
论文作者: MIT、Meta Guangxuan Xiao
当前多轮对话场景的 LLMs 有两个难点:1. 解码阶段缓存 KV 需要耗费大量的内存;2. 流行的 LLMs 不能拓展到训练长度之外。
作者发现使用 windows attention 并不能扩展长度,但是通过一种现象 attention sink (保留 起始token 的 KV )能够恢复 windows attention 的效果。作者发现,之所以出现这一现象是因为,起始 token 有着更高的注意力分数,即便是当它在语义上已经不重要了也依然如此。因此作者设计了一个 StreamingLLM 的框架,在不进行微调的情况下,使用有限长度的注意力窗口就能将 LLMs 扩展到无限长度。StreamingLLM 能够让 Llama2、MPT、Falcon、Pythia 稳定且高效地输出 4M 长度的 token 。而且作者发现,当在训练时增加一个占位符可以进一步改善 LLMs 流式部署。作者实验证明,StreamingLLM 性能比 滑动窗口 基线高出 22.2倍。
作者比较了几个策略的效果:
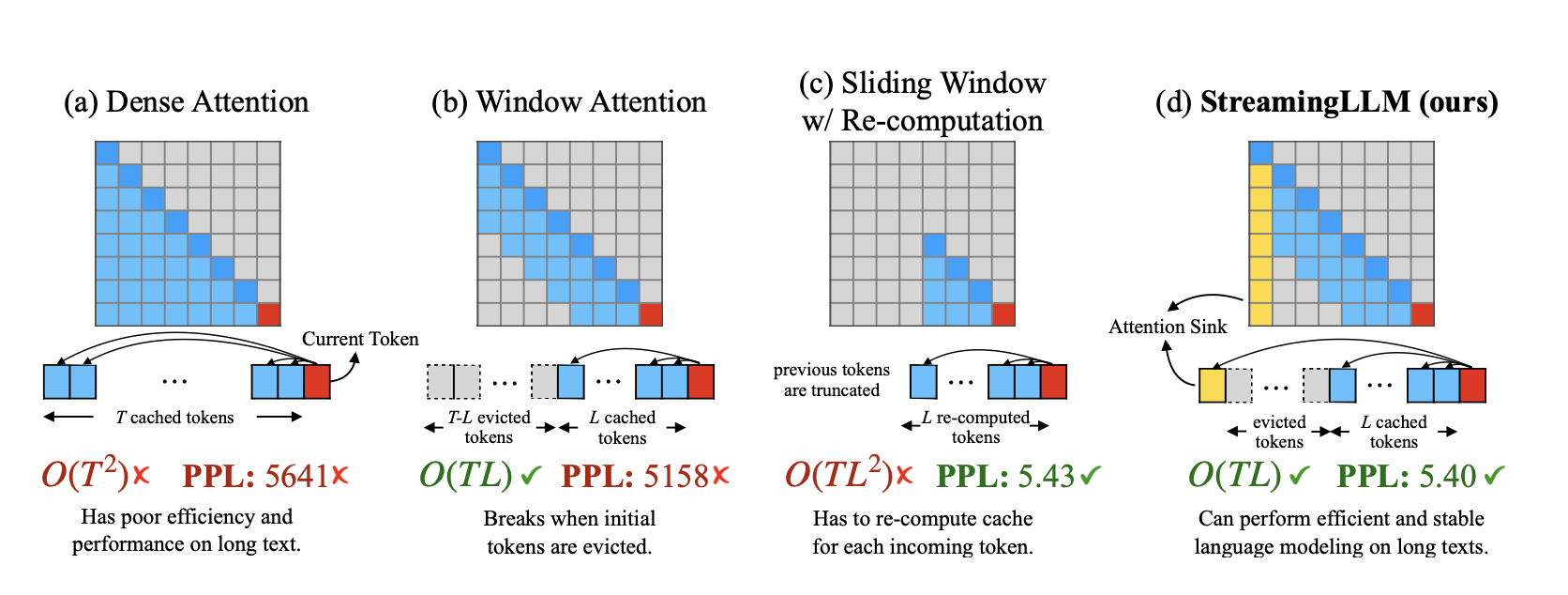
当预测长度远大于训练长度时,dense attention 计算复杂度是很大的,而且生成质量也存在问题;使用 window attention 虽然可以降低计算复杂度,但是生成质量的问题依然存在;滑动窗口加上重计算虽然可以提升生成效果,但是计算复杂度依然很高;streamingLLM 通过保留起始的token稳定注意力计算,不仅保证了生成质量还降低了计算复杂度。
Llama-2-7B中超过256个句子(每个句子的平均长度为16)的平均注意力记录的可视化:
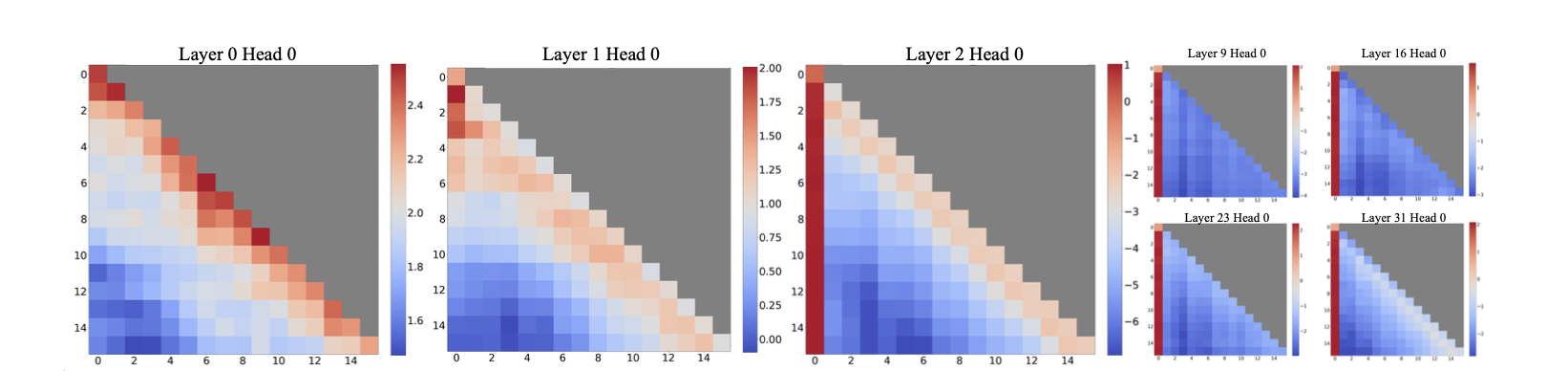
可以看到在前两层中,注意力更集中于相邻的位置,而在之后的模型层中,模型开始大量关注所有层和头部的起始 token。
当移除起始token 时会使得 softmax 的计算分布出现很大的偏差,
在20k token 长度文本上语言模型的PPL:
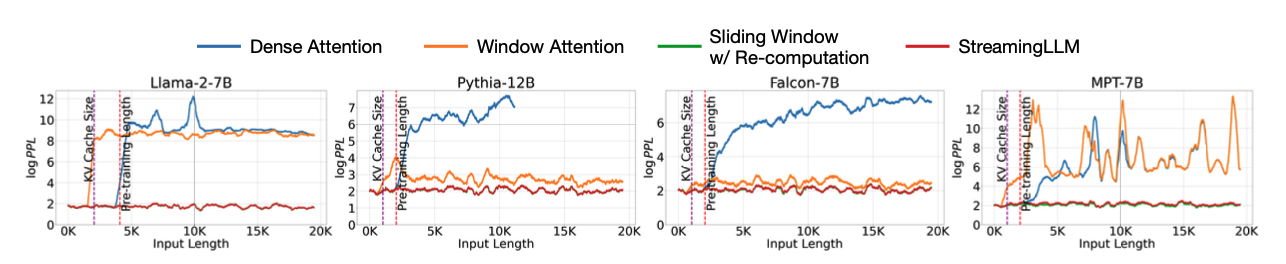
随着输入长度的增加 生成文本困惑度的变化。dense attention 一旦超过预训练长度,PPL就会增加;window attention 在长度超过 cache 大小就会崩溃;StreamingLLM 与加重计算的滑动窗口效果相当,一直保持稳定的 PPL。
