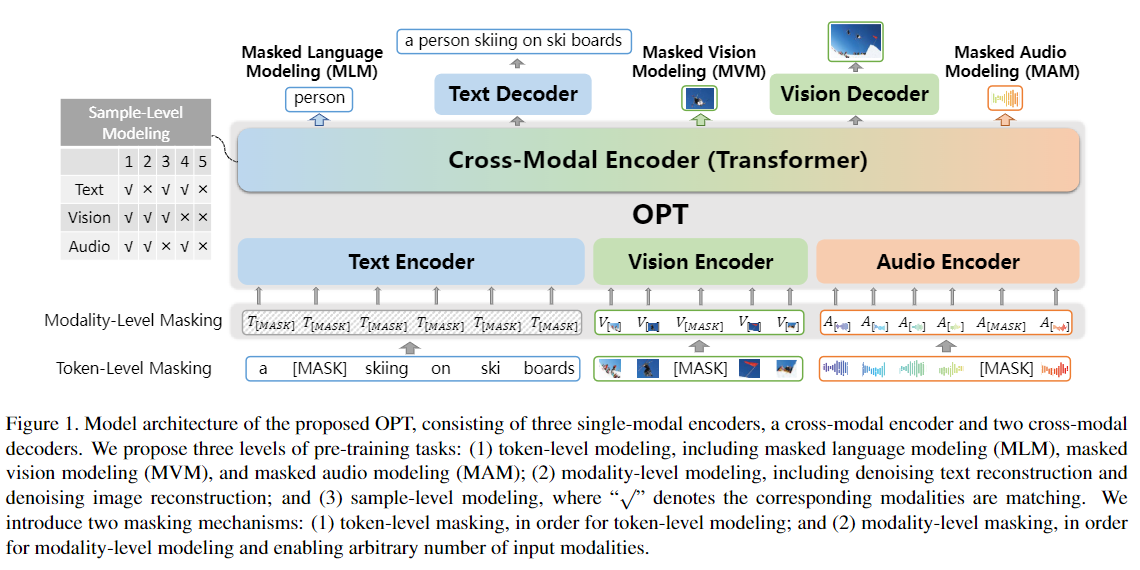
OPT模型首先使用三种单模态编码器对文本、图片、语音进行编码。然后将三种表征使用 Transformer 进行跨模态交互。最后使用两种解码器重建输入文本和图像。
文本编码器按照 BERT 的思路,分词部分使用 WordPiece ,将 token embedding 和 position embedding 相加之后经过一层 LayerNorm 层得到文本的表征。
图像编码器使用在 Visual Genome 数据集上训练好的 Faster R-CNN 提取每个区域的表征。为了捕获空间位置信息,论文引入了一个7维特征 $[x_1, y_1, x_2, y_2, w, h, w * h]$ 。其中 $(x_1, y_1) $、$(x_2, y_2)$ 代表左上角和右下角坐标; $w/h$ 代表区域的宽度/高度。首先使用两个全连接层将图像特征和位置特征投影到相同的映射空间,再将两者相加通过LN层得到最终的表征。
语音编码器使用训练好的 wav2vec 2.0 模型获取语音的 token 以及每个 token 的表示。最后通过LN层得到音频的表征。
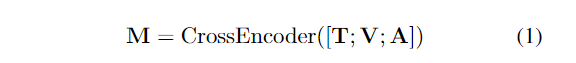
在得到各个模态的表征后,将三者进行拼接送入到基于 Transformer 的跨模态编码器中。
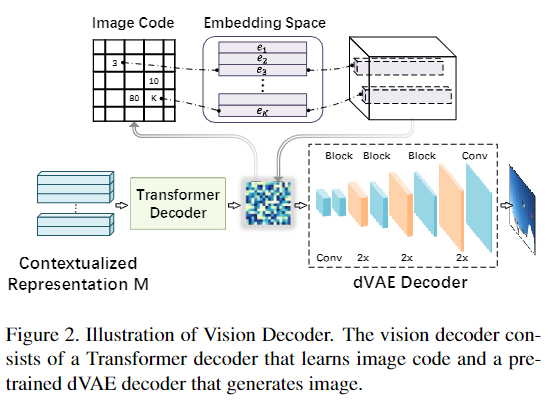
文本解码器采用 Transformer 的解码器。在图像解码器上,论文设计了一个两阶段的框架来生成图像。第一阶段将图像表示为离散序列编码,第二阶段构建了一个语言模型来学习如何生成编码序列(?)。在推理阶段,首先使用训练好的自回归模型将输入文本以 top-k 采样转换为编码序列,最后使用第一阶段的 dVAE 解码器生成图像。
预训练任务
论文使用了三种粒度的预训练任务:
- 字符级别的任务: masked language model (MLM) ; masked vision modeling (MVM) ; masked audio modeling (MAM)
- 模态级的任务:噪声文本重建(denoising text reconstruction); 噪声图像重建(denoising image reconstruction)
- 样本级建模
字符级任务
对于文本序列 $T = {T_1, T_2, …, T_N}$ ,论文按照 BERT 的方案随机 MASK 15% 的单词,然后让模型根据文本上下文、图像、语音预测被 MASK 的词。
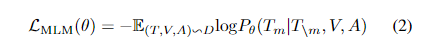
图像部分 MVM 同样对图像区域进行采样,以 15% 的概率 MASK 特征,以其他信息进行预测。因为视觉特征是高维且连续的,不能采用与文本一致的似然目标,论文采用了两种训练目标:
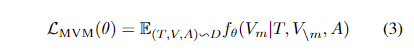
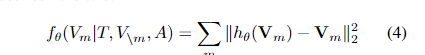
第一个训练目标是 掩码视觉特征回归( Masked Visual Feature Regression , MVFR )。它将每个掩码区域 $V_m$ 的跨模态输出回归到其输入的 ROI 视觉特征 $V_m$ 。论文使用额外的 FC 层,将跨模态编码器输出的转换为与输入视觉特征的相同的维度,然后再两者之间使用 L2 回归。其中 $h(.)$ 代表跨模态编码器上额外增加的一层 FC 层。
