
arxiv: https://arxiv.org/abs/2404.07143
kimi:https://papers.cool/arxiv/2404.07143
论文提出了 infini-attention 的注意力技术,可以在有限内存和计算能力的条件下,将 LLMs 扩展到无限输入长度。 infini-attention 将一种压缩式记忆方法引入到传统注意力机制中,并且在单个 Transformers 块中构建了 masked local attention 和 long-term linear attention 。
这个方法对标准注意力做了很小的改动,支持即插即用的继续预训练以及长上下文适应。还能够使得 Transformer 通过流式处理极长的输入,在有限的内存和训练资源下无限扩展上下文。
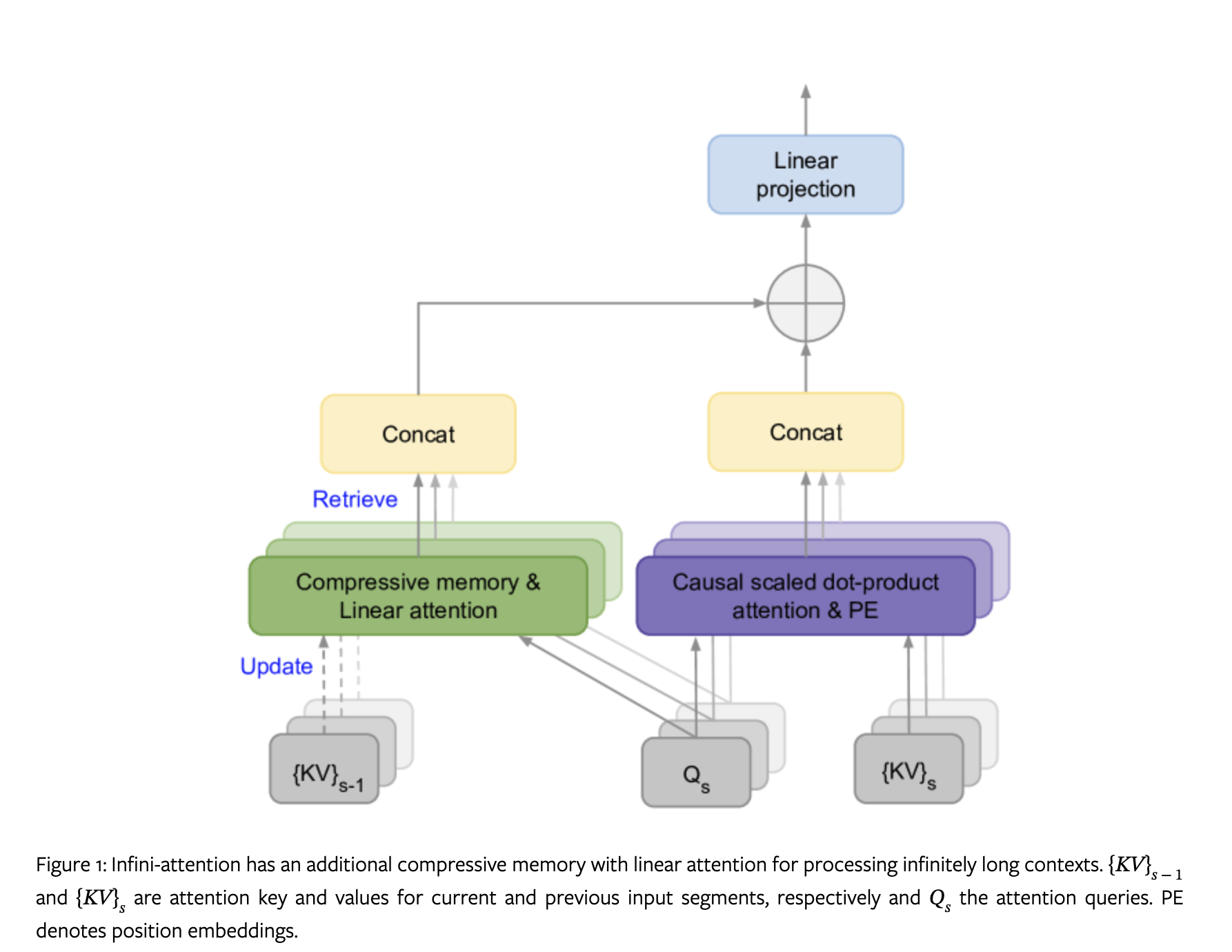
可以看到相比传统注意力,infini-attention 相当于外加了一个检索的模块来保存长距离的信息,而局部的信息仍然通过传统点积注意力计算。
infini-attention 的计算流程如下:
- 将输入拆分成预定长度的片段,逐个片段进行计算
- 计算当前片段的 attention
- 使用 Q 与之前片段保存的信息 M 进行计算,得到全局的 attention
- 将局部的 attention 与全局的 attention 通过一个门控进行整合
- 使用当前片段的 K V 更新全局信息 M,在下个片段继续参与计算
retrieve部分, $A_{mem} \in \mathbb{R}{s-1}$ 是使用 $Q \in \mathbb{R}^{N \times d{key}}$ 从 $M_{s-1} \in \mathbb{R}^{d_{key} \times d_{value}}$ 检索: \(A_{mem} = \frac{\sigma(Q)M_{s-1}}{\sigma(Q)Z_{s-1}}\) 其中 $\sigma$ 是激活函数 ELU + 1, $z_{s-1} \in \mathbb{R}^{d_{value}}$ 是一个归一化项。
$M$ 以及 归一化项的更新计算如下: \(M_s \leftarrow M_{s-1} + \sigma(K)^T V\)
\[Z_s \leftarrow Z_{s-1} + \sum_{t=1}^N \sigma(K_t)\]可以看出全局信息的计算并不是二次复杂度。
受到 delta 规则的启发,作者在更新 M 时要减去原本包括的部分: \(M_s \leftarrow M_{s-1} + \sigma(K)^T \left( V - \frac{\sigma(K) M_{s-1}}{\sigma(K) Z_{s-1}} \right)\) 最终将两种信息通过门控进行整合: \(A = \text{sigmoid}(\beta) \odot A_{\text{mem}} + (1 - \text{sigmoid}(\beta)) \odot A_{\text{dot}}\) 至于 multi-head Infini-attention 则与 MHA 一致: \(O = [A^1, \ldots, A^H] W_O\)
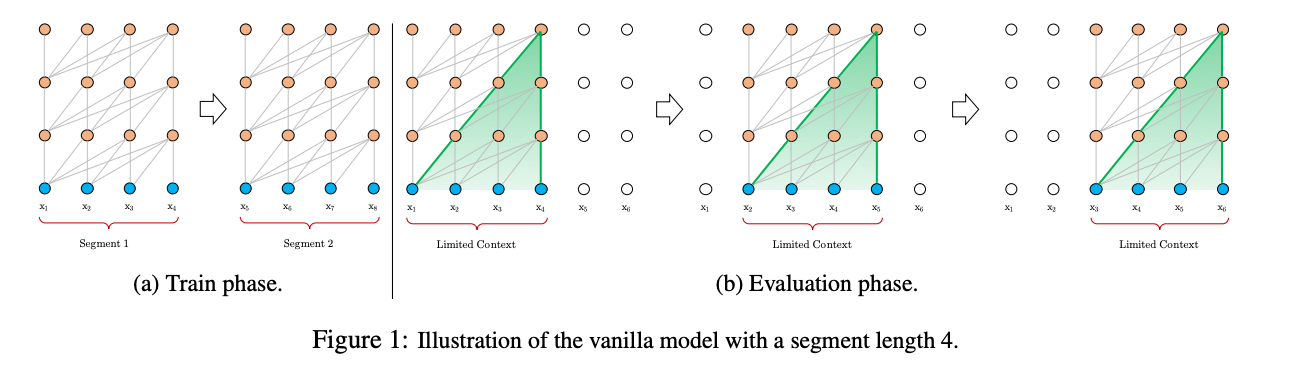
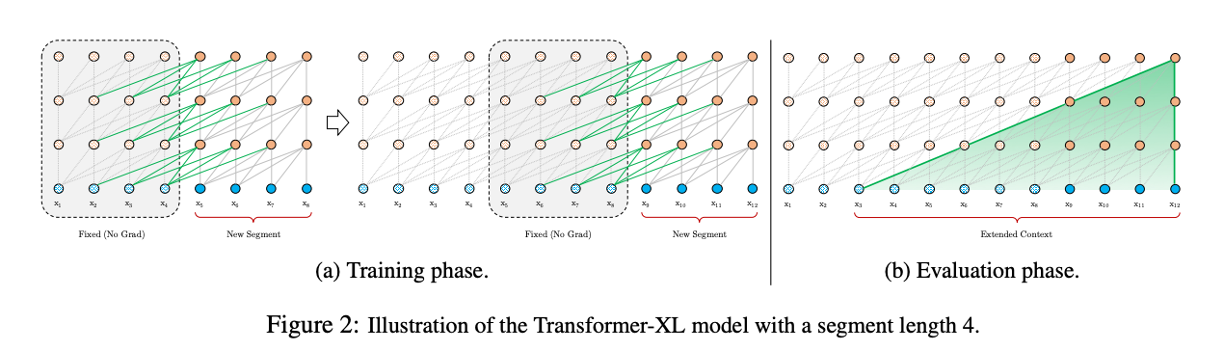