实现细节
作者改进了一下Softmax,也就是把softmax的分母加了个1仅此而已,这样所有位置值可以加和不为1,这样Attention就有了可以不对任何位置“表态”的权利。
SoftMax函数的性质使得所有经过attention结构的激活张量不能全部为零,虽然有些位置其实不需要给啥注意力。因此,模型倾向于将不必要的注意力值转嫁给特定的token,作者发现就是initial tokens。在量化异常值的领域也有类似的观察(这里引用了一些Song Han组的文职),导致Miller大佬提出了SoftMax-Off-by-One作为可能的解决方案。
实验
1. LLMs 对超长文本建模
在 4M token 长度的超长文本的情况下,使用StreamingLLM 框架的 LLMs 的 PPL 值:

PPL整体保持稳定。
2. 使用一个 sink token 预训练的结果
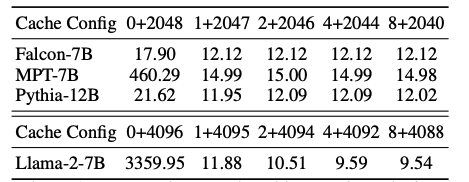
在Pre-training with a sink token情况下,作者从头训练160M的模型。首先证明了增加一个sink token对模型pre-training的收敛效果没有损耗。然后展示了经过预训练后模型表现比不预训练要好。下表所示,Cache Configx+y表示添加x个初始标记和y个最近的标记,原始模型需要多个initial tokens。虽然ZeRO Sink模型显示出轻微的改进,但仍需要大于1个initial tokens。相反,使用可Learnable Sink训练的模型只需增加一个sink token即可。
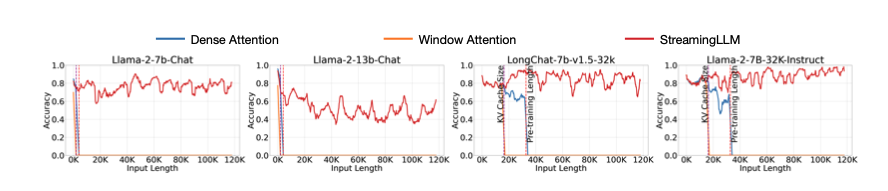
3. 指令微调之后的模型的效果
StreamingLLM既没有扩大LLMs的上下文窗口,也没有增强它们的长期记忆。所以,这套方法最大好处就是无限长的输出,而不能记忆超长的输入。
4. 消融实验
作者用相邻的 token 和 不同数量的 起始 token进行计算,PPL如下表所示。
结果表明,仅使用1个或2个起始token 是不够的,当数量增加到4个的时候PPL数值就比较合理了。再增加数量会产生边际效应。
在 StreamEval 基准上的表现,在100条数据上取了平均值:
结论
该方案使得 LLMs 在输入输出长度上取得飞跃,但是没有增强长期记忆。StreamingLLM的优势在于,它可以从最近的tokens生成流畅的文本,而不需要刷新缓存。
Til next time,
gqjia
at 00:00
