
arxiv:https://arxiv.org/abs/2312.15503
github:https://github.com/FlagOpen/FlagEmbedding/blob/master/README_zh.md (未开源)
作者用 LLaMA2 来做文本的 embedding 的方法 LLaRA ,为此作者设计了两个任务 EBAE (Embedding-Based Auto-Encoding) 和 EBAR (Embedding-Based Auto-Regression) 。
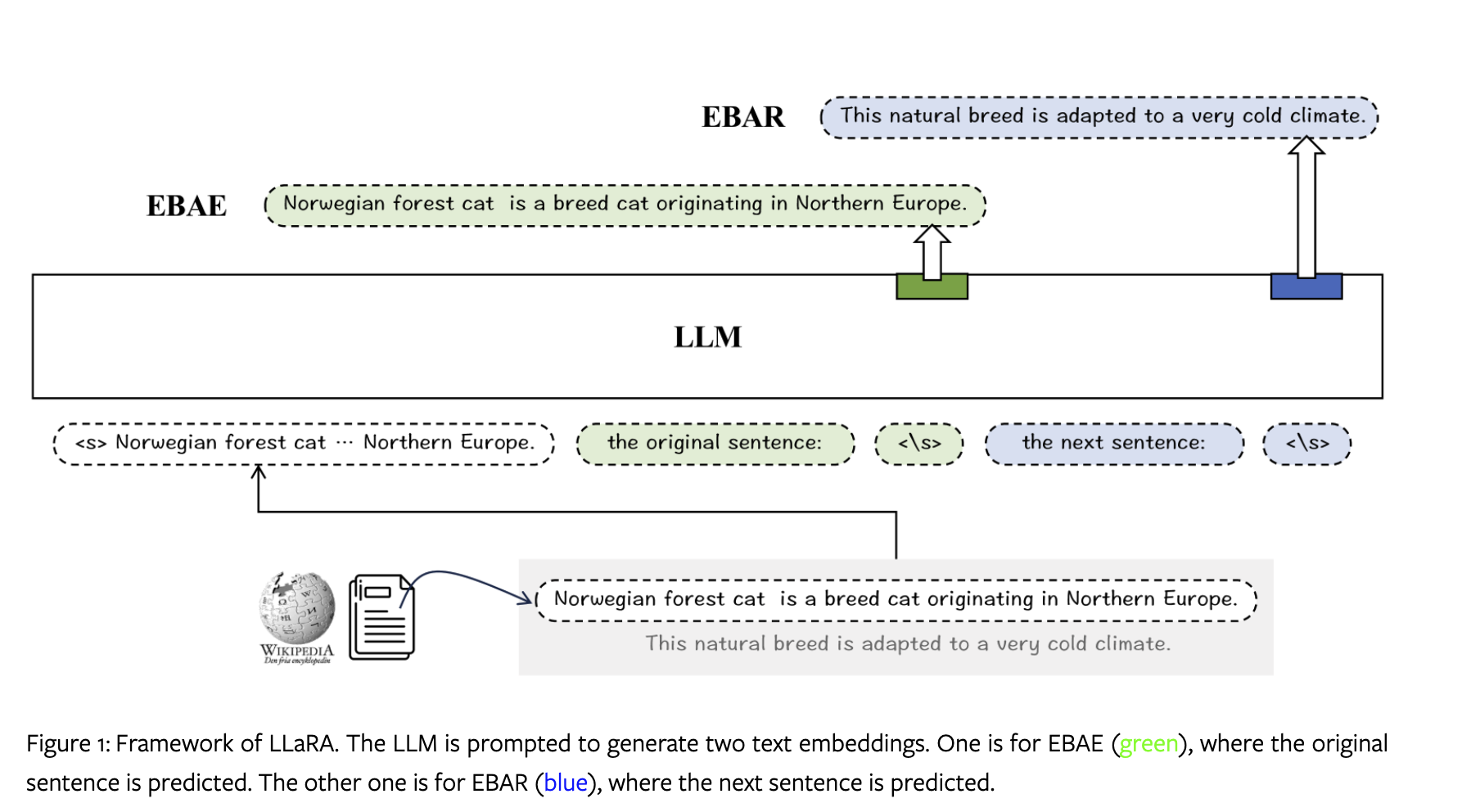
