
arxiv:https://arxiv.org/abs/2402.16819
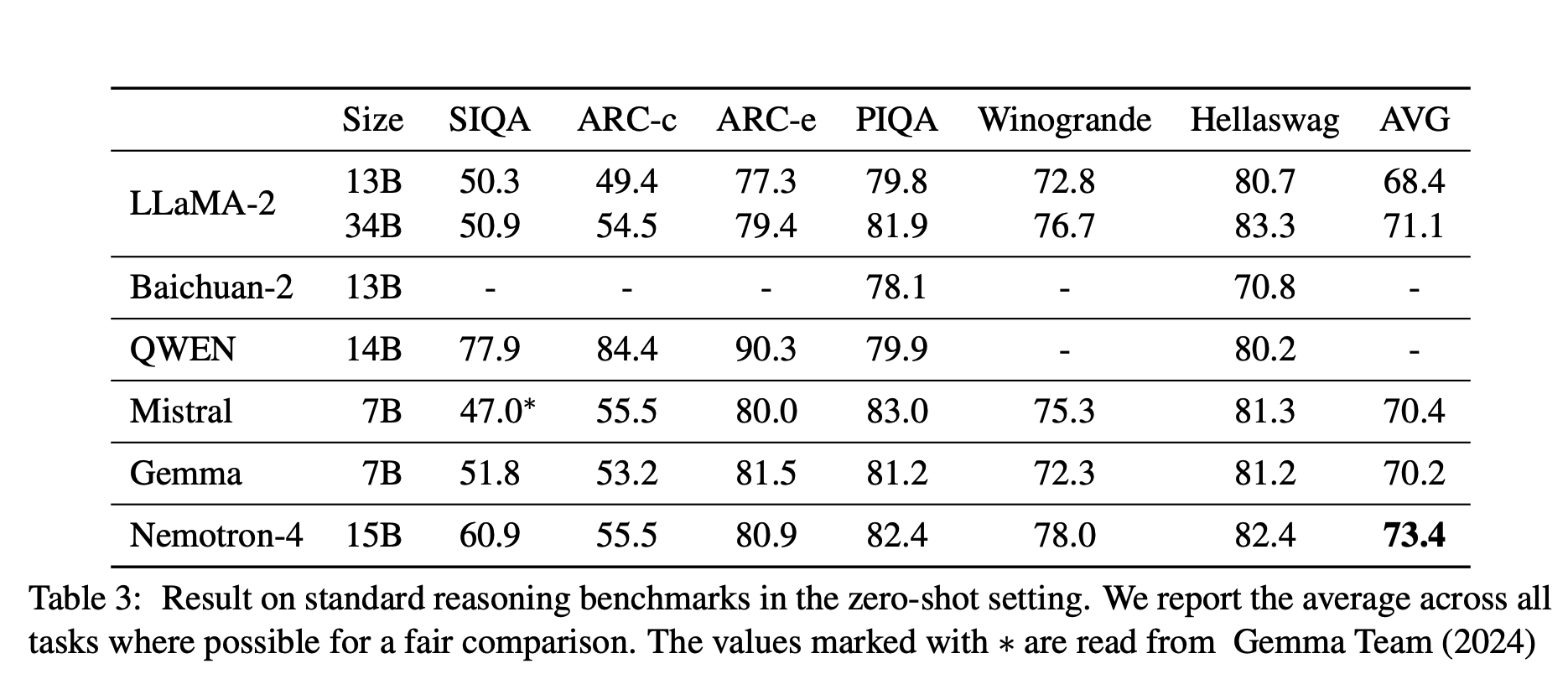
作者对比了 Qwen 14B 、Nemotron-4 15B 、Mistral 7B 、Gemma 7B 、LLaMA-2 34B 。
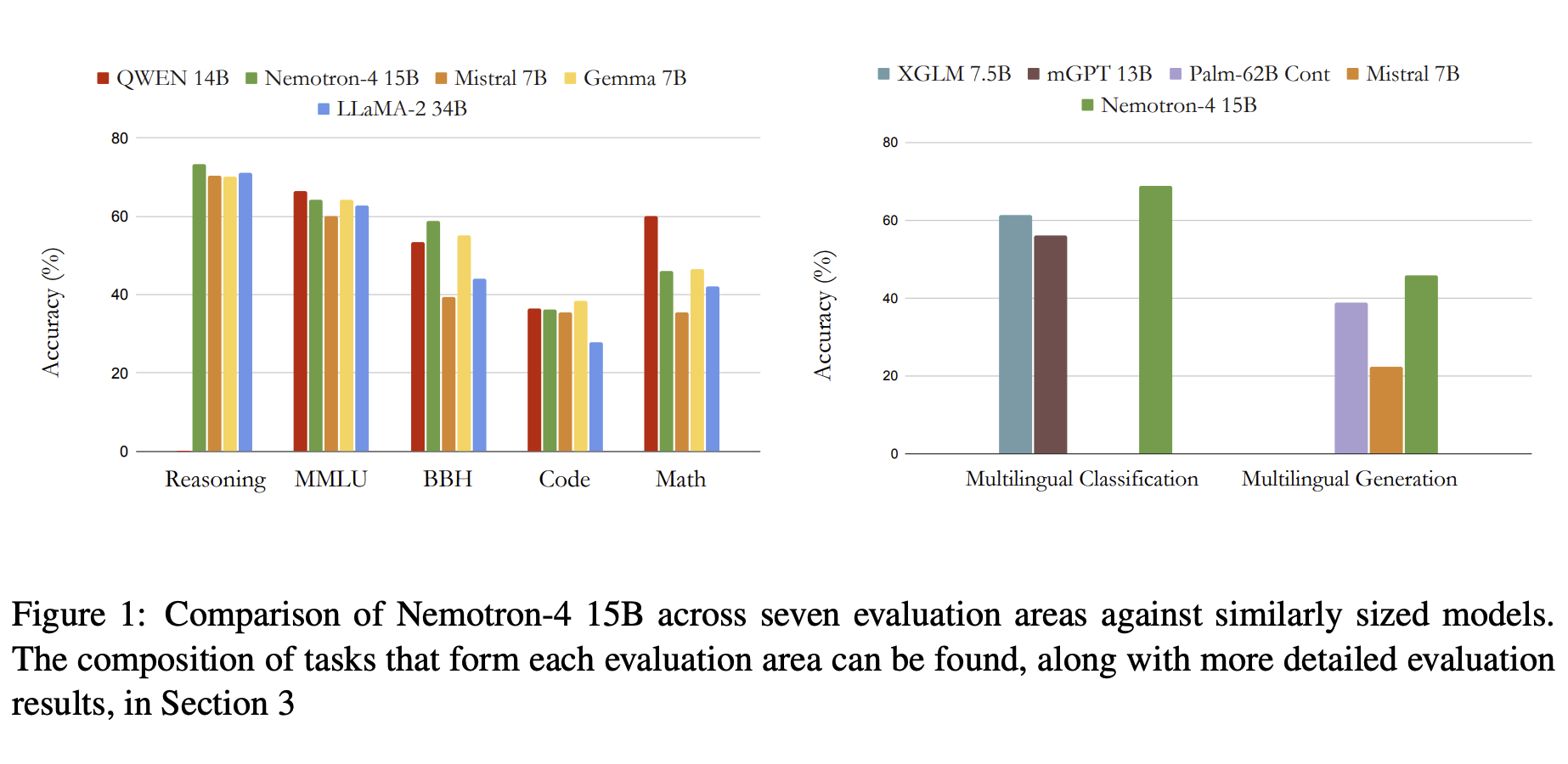
Nemotron-4 15B 优于 LLaMA-2 34B ,在英语任务上优于 Mistral 7B ,与 Qwen 14B 和 Gemma 7B 相当。