第二个训练目标是对 掩码区域 分类(Masked Region Classification, MRC)。由于没有真实的标签,模型选择 Faster RCNN 中被检测到的目标类别(最高置信度的类别)作为 掩码区域 的标签。将每个掩码区域的跨模态输出 送入 FC 层预测目标类别, 并通过softmax 函数进一步转换为标准化分布,最终的目的是使得交叉熵(Cross-entropy) 损失函数最小化:
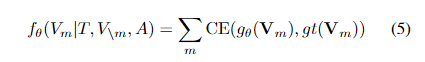
其中 $g_\theta(.)$ 由跨模态编码器、一个 FC 层、一个 softmax 函数组成。 $gt(V_m)$ 代表真是标签的 one-hot 向量。
语音 MAM 同样以 15% 的概率 MASK 音频特征,然后使用剩余音频特征和其他模态信息预测 MASK 音频特征 $A_m$。论文提出两个针对 MAM 的训练目标,它们具有相同的损失函数。
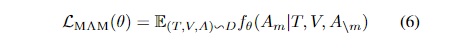
跟 MAFR 一致,第一个训练任务是是 掩码音频特征回归(Masked Audio Feature Regression) ,训练目标是最小化输入特征和输出之间的 L2 回归损失。
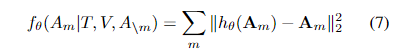
论文选择使用对比学习的方法最大化被遮蔽的输出特征和原始特征之间的互信息(Mutual Information),而不是直接对 被遮蔽音频特征回归。对于每个被遮蔽的音频特征,选择其原始特征作为正例,其他 token 作为负例:
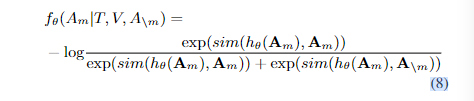
其中 $sim(.,.)$ 是余弦相似度, $h_\theta(.)$ 包括跨模态编码层和 FC 层。
模态级任务
模态级的预训练任务包括 文本重构(denoising text reconstruction) 和 图像重构(denoising image reconstruction)。
论文使用了一种模态级别的 MASK 机制,以 0.3 的概率独立 MASK 每个模态,并且跳过所有模态都被 MASK 的情况。这样可以使得 OPT 可以通过一个、两个和三个模态的输入处理不同的下游任务。
DTR 任务上在跨模态编码器的顶部增加一个 Transformer 的解码器,以学习如何重构输入文本。损失函数为:
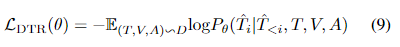
DIR任务上,视觉解码器由 Transformer 解码器和 dVAE 解码器组成。 Transformer 解码器生成一系列图像编码。损失函数如下:
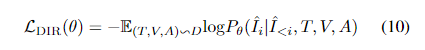
样本级建模
对于每个样本三元组(文本、图像、语音),使用其他样本随机替换一到两个输入,模型需要判断输入数据是否匹配。根据输入情况的不同,总共分为五种情况:(1)三个输入都匹配;(2)只有图像和音频匹配;(3)只有文本和音频匹配;(4)只有文本和图像匹配;(5)没有输入匹配。模型选择 [CLS] token 的输出作为文本、图像和音频的联合表示,将其输入到 FC 层,使用 Sigmoid 函数预测分数。输出结果为 $s_\theta (T, I, A) \in R^5$ ,损失函数为:
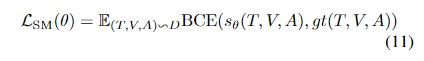
其中 $gt(T, V, A)$ 代表真实标签的 one-hot 向量。
模型实验