文本 embedding 需要满足以下两个要求:
- 需要表示全局上下文的语义
- 有助于确定 query 和 doc 之间的关联程度
因此设计了两个训练的任务(其实也就是 prompt):
“[Placeholder for input] The original sentence: ⟨\s⟩”
和
“[Placeholder for input] The next sentence: ⟨\s⟩”
也就是之前提到的 EBAE 和 EBAR 。
为节省算力,作者将两个任务合并,修改 attention mask 如下:
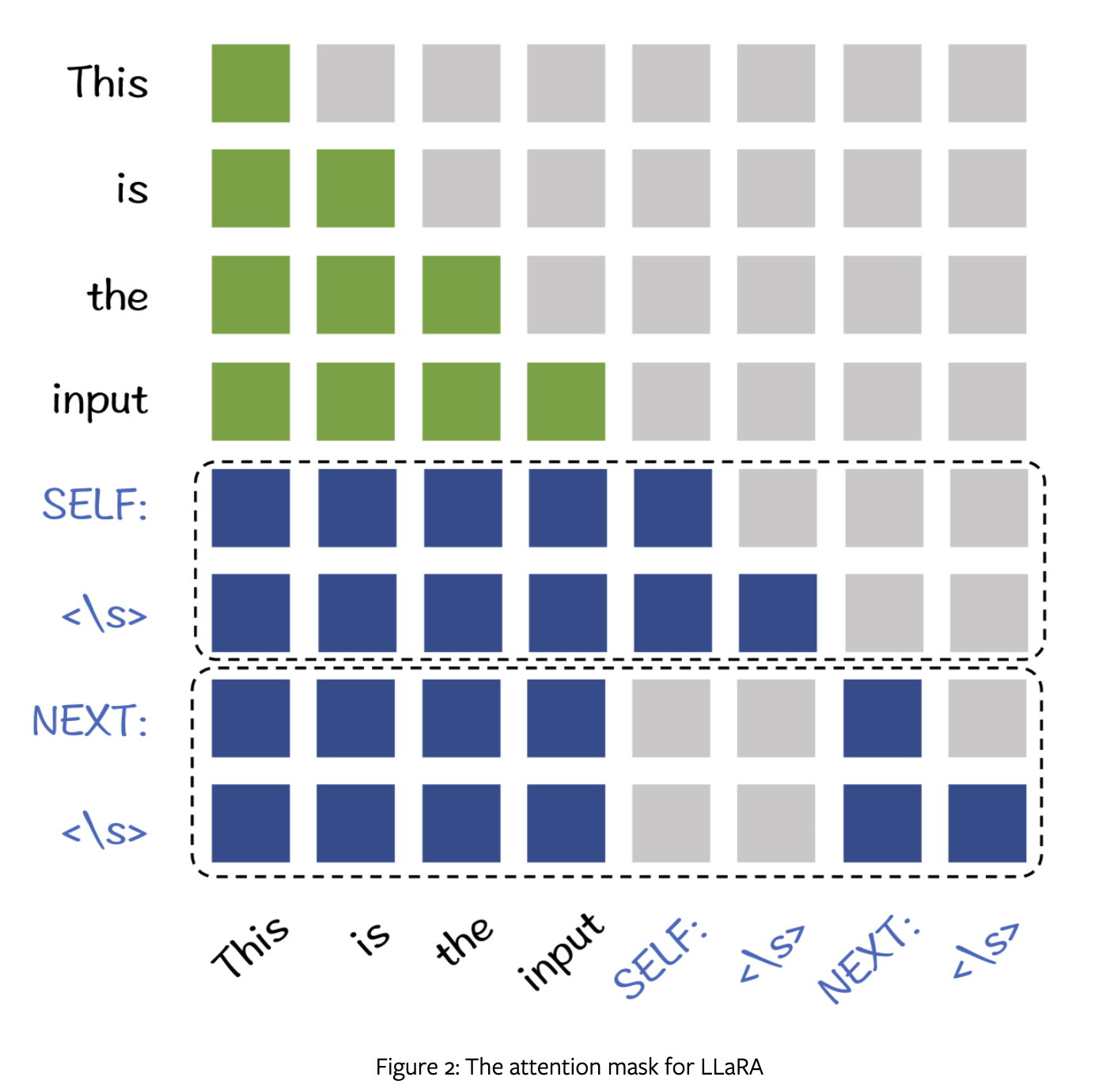