(这张图难道不是说明 Gemma 7B 的强大嘛。
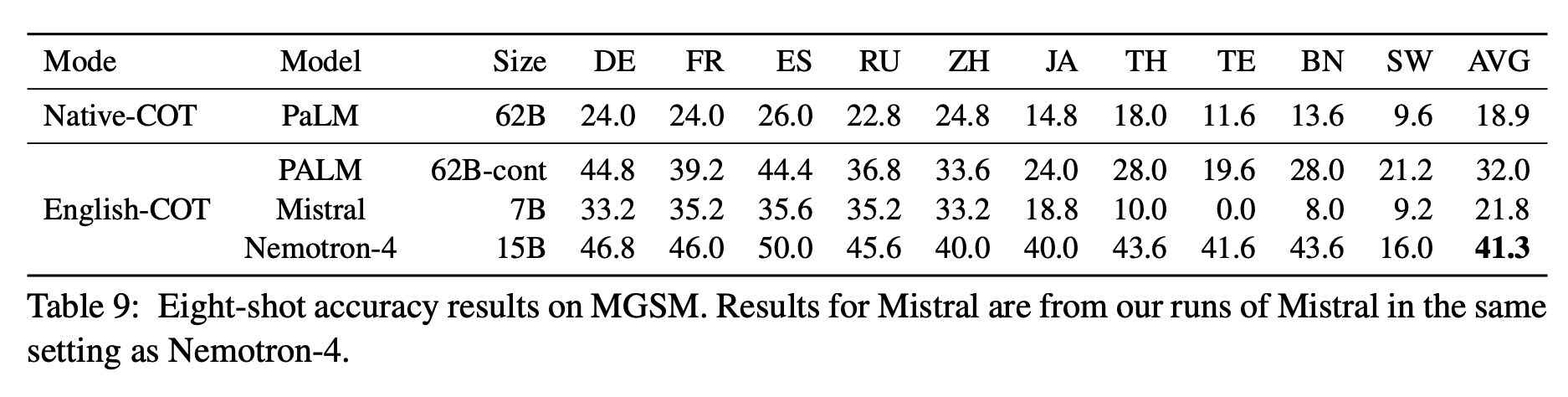
在多语言任务上,Nemotron-4 15B 优于其他模型。
模型超参数设置:

在模型结构上:
- RoPE 位置编码
- SentencePiece tokenizer
- MLP 层使用 ReLU 激活函数,没有 bias, dropout 0,untied input-output embeddings
- GQA
数据上:
训练数据包括 8T token 的多语言数据,其中 英语数据 70%、多语言数据 15%、代码数据 15%。
数据配比如下:

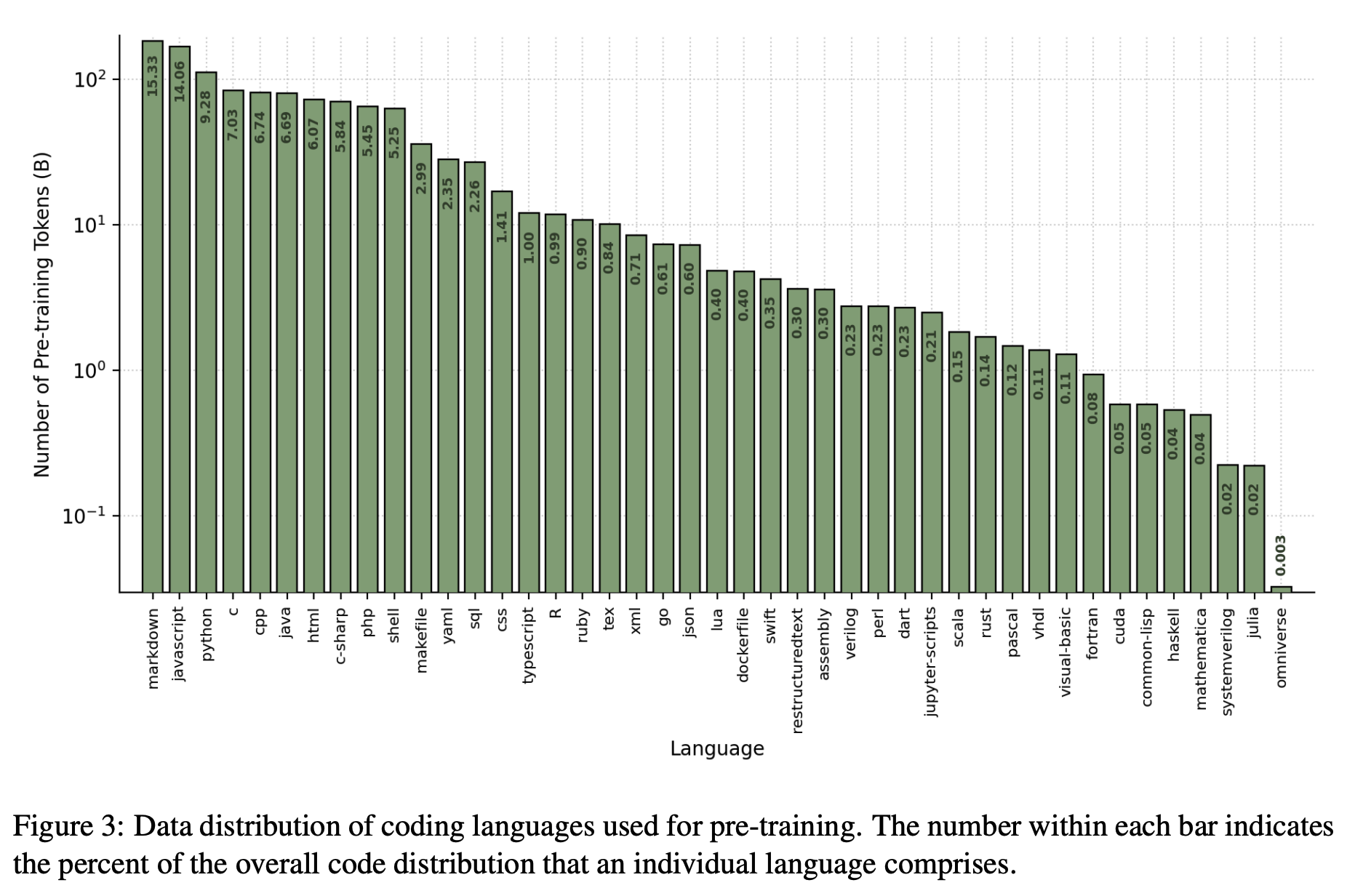
代码数据中各语言占比如下:
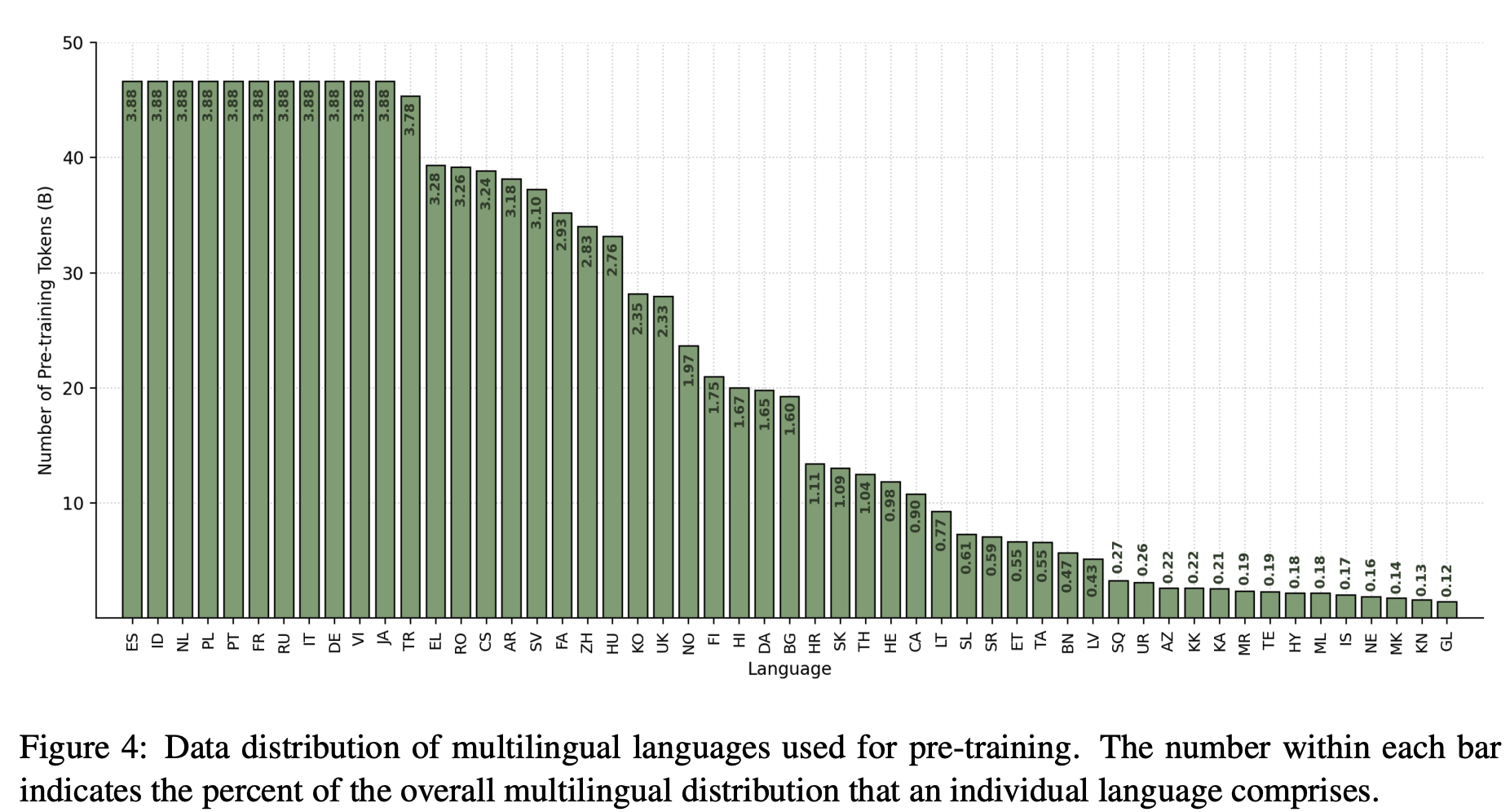
多语言数据各语言占比如下:
在数据清洗上,作者做了文档级别的精确和近似去重。除此之外还使用语言模型等对文档做了去重。
在tokenizer 上, 从 8T 数据中随机抽出一部分数据,使用 SentencePiece 训练一个 tokenizer 。