
本来想总结一下自己对预训练模型的一些认识,但是我明显低估了这个任务的难度。 正好这段时间清华大学唐杰老师在微博上推了一个综述论文 Pre-Trained Models: Past,Present and Future 。 就以这篇论文的笔记作为开始吧。

这是清华大学悟道团队出的一篇讲预训练的论文。 不得不说,这密密麻麻的作者和机构看起来就很唬人。
让我们跳过前面讲预训练发展历史的部分,直接看预训练语言模型。
GPT 和 BERT
基于 Transformer 的预训练语言模型主要分为两个分支, GPT 和 BERT 。 前者使用自回归语言模型(autoregressive language modeling)作为预训练目标, 后者则使用了自编码语言模型(autoencoding language modeling)作为预训练目标。 一般而言, GPT 更擅长生成(NLG)任务, BERT 更擅长理解(NLU)任务。
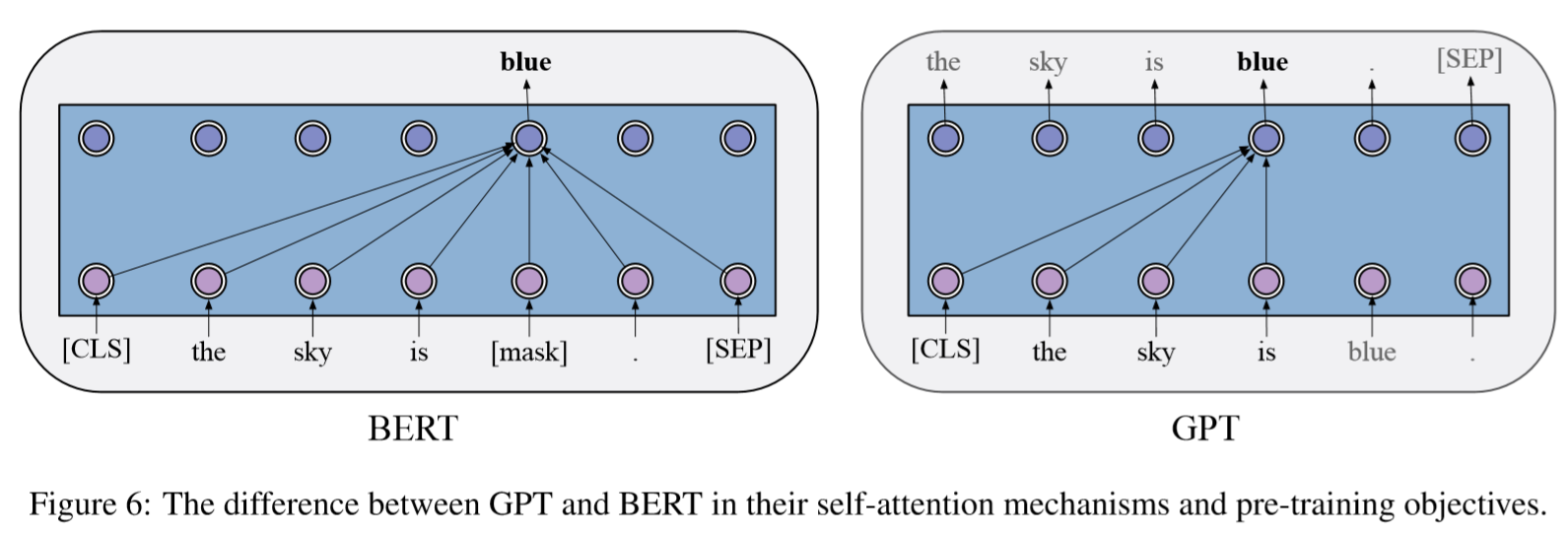
GPT 的预训练也是跟自回归语言模型一致,根据先前的文本最大化当前词的条件概率。 在预训练之后通过微调(fine-tuning)适应下游任务。 输入文本通过 GPT 获取最后一层的表示(representation),将其经过额外的输出层得到下游任务目标。
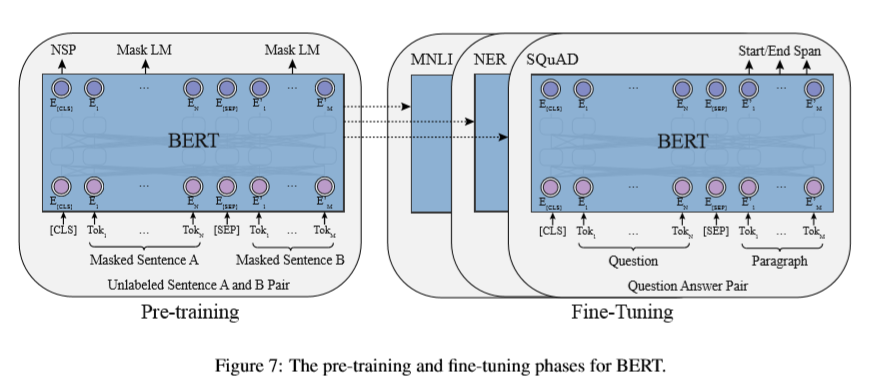
BERT 的预训练则采用了另一个思路,通过当前字两侧的文本预测当前字的概率。 为此 BERT 采用了一个预训练任务 MLM (masked language modeling)。 通过使用 [MASK] 随机遮蔽文本中的字(token),然后在预训练时对其进行预测。 除此之外, BERT 还采用了 NSP (next sentence prediction)预训练任务, 在预训练时预测两个句子是否构成上下句关系。 在微调阶段,输入如果存在两个句子则使用 [SEP] 连接,输入文本开始需要加上 [CLS] , BERT 会给每个输入 token 输出一个表示,这个表示可以用于序列标注任务和问答任务。 [CLS] token 的表示可以看作整个句子的表示,将其通过一个额外的分类层就可以用于分类任务。
在此之后,RoBERTa 和 ALBERT 都对 BERT 做了一定的改进,其中 RoBERTa 对 BERT 的改进主要包括4点:
- 去掉了 NSP 预训练任务(RoBEARTa 指出 BERT 不需要 NSP 这个预训练任务,不过最新的研究 NSP 任务还是很重要的);
- 使用了更大的 batch size ,更多的训练数据和更多的训练步数;
- 使用了更长的训练文本;
