
核心问题:主流大语言模型受限于其固定长度的上下文窗口,无法有效处理长文档分析或需要长期记忆的多轮对话任务。
现有方案的局限:
- 直接扩展上下文长度:基于 Transformer 架构的注意力机制导致计算开销呈二次方增长,且研究显示模型难以有效利用超长的上下文。
- 简单的检索增强(RAG):传统方法在上下文窗口满时进行被动或简单的信息替换/压缩,可能导致关键信息丢失。
作者研究目标:在继续使用固定上下文模型的前提下,提供一种无限上下文的“假象”。
1 MemGPT 核心思想:操作系统类比
MemGPT 的设计灵感来源于操作系统的分层内存体系和虚拟内存概念。
核心类比:
- LLM的上下文窗口 类比为 主内存。
- 外部存储(数据库) 类比为 磁盘。
- MemGPT系统自身 类比为 操作系统,负责在“主内存”和“磁盘”之间智能地换入/换出数据。
实现机制:利用LLM的函数调用能力,使模型能够自主地决定何时从外部存储检索相关信息到上下文(read),以及何时将上下文中的重要信息保存到外部存储(write),从而实现动态的上下文管理。
2 MemGPT 系统架构
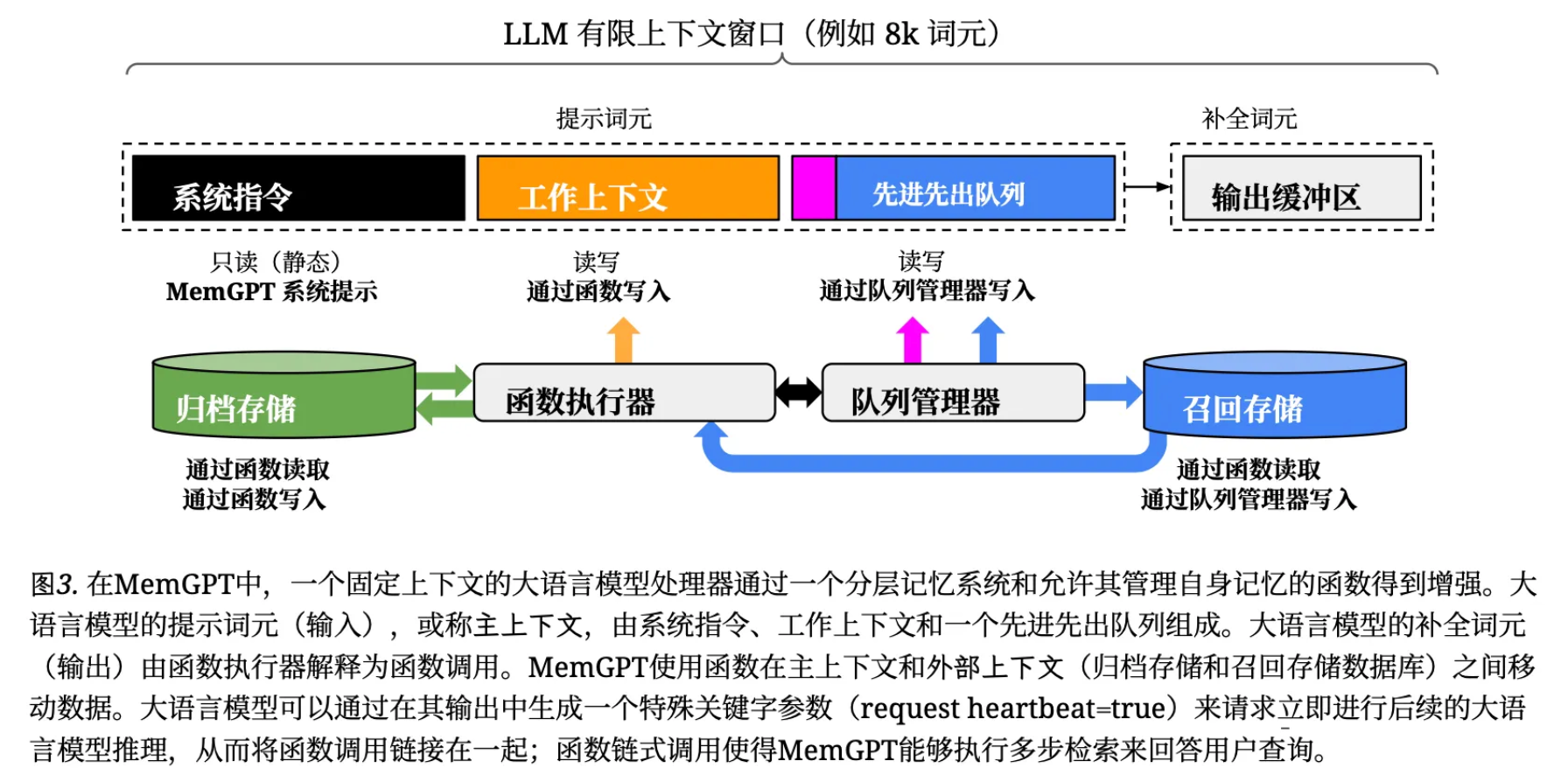
MemGPT 受操作系统启发的多级内存架构界定了两种主要内存类型:主上下文(类似于主内存/物理内存/RAM)和外部上下文(类似于磁盘内存/磁盘存储)。
MemGPT 系统主要由以下几个组件构成:
- 主上下文:即LLM的提示词输入,分为三部分
- 系统指令:静态、只读,包括 MemGPT 控制流程、不同记忆层级预期用途的说明,以及如何使用 MemGPT 函数的指令。
- 工作上下文:固定大小的可读写文本块,用于存储当前任务的核心信息(如对话中的用户关键事实)。只能通过 MemGPT 函数调用写入,在对话场景中用于存储关键事实、偏好以及关于用户和 Agent 所用角色的其他信息。
- FIFO 队列:存储最近的对话/交互消息滚动历史,包括 Agent 与用户之间的消息,以及系统消息(例如内存警告)与函数调用输入输出。先进先出队列的第一个索引存储一条系统消息,其中包含已从队列中逐出消息的递归摘要。
- 队列管理器:
- 负责管理流出FIFO队列和召回存储中的消息。当系统接收到新的消息时,队列消息管理器会将传入的消息追加到先进先出队列中,拼接提示词并触发 LLM 推理,生成 LLM 输出(即补充词元)。队列管理器会将传入的消息和生成的大语言模型输出都写入召回存储(即 MemGPT 消息数据库),当通过 MemGPT 函数调用检索召回存储中的消息时,队列管理器会将其追加到队列的末尾,以便将其重新插入到 LLM 的上下文窗口中。
- 队列管理器还负责通过队列驱逐策略控制上下文窗口:
