
博客地址:
https://blog.google/technology/developers/gemma-open-models/
https://ai.google.dev/gemma/docs?hl=zh-cn
技术报告:
https://storage.googleapis.com/deepmind-media/gemma/gemma-report.pdf
Gemma 与 Gemini 有相似的结构,在 6T token 上进行了训练。Gemma 有两个尺寸,7B 模型和2B 模型。除了 base 模型之外,还给了 instruct 模型。
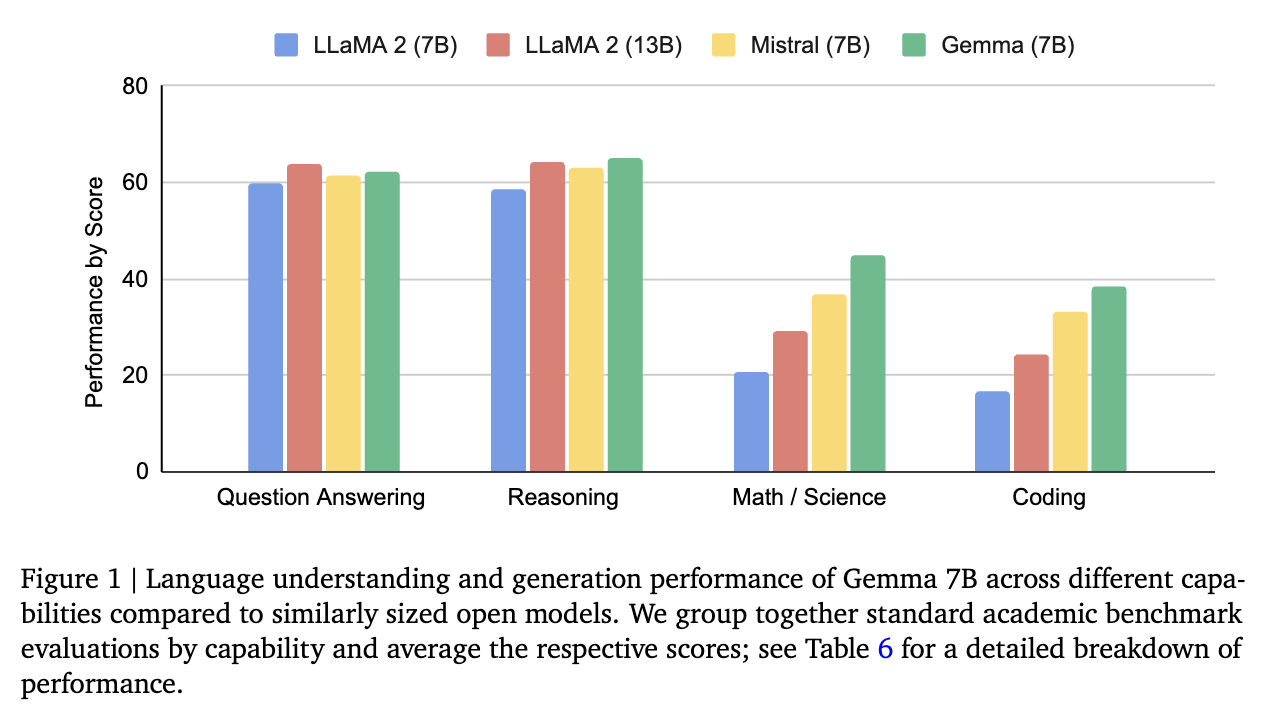
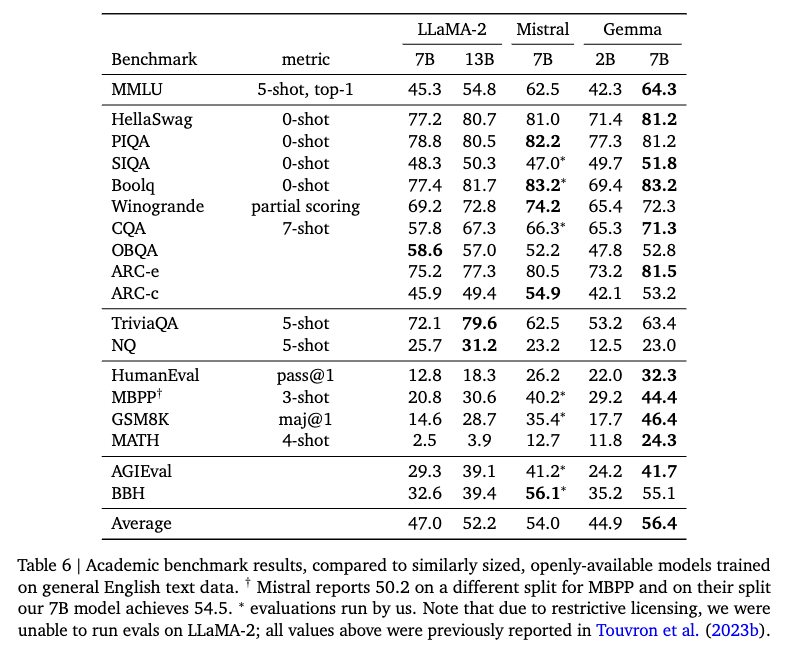
作者对比了 LLaMA2 、 Mistral 和 Gemma 的效果。
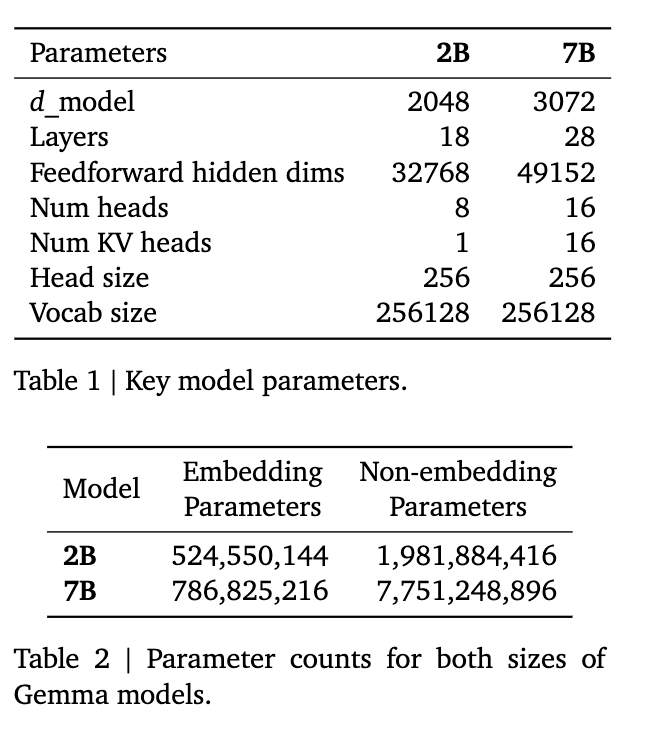
模型参数如下:
在 Transformer 基础上做的改动:
- Multi-Query Attention
- RoPE Embeddings
- GeGLU Activations
- Normalizer Location
在 Transformer 每一层的输入和输出都做了 RMSNorm ,代码如下:
class Block(nn.Module):
"""Transformer block."""