Transformer-XL 是在拆分片段后,保存前一个片段的信息,将其加入到下一个片段的计算中(上一片段不计算梯度)。可以处理的文本长度取决于 片段以及 模型深度。
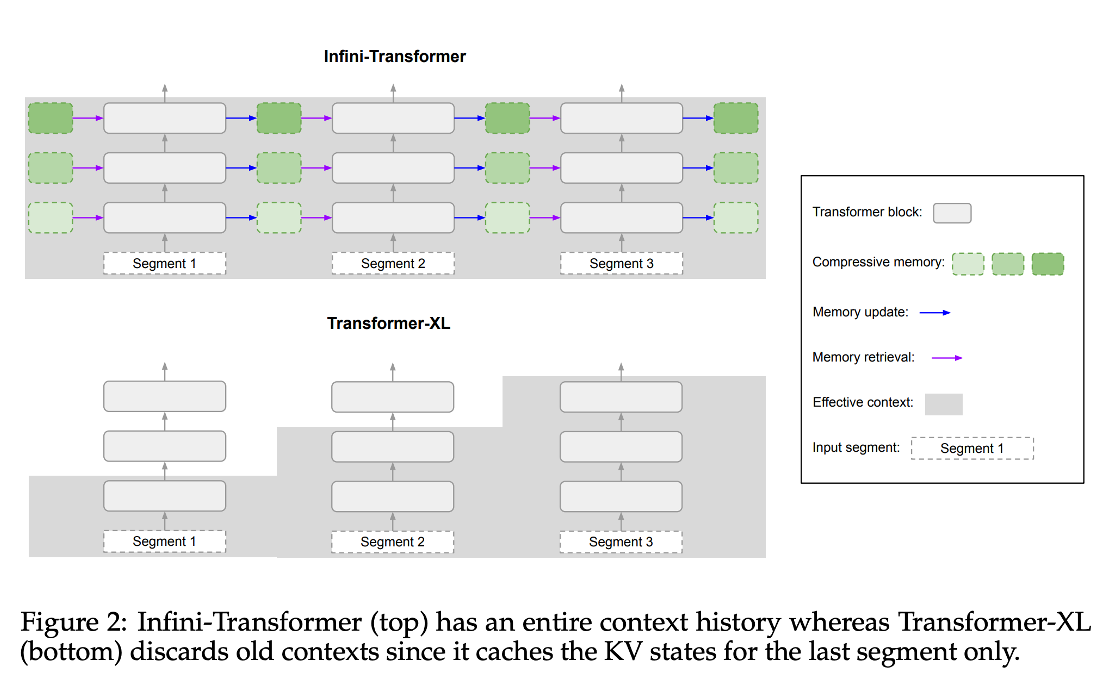
相比较而言,infini-attention 可以注意到完整的上下文信息。
其他模型的做法如下:
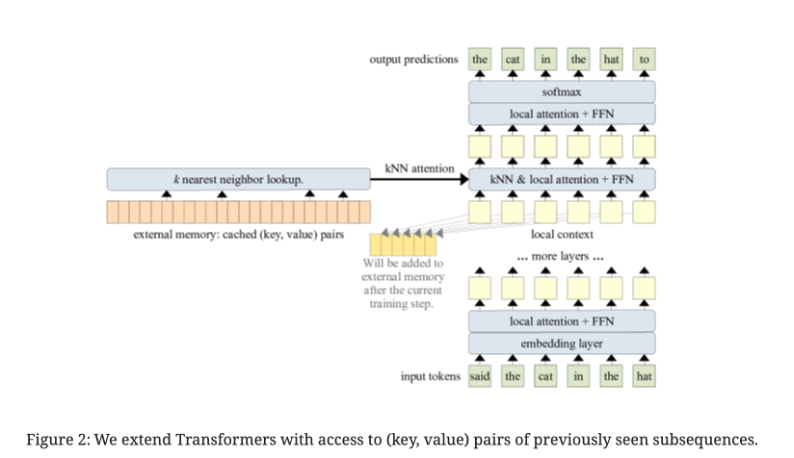
memorizing transformer 只会对一层做修改,将 K V 对保存起来,通过 kNN 检索,再与 local atttention 整合。
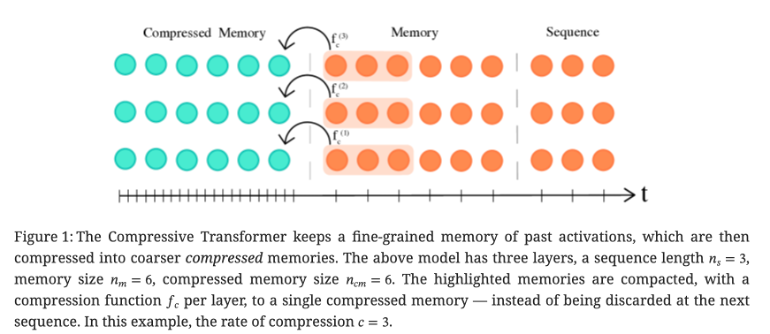
compressive transformer 则是在 Transformer-XL 的基础上,使用压缩算法将之前片段的信息压缩保存到 compressed memory 中。
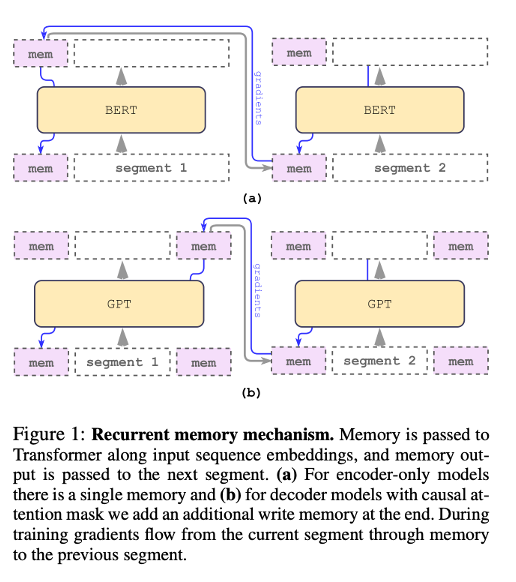
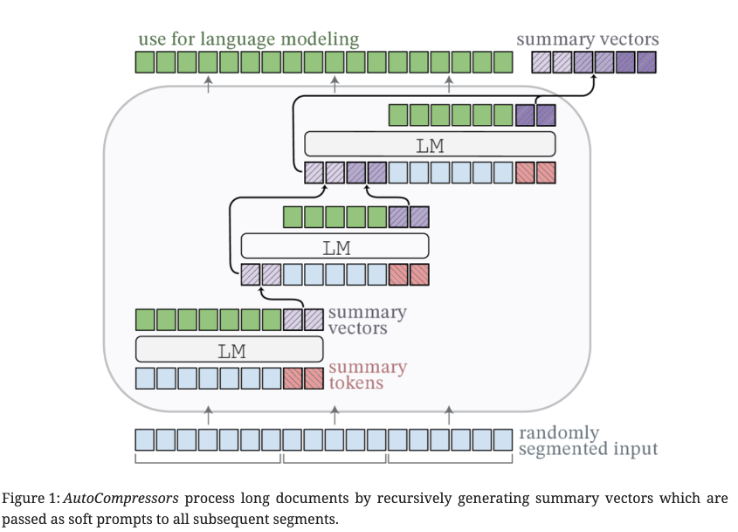