- 当上下文即将溢出时(例如上下文窗口的70%),向LLM发出警告(一个‘内存压力’的警告),以便大语言模型能够使用 MemGPT 函数将先进先出队列中包含的重要信息存储到工作上下文或者归档存储(一个存储任意长度文本对象的读写数据库)中。
- 当真正溢出时(当提示词超过‘清空词元计数’时,例如,上下文窗口的100%),队列管理器会清空队列以释放上下文窗口中的空间:自动移出特定数量的消息,并使用现有的递归摘要和被逐出的消息生成一个新的递归摘要。一旦队列被清空,被逐出的消息就不再处于上下文中,大语言模型无法立即查看,但他们会无限期的存储在召回存储中,并可通过 MemGPT 函数调用进行读取。
- 函数执行器(处理补充词 completion tokens):MemGPT 通过大模型生成的函数调用,协调主上下文和外部上下文之间的数据移动,实现自我主导的 内存编辑和检索(根据当前上下文自主更新和搜索其自身的记忆(比如可以决定在历史对话变得过长时,在上下文之间移动项目)并修改其主上下文)。MemGPT 在系统指令中提供明确的指令指导大模型与 MemGPT 记忆系统进行交互,这些指令主要包括两部分:1)对内存层次机构及其各自用途的详细描述;2)系统可以调用的访问和修改记忆的函数模式和自然语言描述。在每个推理周期内,LLM 会将主上下文作为输入,生成一个输出字符串。MemGPT 会解析该字符串,确保其正确性,如果解析器验证函数参数无误,则执行该函数。如果发生运行时错误,会由 MemGPT 向处理器发出警告提示,指导其内部内存管理决策。此外在内存检索机制在设计上充分考虑了这些令牌的约束,实现了分页,防止检索调用超出上下文窗口。
- 事件驱动控制流:LLM 的推理由事件触发(如用户消息、系统警报、定时事件),而非简单的轮询。事件是 MemGPT 的广义输入,可以包括用户消息(在聊天应用中)、系统消息(例如,主上下文容量警告)、用户交互(例如,用户刚刚登录的提醒,或他们完成文档上传的提醒),以及按固定计划运行的定时事件(允许 MemGPT 在无需用户干预的情况下‘自主’运行)。MemGPT 使用解析器处理事件,将其转换为纯文本消息,这些消息可以附加到主上下文中,并最终作为输入反馈给 LLM。许多实际任务需要按顺序调用多个函数,函数链式调用允许 MemGPT 在执行多个函数调用后再将控制权交还给用户。在 MemGPT 中,可以通过一个特殊标志来调用函数,该标志请求在被请求的函数执行完成后立即将控制权交还给处理器。如果存在此标志,MemGPT 会将函数输出添加到主上下文,并且(与暂停处理器执行相反)。如果此标志不存在(一个 yield),MemGPT 将不会运行大语言模型处理器,直到下一个外部事件触发(例如用户消息或计划中断)。
Til next time,
gqjia
at 00:00