训练数据中对非英语数据做了上采样。tokenizer 保留空格,将 数字 进一步拆分,使用字节级的回退 处理未知字符。最终词表大小为 256000 。
预训练配置:
使用了 384 个 DGX H100 节点,每个节点包括 8 个 Hopper 架构的 H100 80GB SXM5 GPU 。GPU 之间使用 NVLink 和 NVSwitch 连接,GPU 之间带宽为 900 GB/s。节点之间 使用 8 个 NVIDIA Mellanox 400 Gbps HDR InfiniBand HCA 进行节点间通信。
(……
训练时使用 8 路 张量并行和数据并行,还使用了分布式优化器将优化器状态分片到数据并行的副本上。随着 batch size 的增加,数据并行也从 96 增加到 384。
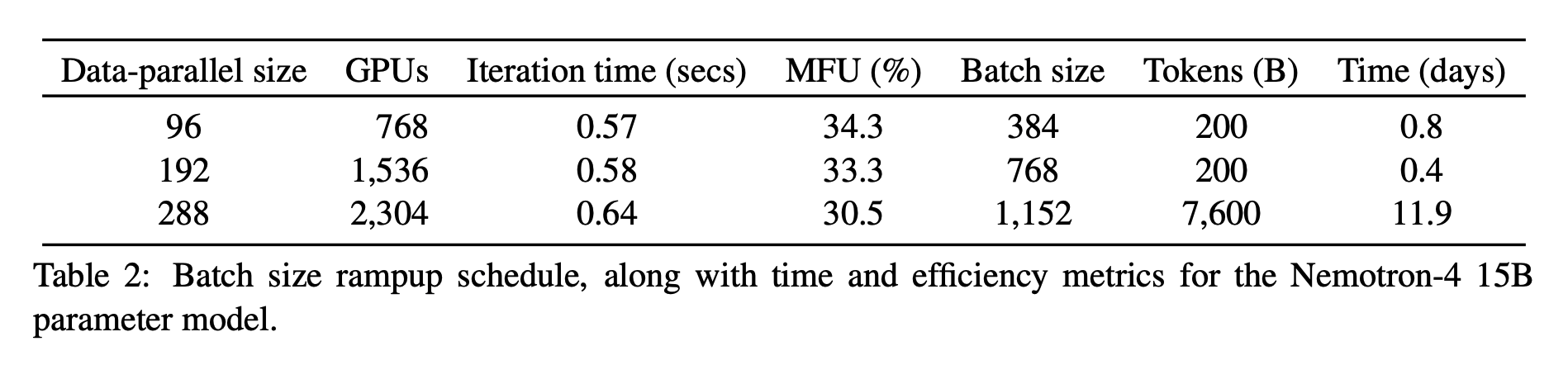
训练耗时13天。
在 8T 数据预训练完成后,又做了继续预训练。数据包括两种,一种是之前数据中高质量的数据,一种是 benchmark-style alignment examples 。
(…….