RMT 和 AutoCompressors 则是使用了 recurrent memory mechanism ,将部分输入设置为 memory (使用特殊 token初始化,生成摘要向量 ),一个片段计算结束后传递给下一个片段(soft prompt)。
这几种模型的对比如下:
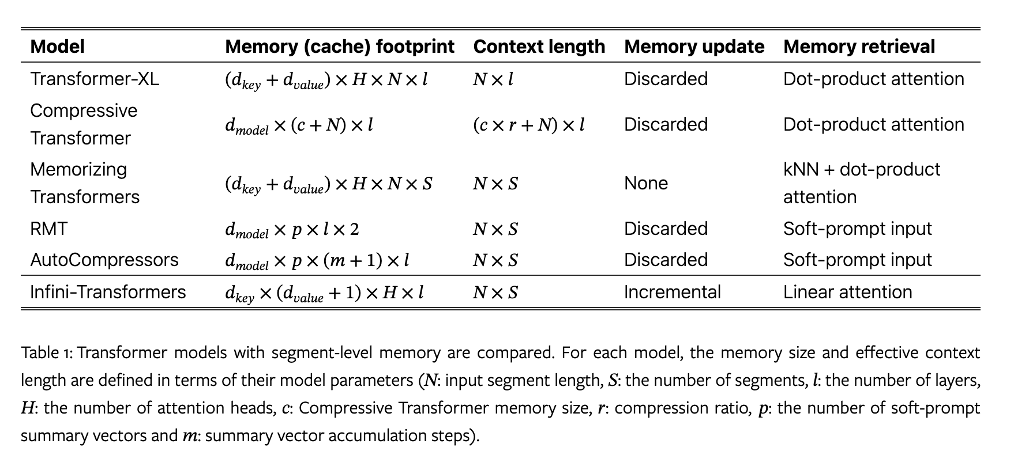
其中,N:输入片段长度;S:片段数量;l:层数;H:注意力头数;c:压缩Transformer内存大小;r:压缩比;p:soft-prompt 摘要数量;m:摘要向量累计步数。
Infini-Transformer 在单层的每个头部中存储压缩上下文的内存复杂度为 $d_{key} \times d_{value} + d_{key}$ ,而对于其他模型,随着序列维度的增长,复杂度也会增长。Transformer-XL、Compressive Transformer 、Memorizing Transformers 的复杂度与 N 有关,memory complexity 依赖于 缓存大小,而RMT 和 AutoCompressors 依赖于 soft-prompt 大小。
