

核心问题:LLMs虽然能生成上下文连贯的响应,但受固定上下文窗口限制,无法在长期、跨会话的多轮交流中维持信息一致性。这导致 AI Agent 易出现”重复提问、回复矛盾”等问题,严重破坏用户体验与信任。
人类记忆能够动态整合信息,支持长期连贯交流,而LLMs缺乏对对话信息的长期结构化记忆能力。
现有方案的不足:
- 扩展上下文长度(如GPT-4 128K、Gemini 10M token):仅”延迟”了遗忘问题,未解决核心痛点;
- 检索增强生成(RAG):依赖静态文本分块,难以捕捉动态语义关联;
- 全上下文输入:导致延迟极高、Token成本陡增,无法满足生产级需求;
1 Mem0 架构设计
1.1 Mem0 基础记忆架构
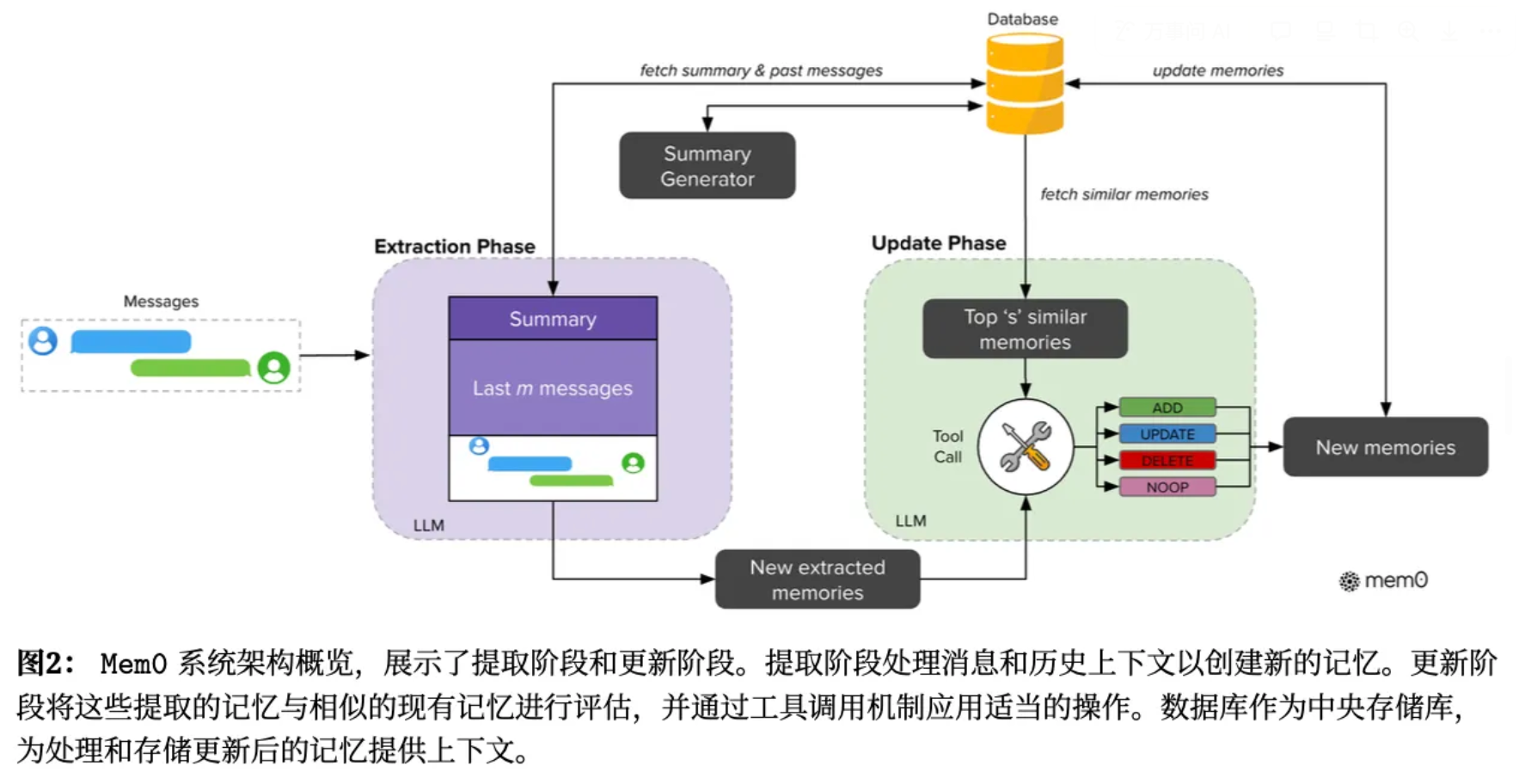
核心思想是通过”轻量化上下文提取关键记忆 + 相似记忆检索 + LLM智能更新”的流程。
两阶段架构:
- 提取阶段(Extraction Phase):通过 LLM 分析1)对话摘要(全局语义总结,通过一个异步摘要模块,定期刷新对话摘要)和2)最近m条消息(细粒度时序内容),提取关键信息作为候选事实
- 更新阶段(Update Phase):1)检索相似记忆(使用每个候选事实从向量数据库中获取最相似的 s 条历史记忆)。2)LLM智能决策:通过工具调用机制,执行4种操作(ADD:新增无相似的记忆;UPDATE:补充/替换可完善的记忆;DELETE:移除矛盾的记忆;NOOP:记忆已存在/无关,不操作)。3)持久化存储:更新后的记忆回写到数据库
具体实现:系统配置为 m= 10 条先前消息用于上下文参考,以及 s= 10 条相似记忆用于比较分析。所有语言模型操作均使用GPT-4o-mini 作为推理引擎。向量数据库采用稠密嵌入。
1.2 Mem0g 图增强记忆
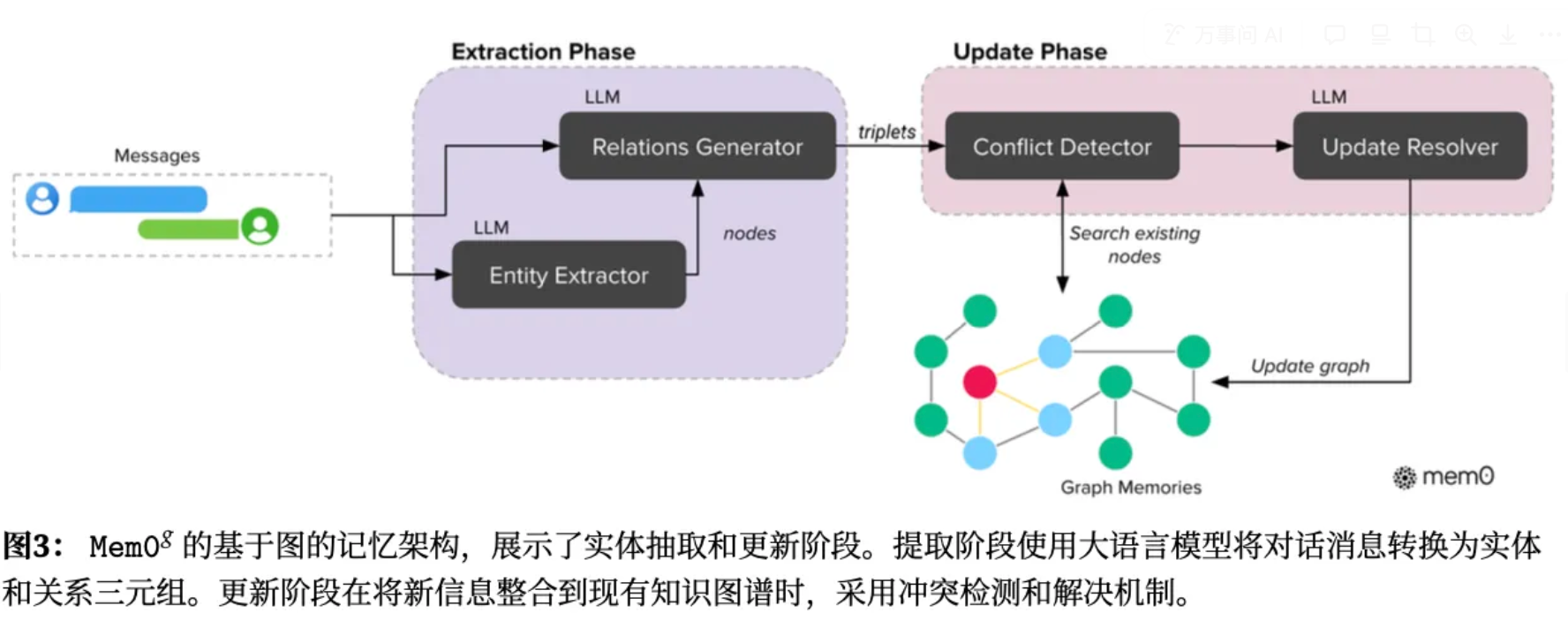