zero-shot 下的 reasoning benchmarks 结果:
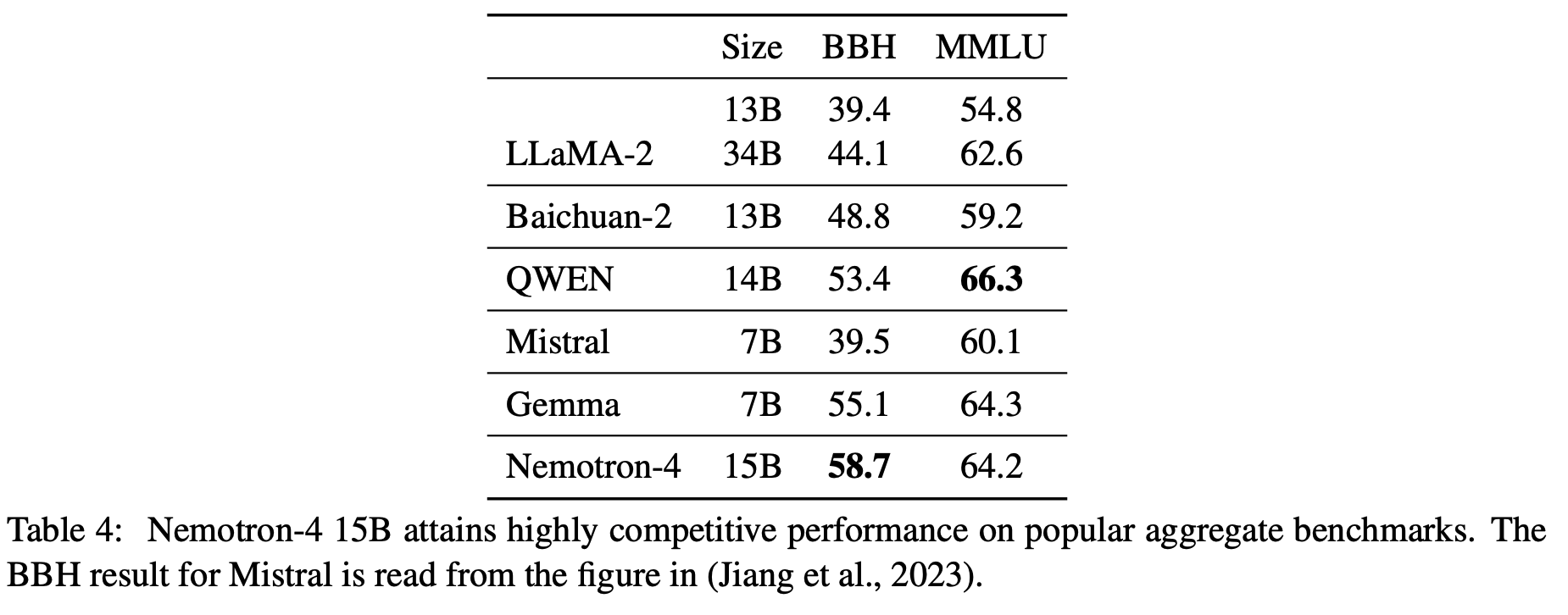
BBH 和 MMLU上的效果:
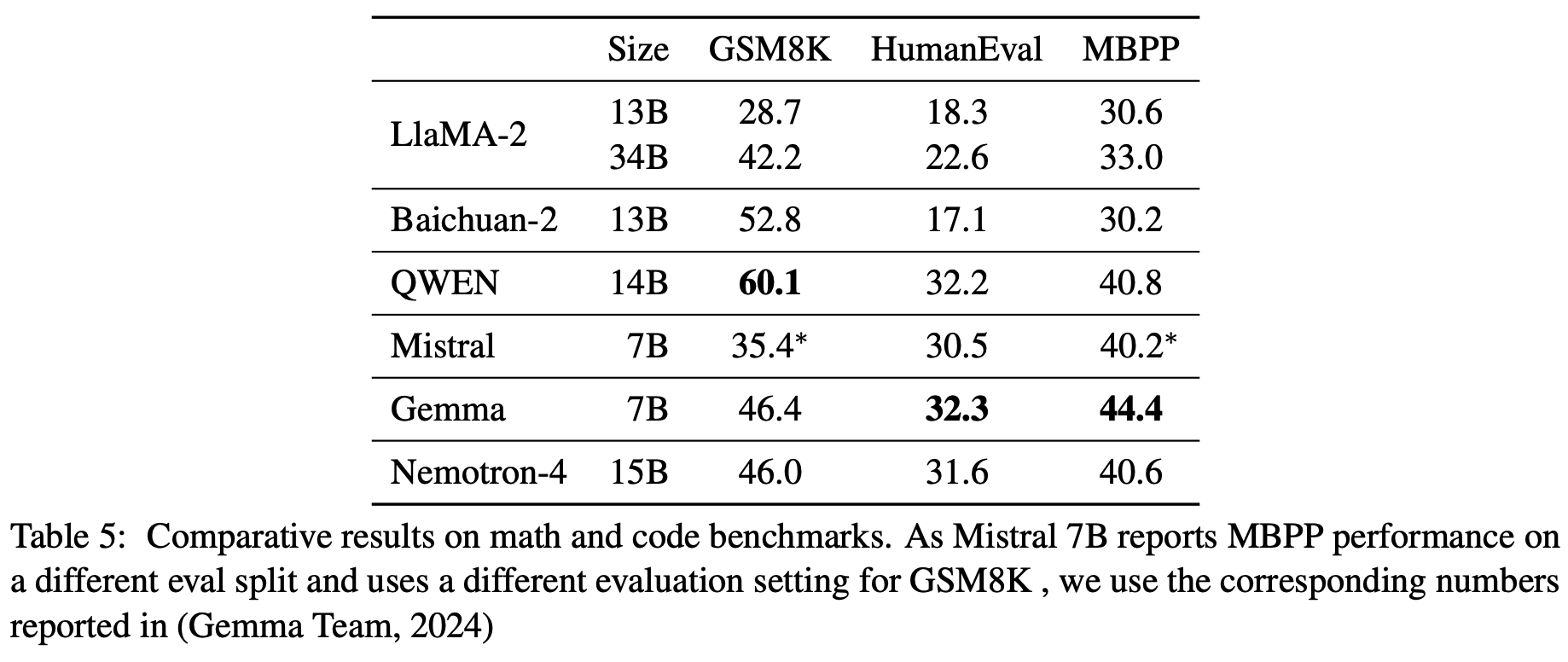
数学和代码上的效果:
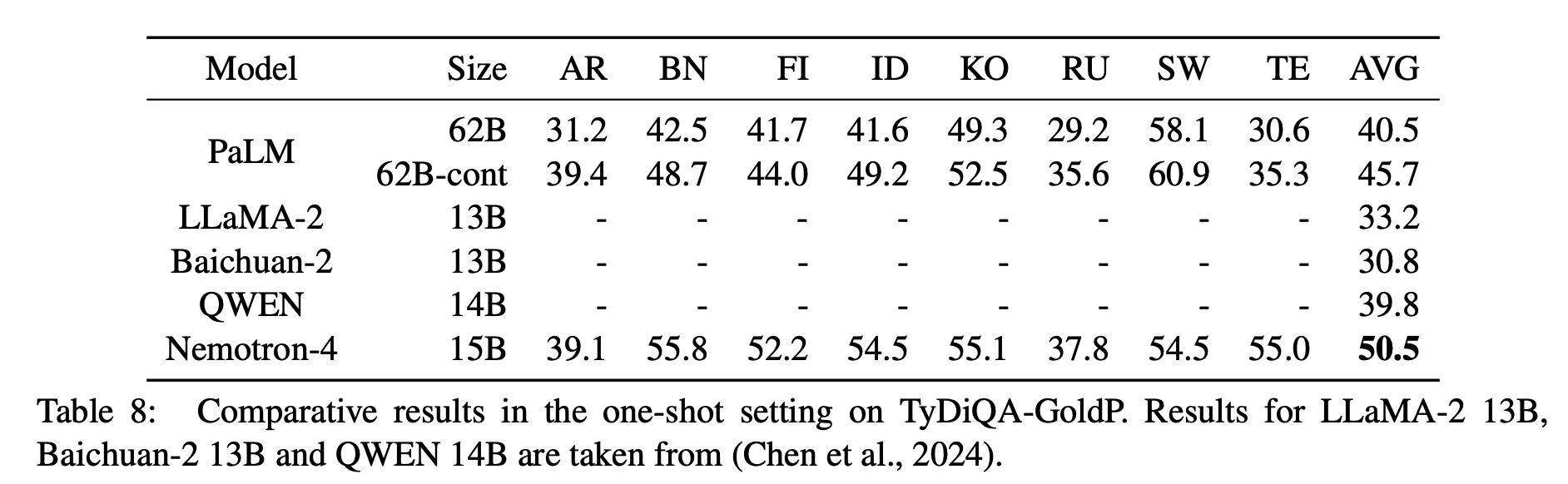