在预训练任务上,所有模型设置 12 layers 、 8 attention heads 每个维度为 128 、FFNs hidden layer 4096。infini-attention 片段长度设置为2048,在所有注意力层都做了修改,训练序列长度 32768;RMT 多次实验,在 8196 长度、100 summary vectors 取得最好的效果。
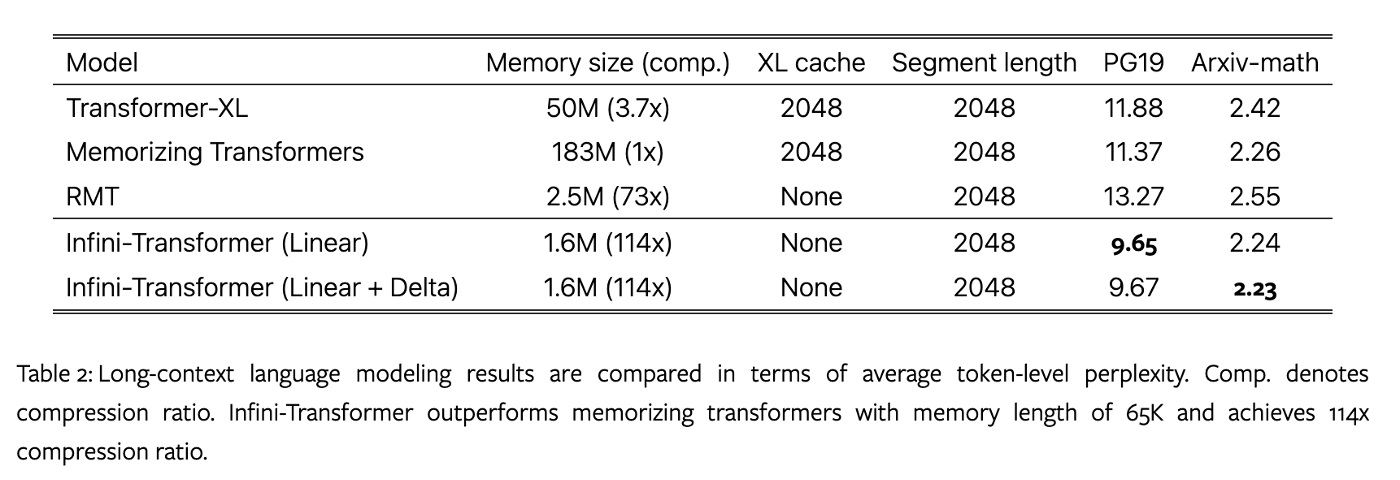
Infini-Transformer 在保持比 Memorizing Transformers 模型少 114 倍的内存参数的同时,性能超过了 Transformer-XL 和 Memorizing Transformers 基线。将训练长度从 32k 增加到 100k,在 Arxiv-math 数据集上训练,PPL 降低到 2.21 和 2.20。
Infini-Transformer 每一层中所有注意力头的压缩记忆的门控分数可视化如下:
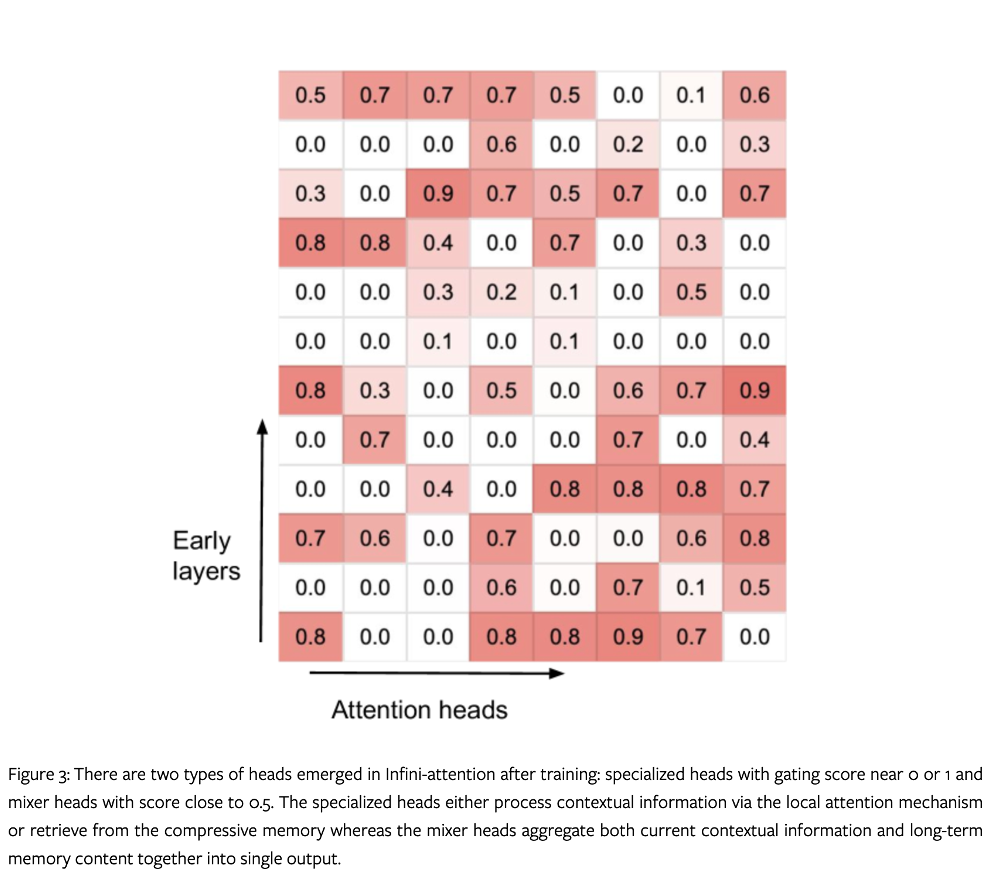
