
论文作者: 北京大学 Xiao Pu、Mingqi Gao
arxiv: https://arxiv.org/abs/2309.09558
为了验证目前 LLMs 生成摘要的效果,作者整理了一个新的数据集,采用人工评价的方式评测目前 LLMs 在五种文本摘要任务(单文档、多文档、对话、代码、多语言)上的效果。通过与人工编写的文本摘要和经过微调之后的文本摘要模型做对比,作者发现,当前 LLMs 生成的文本摘要更忠实于原文而且有更少的幻觉。因此,作者表示,除了创建更高质量数据集和研究更加可靠评估方法等领域,文本摘要任务已经几乎没有研究的必要。
数据集
作者使用最新的数据构建数据集,每个数据集实例包括50条数据。总共包括单文档、多文档、对话、多语言、代码五类数据。
模型
LLM 方面,作者选择 GPT-3 、GPT-3.5、GPT-4 ;小模型方面,单文档任务采用 BART 和 T5、多文档摘要用 PEGASUS 和 BART、对话摘要用 T5 和 BART、 多语言摘要用 MT5 和 MBART、代码摘要用 codet5 。
实验过程和细节
对每个任务雇佣了两个标注人员,每个人都需要标注完每个任务全部的 50 条数据。评估时需要对所有模型生成的模型对比生成效果,对于一条数据需要对比 $C_n^2$ 次。这样对比下来,不同标注人员的一致性是可以保障的。论文用了 Cohen’s kappa coefficient 计算结果为 0.558 。
科研中,有些二分类任务的结果需要human evaluation作为groundtruth。这时候,两个author会对实验结果进行采样并判断是否分类正确,Cohen’s Kappa coefficient越高,代表他们对于结果一致认可的程度越高。
实验结果
实验1:生成摘要的质量