在多语言的两个任务上:
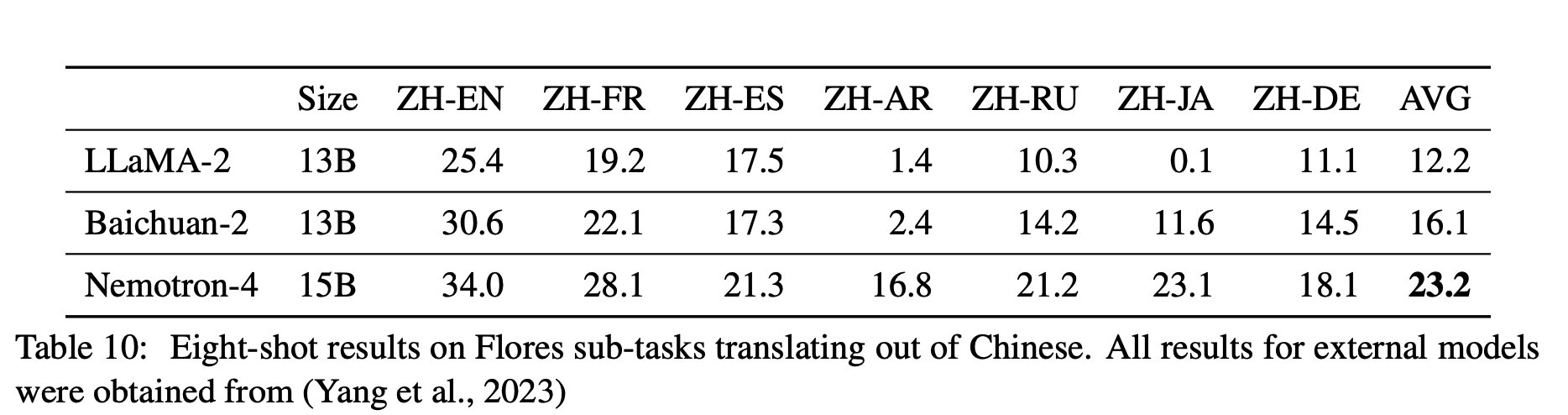
翻译任务:
Til next time,
gqjia
at 00:00