在 Infini-attention 训练后出现了两种类型的头部:专业头部的门控分数接近 0 或 1,以及混合头部的分数接近 0.5。专门头要么通过局部注意力计算处理上下文信息,要么从压缩记忆中检索,而混合头则将当前的上下文信息和长期记忆内容一起聚合到一个输出中。论文中还发现,每一层至少有一个短程头,允许输入信号向前传播直到输出层。作者还观察到在前向计算过程中长期和短期内容检索存在交错。
作者进行了轻量级的继续预训练,训练数据采用PG19 、 Arxiv-math 和 C4 文本 语料,训练长度超过 4k,片段长度设置为 2k。
作者设置两个任务进行测试:
1M passkey retrieval benchmark:密钥任务在一长段文本中隐藏一个随机数,交由模型输出。通过多次重复一个文本块扩大文本长度。
在原本的研究中,一个 8B LLaMA 模型在使用位置插值对相同的 32K 长度输入进行微调后,可以解决长达 32K 的任务。这里作者先进行一个继续预训练,使用 1B 大小的 LLM 进行训练,使用 infini-attention 代替 MHA,训练长度 4k,batch size 64 训练了 30k 步。然后对 5K 长度的输入进行微调,以测试在 1M 长度范围内的效果。
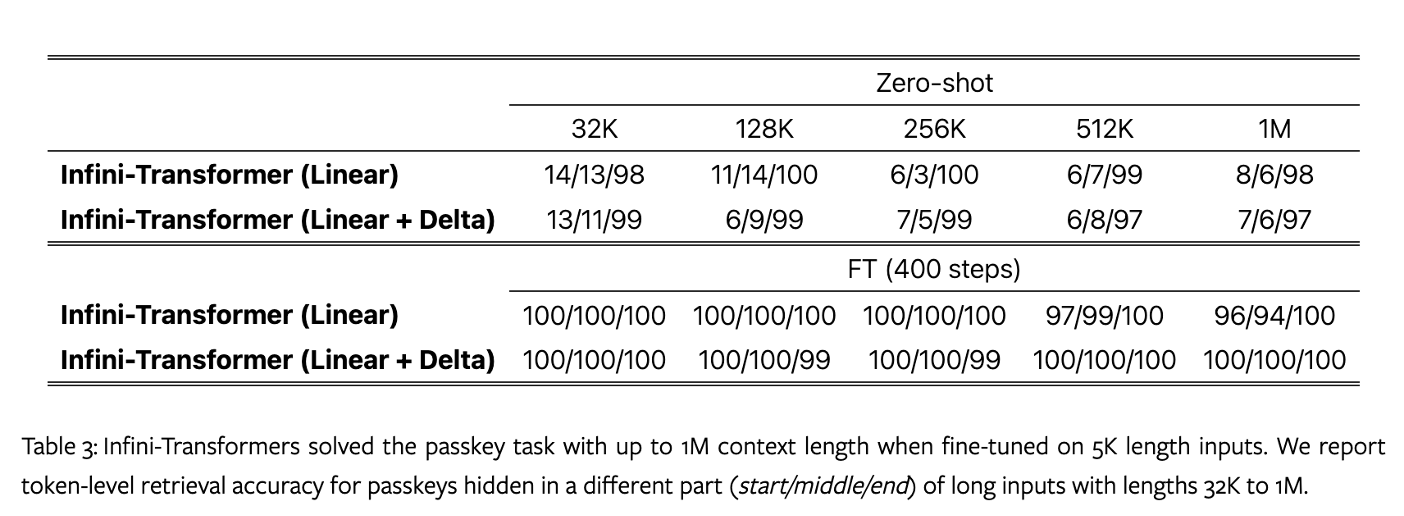
可以看出在用5k长度微调后,解决了 1M 长度的任务。
500K length book summarization (BookSum):任务目标是生成整本书的摘要。
作者使用8B 的 LLM 继续预训练,上下文长度 8k,训练 30k 步。将输入长度设置为 32k 进行微调, 增加到 500k 进行评估,推理时 temperature 0.5,top_p 0.95。
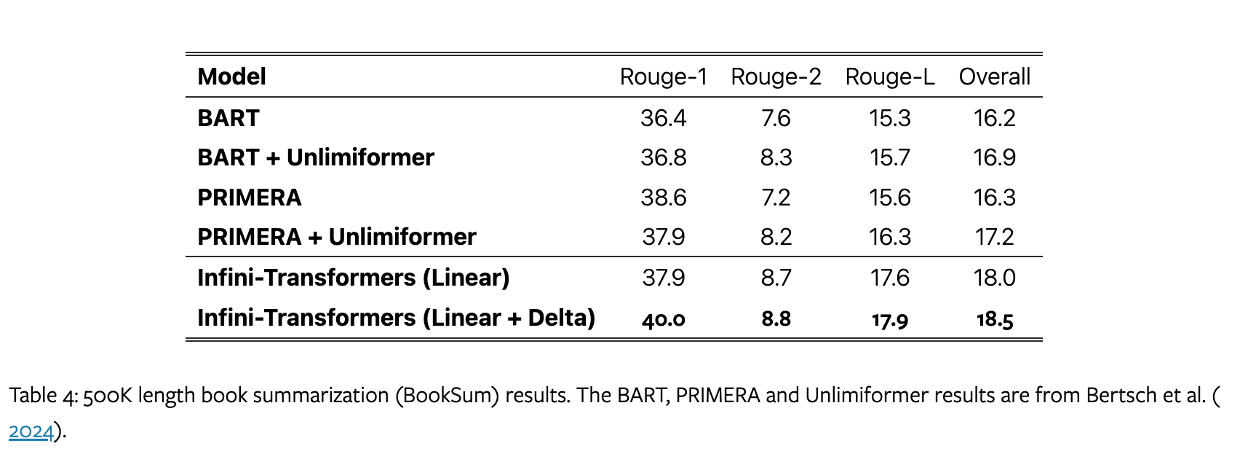
模型超越了以前的最佳结果,并通过处理整本书的文本,在 BookSum 上实现了新的 SOTA。
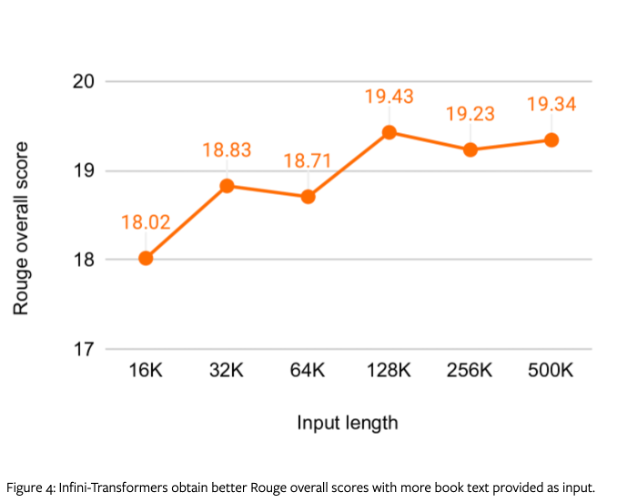
作者还展示了在验证集上 rouge 分数,在使用更多文本长度输入时,infini-transformer 的 rouge 分数时提高的。
Til next time,
gqjia
at 00:00