- 动态修改 [MASK] ;
而 ALBERT 则从减少参数量的角度改进了BERT:
- 将输入 embedding 矩阵拆分为两个较小的矩阵;
- Transformer 各层之间共享参数;
- 使用句子顺序预测预训练任务(SOP)代替 NSP ;
因为牺牲了空间效率, ALBERT 微调和推理的速度很慢。
对于预训练语言模型的改进主要集中在以下几个方面:
- 改进模型结构或者设计新的预训练任务(XLNet、UniLM、MASS、SpanBERT、ELECTRA);
- 尝试多语言版本、结合知识图谱或者多模态的预训练语言模型;
- 扩大预训练语言模型的尺寸(GPT、Switch Transformer)的同时提高计算效率;
后面详细讲一下各个方面的改进。
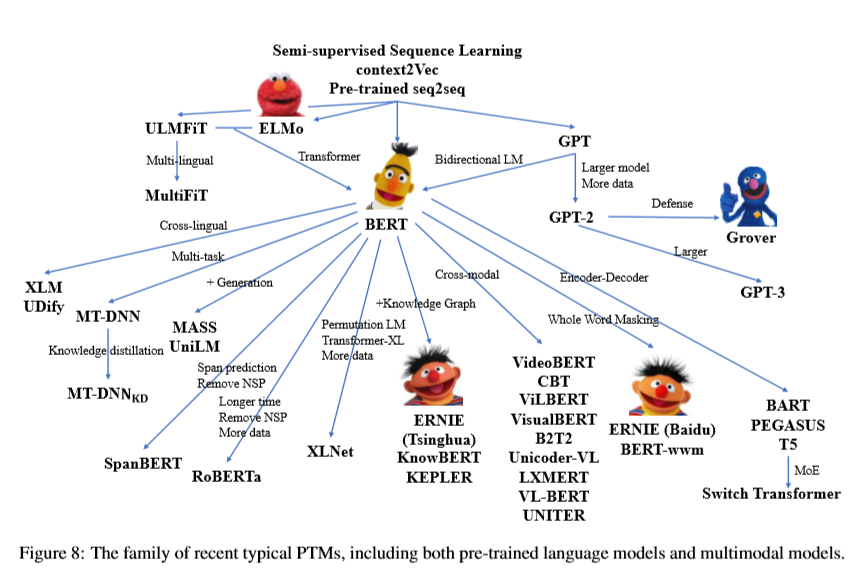
结构上的改进
预训练语言模型在结构上的改进主要有两个目的, 一是希望能建立一个统一的预训练语言模型(unified sequence modeling), 另一个是 cognitive-inspired architectures。 除此之外,有些改进主要用于提高自然语言理解的任务。
统一语言建模方向的改进
XLNet 使用了置换语言建模(permutated language modeling)统一了 GPT 风格的单项语言生成和 BERT 风格的双向语言理解。 论文指出 BERT 在预训练时使用 [MASK] 遮蔽的策略,而下游任务却没有出现 [MASK] 。 这使得预训练任务和下游任务存在矛盾。 为此, XLNet 在做预训练时对字的顺序进行重新排序,然后采用自回归的范式进行预训练,这使得 XLNet 同时具有了理解和生成的能力。
MPNet 采用了跟 XLNet 一样的置换语言建模,同时弥补了 XLNet 在预训练时不知道句子长度而下游任务知道句子长度这一矛盾。
UniLM 则是从多种预训练任务的角度建立一个统一的预训练语言模型。 UniLM 联合训练了单向(unidirectional)、双向(bidirectional)和序列到序列(sequence-to-sequence)三种预训练任务。 之所以能实现这一操作,是因为 UniLM 在注意力计算时采用了 MASK 的策略。 UniLM 在生成问答和生成式摘要上取得了很好的效果。
GLM 采用了一个更加优雅的方式统一自回归和自编码。 GLM 选择文本中的一个片段进行 MASK ,并不像 BERT 和 SpanBERT 一样告诉模型 [MASK] 代表了多少个字(token), 并采用了二维位置编码的策略保存 [MASK] 的长度信息。 GLM是第一个在自然语言理解、条件生成和无条件生成等所有类型任务中同时实现最佳性能的模型。