SELF 就是 The original sentence,NEXT 就是 The next sentence 。
后续就是实验部分。
模型选择 LLaMA2 7B ,数据集采用 MS MARCO。
LoRA微调 10000 步,batch size 256,序列长度 1024,学习率 1e-5。使用了 ANN 困难负例进行对比学习。
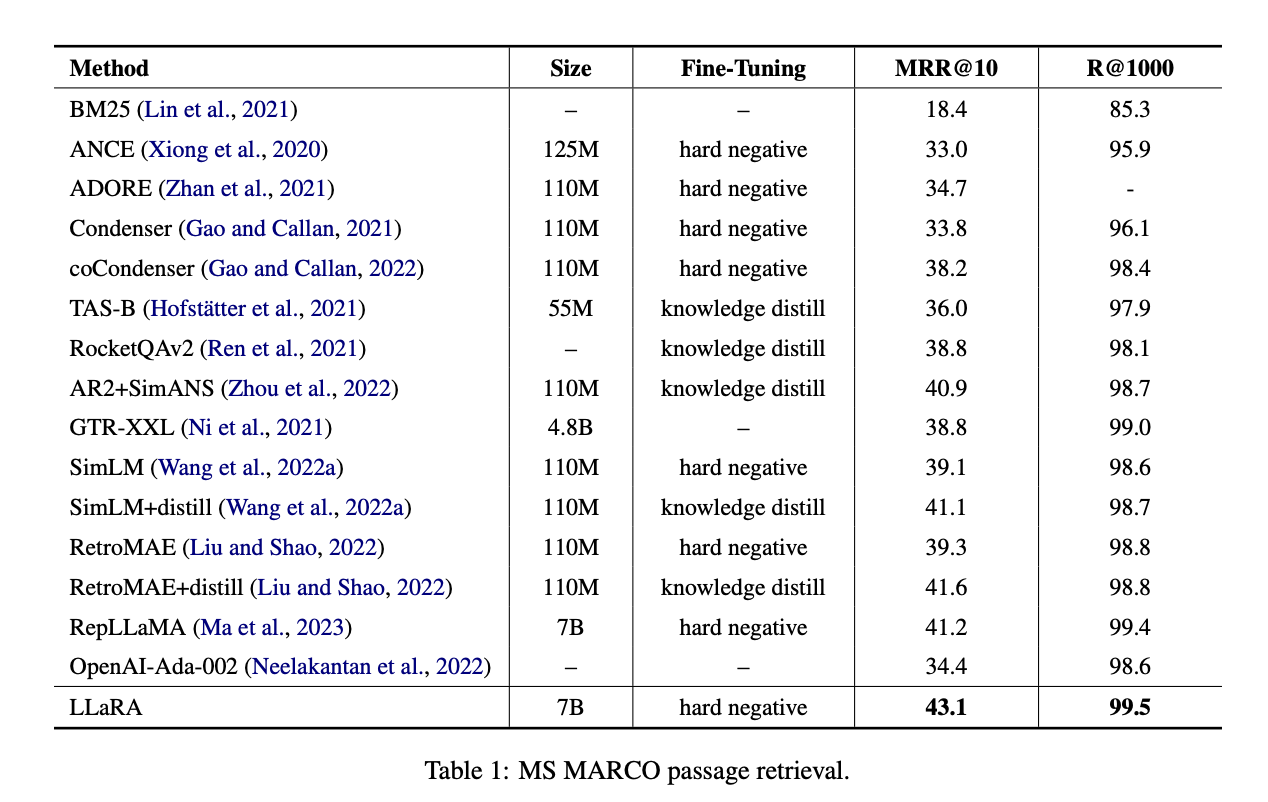
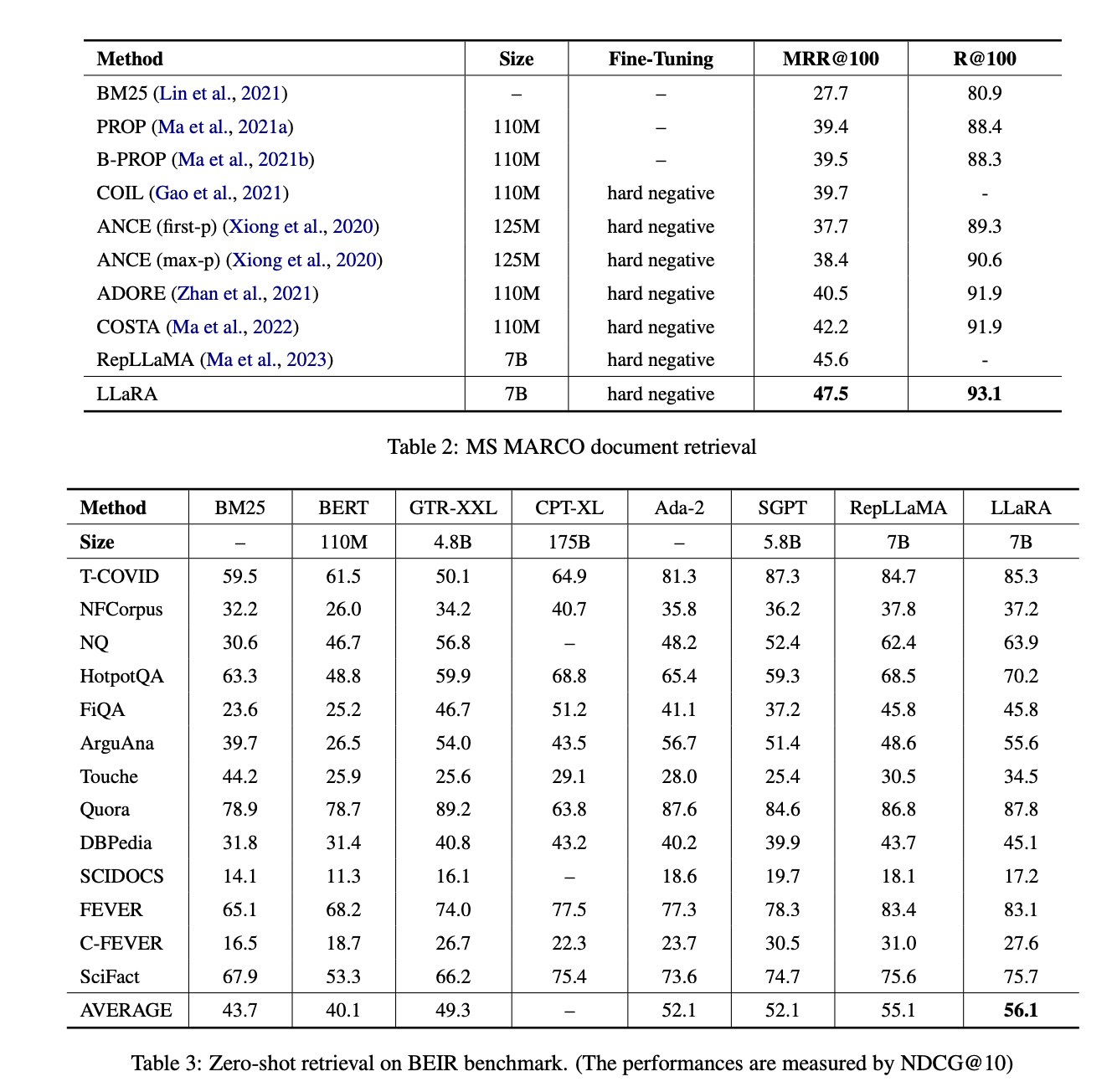
MS MARCO段落检索上,与最接近的RepLLaMA相比,LLaRA在MS MARCO段落检索中的MRR@10提高了1.9%,在MS MARCO文档检索中的MRR@100提高了1.9%,在BEIR零样本检索中的NDCG@10提高了1.0%。
MS MARCO的文档检索上,LLaRA相比之前基于BERT的方法在MRR@100上提升了超过5%。主要是由于 LLaMA 支持更长的上下文。
在BEIR基准测试中的zero-shot评估上,与BERT基线相比,LLaRA在每个单独任务中都取得了更好的性能,最终导致平均性能的NDCG@10提升了16%。
Til next time,
gqjia
at 00:00