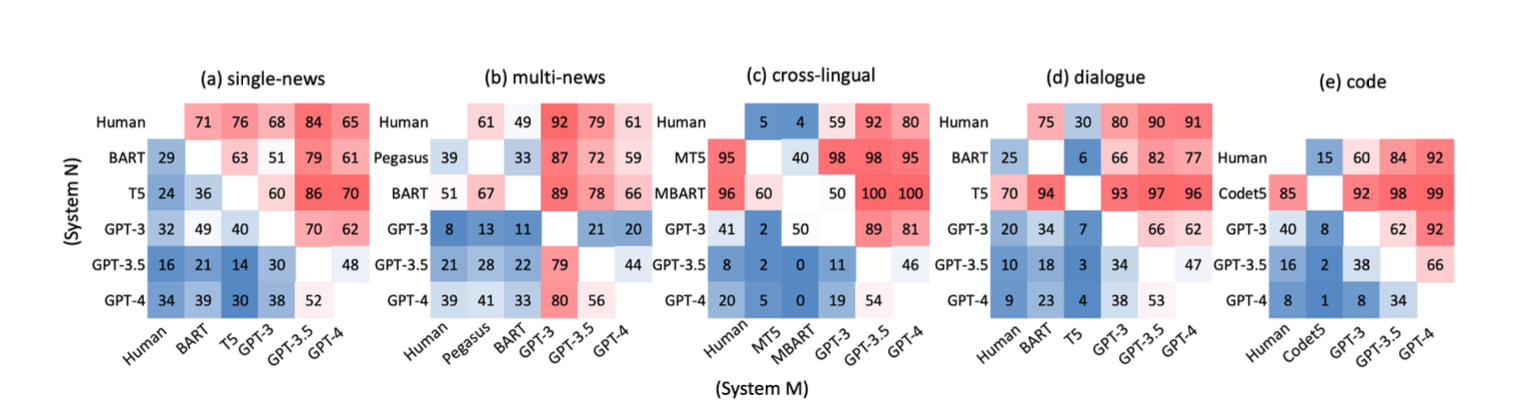
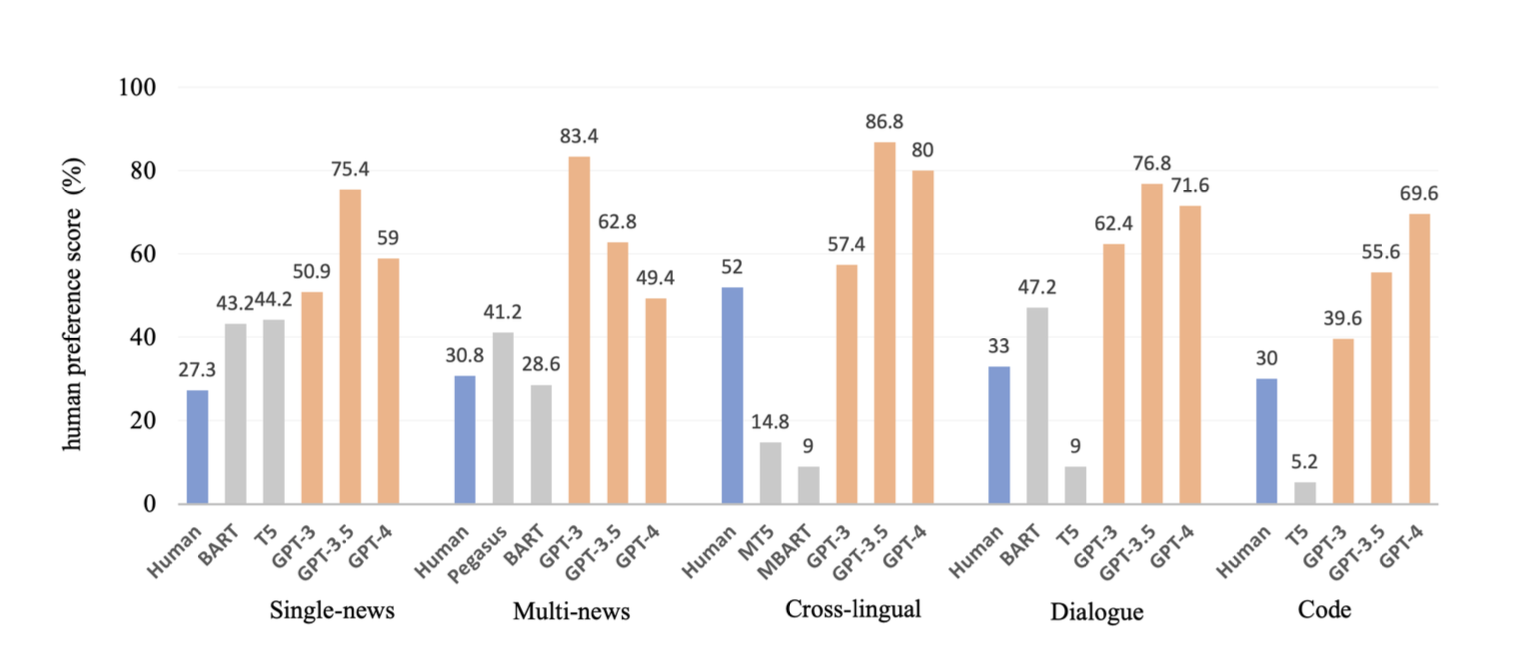
图中代表x轴上的模型优于y轴模型的比例,红色代表超过 50%,颜色越深代表数据越大(蓝色代表越小)。LLMs 生成文本在人工评价看来效果更好。
LLMs 生成的摘要甚至好于人工标注的摘要,这启示我们需要进一步探讨人工编写的参考摘要是否存在局限。
实验表明,LLMs 生成摘要在流畅性和连贯性上的表现优于人工编写的摘要。
实验2: 生成摘要的事实一致性

因为人工成本,作者只对比了人工摘要和GPT4的生成效果。相比 LLMs 生成的摘要,人工编写的摘要存在更多事实不一致的问题,在多语言摘要取得相当的效果,在代码摘要上人工编写的摘要存在远高于 LLMs 的问题。
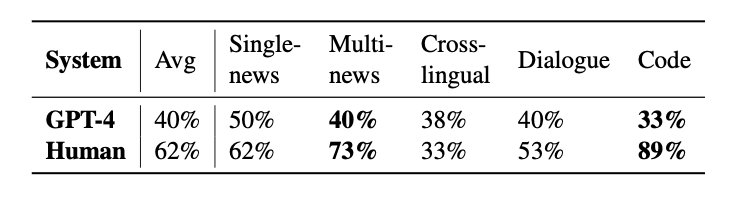
论文进一步对比了内部幻觉和外部幻觉,表中给出外部幻觉所占的比例。
根据实验结果,在创造性更强的任务中,外部幻觉的比例更高,人工编写摘要的事实一致性更差。
对比分析
参考摘要相比 LLMs 生成的摘要相比,缺乏连贯性(存在缺失)而且存在幻觉。
微调模型相比 LLMs 生成的摘要相比,具有固定的长度,而 LLMs 在处理信息密度更大的文本时可以调整长度;在面对多个主题的时候,微调模型覆盖率更低。
文本摘要可以继续研究的方向
- 数据集由训练转为测试,而且需要更多类型的数据集(更多语言、更多领域),并且需要包含更长的文本。
- 需要更多偏向应用的摘要:针对特定用户的定制摘要、实时摘要、交互式摘要。
- 摘要评估:ROUGE指标已经过时,未来需要更加合理的评估方案。
Til next time,
gqjia
at 00:00