核心改进:在Mem0基础上引入图结构记忆表示,更好地捕捉对话元素间的复杂关系。
记忆被表示为一个有向标记图G,其中:
- 节点V:代表实体(如Alice, San_Francisco)
- 边E:代表实体间关系(如 lives_in 居住在)
- 标签L:分配语义类型给节点(如Alice-Person, San_Francisco-City)
每个实体节点 $v \in V$ 包括三个部分:
- 一个对实体进行分类的实体类型分类,比如人物、地点、事件
- 一个捕捉实体语义的嵌入向量
- 包含创建时间的戳的元数据
抽取过程包括两阶段流水线:
- 一个实体抽取器处理输入文本,识别一组实体及其对应的类型。包括包括人物、地点、对象、概念、事件以及值得在记忆图中表示的属性。
- 一个关系生成器推导实体之间的连接,建立关系三元组。对于每个潜在的实体对,关系生成器评估是否有意义的关系存在,如果有就选择一个合适的标签进行分类。在整合信息时,对于每个新的三元组,计算得到源实体和目标实体的嵌入向量,搜索语义相似度超过阈值的现有节点。根据检索情况新增节点。mem0g 还实现了一个冲突检测机制,在获取到新知识时,识别可能有的冲突关系。一个基于大模型的更新解析器,决定某些关系是否应该被废弃,将其标记为无效(不是物理删除),以实现时序推理。
记忆检索时采用了两种策略:
- 以实体为中心的方法:首先识别 query 中的关键实体,然后利用语义相似性在知识图谱中定位对应的节点。获取到这些节点的传入传出关系,构建一个包含相关上下文信息的子图。
- 语义三元组的方法:将 query 编码为一个稠密嵌入向量,与知识图谱中每个关系三元组的文本编码进行匹配(计算与所有可用三元组之间细粒度相似度分数),仅返回超过阈值的结果,并按照相似度阈值降序排列。
具体实现:使用Neo4j 作为底层图数据库。基于 LLM 的提取器和更新模块利用 GPT-4o-mini 的函数调用能力。
Til next time,
gqjia
at 00:00