模型使用 Open Image 数据集作为预训练数据集,该数据集包括 641716 张带有字幕和语音的图片。论文从中选择 5000 个样本作为下游任务数据集(OpenImage-5K)。论文还使用常用的双模态数据集 Conceptual Captions 和 VG 数据集作为预训练数据集。
Faster-RCNN (使用 ResNet-152 作为主干)在 Visual Genome 数据集上进行训练。wav2vec 2.0 同样使用训练好的模型。跨模态编码器使用 12 层 Transformer 编码器(BERT)。重建的图像大小为 64 × 64 ,图像编码大小为 8 × 8。模型在 4张 Tesla V100 上训练了 100,000 步, batch size 为 10,240 (?), 使用早停策略,Adam 优化器,初始学习率为 5e-5 (?这么低的学习率可以学到东西嘛)。
模型在两种理解任务(分类和检索)和生成任务(文本生成和图像生成)上进行了实验。
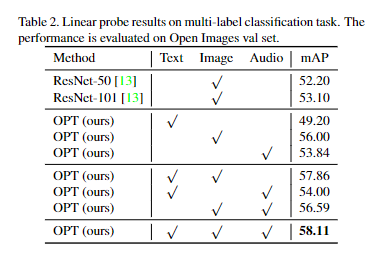
在多模态分类任务上,模型在训练时冻结预训练模型只让额外的线性层进行学习(?)。在只是用图像特征时,模型比 ResNet-50、ResNet-101 有很大优势,甚至在只是用文本和语音信息时模型也取得很好的效果。在使用多模态特征时,模型由进一步提升。每一种模态输入的增加,效果都有提升。
mAP 是目标检测模型中常用的评价指标,它的英文全称是 ( Mean Average Precision),翻译过来就是平均精确率的平均。
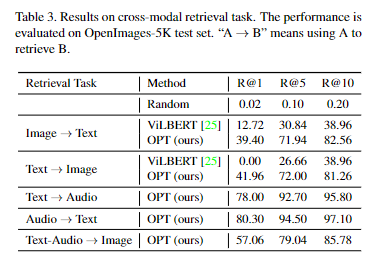
论文在 OpenImage-5K 数据上分别验证图像到文本的检索、文本到图像的检索、文本到音频的检索、音频到文本的检索、文本和音频到图像的检索。OPT 模型在图像到文本的检索、文本到图像的检索上相比 BiLBERT 有很大优势。论文发现使用附加的模态信息(音频信息)可以提高检索的效果。
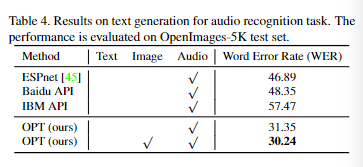
在根据音频生成文本的任务上,相比百度 API 和 IBM 的 在 Librispeech 数据集上进行预训练的Espnet 模型,OPT 模型在 OpenImage-5K 数据集上的 WER 更低。在加入图像信息后,模型效果还有进一步提升。
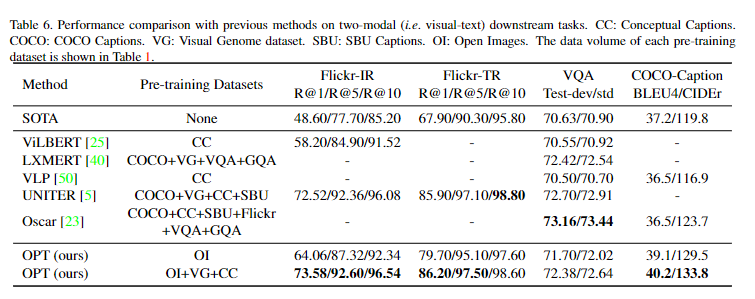
在图像和文本的下游任务上,OPT 也比 ViLBERT、 LXMERT 、VLP 、UNITER 和 Oscar 效果普遍要好。
消融实验
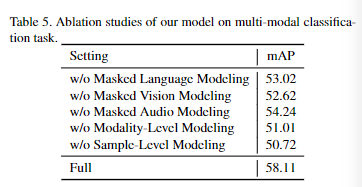
模型对预训练任务进行消融实验。去除每个预训练任务模型效果都有严重下降。其中 样本级预训练任务 会导致最大程度的性能下降(约7.4%),原因可能是这种与训练任务可以加强多个通道之间更强、更细粒度的相关性。 模态级预训练任务 会导致性能下降 7%,说明生成任务的加入有利益表征学习。 字符级预训练任务 中 MVM 对于效果影响最大,原因可能是评估任务严重依赖市局信息的多模态分类。

上图是模型的一些生成效果。第一列是真实图像,第二列是生成图像。第三例中,Image 是图像到文本的生成,Audio 是语音到文本的生成, Both 是图像和语音到文本的生成。GT 是原始文本。
由此看出模型能够生成比较准确的句子。这些结果证明了图像生成和文本生成可以集成到一个统一的框架中。需要注意的是作者首次将图像生成合并到预训练的模型。图像解码器和图像重建的与训练任务还有改进的空间。
Til next time,
gqjia
at 19:54