num_heads: int
num_kv_heads: int
embed_dim: int
head_dim: int
hidden_dim: int
def setup(self):
self.pre_attention_norm = layers.RMSNorm()
self.attn = Attention(
num_heads=self.num_heads,
features=self.embed_dim,
head_dim=self.head_dim,
num_kv_heads=self.num_kv_heads,
)
self.pre_ffw_norm = layers.RMSNorm()
self.mlp = FeedForward(features=self.embed_dim, hidden_dim=self.hidden_dim)
def __call__(
self,
x: jax.Array,
segment_pos: jax.Array,
cache: LayerCache | None,
attn_mask: jax.Array,
) -> tuple[LayerCache | None, jax.Array]:
inputs_normalized = self.pre_attention_norm(x) # 先做一次 RMSNorm
cache, attn_output = self.attn(
inputs_normalized,
segment_pos,
cache,
attn_mask,
)
attn_output += x
residual = attn_output
attn_output = self.pre_ffw_norm(attn_output) # attention 之后,MLP 之前 再做一次
outputs = self.mlp(attn_output)
outputs = residual + outputs
return cache, outputs
预训练设置:
7B 模型用了 16pods 4096 TPUv5e,2B 模型 2 pods 512TPUv5e 。
数据集上分别用了 2T 和 6T 数据上进行训练,主要是英文数据集,包括网络文档、数学和代码。
tokenizer 使用 Gemini 的子集,词表大小为 256k 。
数据清晰了个人信息和敏感数据,数据配比是根据一系列消融实验确定的,而且在训练过程中分阶段改变数据占比。
Instruction Tuning 阶段:
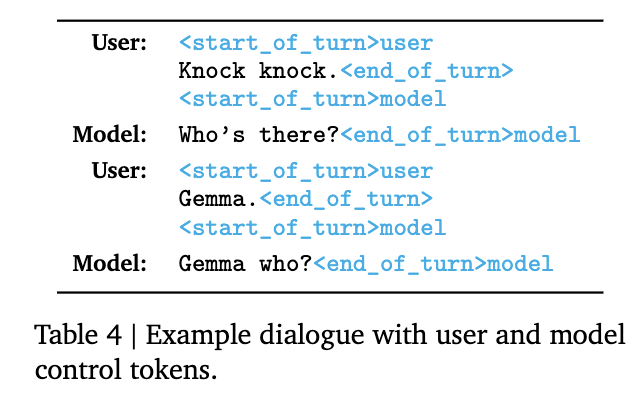
对话数据格式如下:
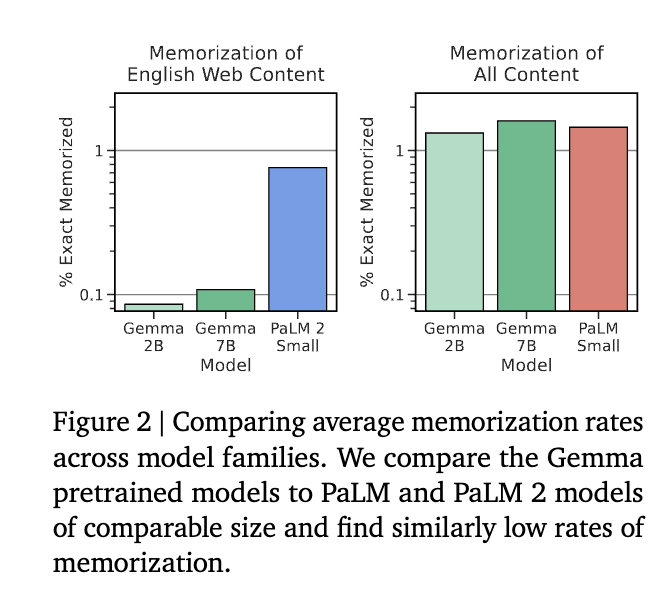
记忆指的是能够推断或产生模型给定的训练数据。在网页数据上,Gemma 没有 同当规模的 PaLM 高(训练数据的原因),但是在全部数据上有着相近的能力。
Til next time,
gqjia
at 00:00