Seq2Seq 结构最早的模型是 MASS ,MASS 将预测 MASK 的机制加入到编码解码结构中。 但是也没有解决用可变长度的文本填充空白的问题(GLM之前基于编码器或者解码器的预训练语言模型都存在这一问题)。
T5 则是通过 MASK 一个片段来解决这一问题。
BART 则是通过截断、删除、替换、打乱和 MASK 多个策略处理源文本。 在这一方向上针对具体任务的预训练语言模型包括 PEGASUS 和 PALM 。
基于 Seq2Seq 预训练语言模型主要问题是参数量更多,而且通常在 NLU 任务上表现不好。
受到认知影响的结构(Cognitive-Inspired Architectures)
这部分的工作主要在可维护的工作记忆(maintainable working memory)和可持续性长期记忆(sustainable long-term memory)方向。 maintainable working memory 方向的工作主要有 Transformer-XL( segment-level recurrence 和相对位置编码)、 CogQA(在多跳阅读中维持一个认知图)、 CogLTX(使用 MenRecall 模型选择句子,并用另一个模型生成或选择答案)。 sustainable long-term memory 方向的工作主要有 REALM、RAG。 前者通过样本维度的记忆提升长距离理解能力,后者则是信息提前编码, 再通过检索获取需要的信息。
其他方向
其他方向的改进主要集中在 MASK 策略上, Span-BERT 提出的 SBO (span boundary objective) 预训练任务的思路在 ERNIE、 NEZHA 和 Whole Word Masking 上都有体现(这可以被看作是一种数据增强)。
另一种则是将预测 MASK 的任务目标改的更加困难,比如 ELECTRA 的 RTD(replace token detection) 需要一个生成器生成原始 token ,一个判别器判断 token 是否被替换。
多源数据
这部分的研究主要在跨语言、多模态和融合知识信息上。
跨语言
在 BERT 出现之前,跨语言模型主要通过参数共享和学习语言无关的约束两个方式学习到跨语言的参数表示。 在 BERT 出现之后,模型可以直接在多跨语言非平行语料上进行预训练。 mBERT 在模型结构没有变得情况下,使用104种语言的 Wikipedia 语料库上进行了预训练。 XLM-R 构建了一个100种语言的非平行语料库 CC-100 。
MMLM(multilingual masked language)预训练任务不能很好的适应平行预料, 但是对于翻译任务来说平行语料又非常的重要。 为此 XLM 提出了 TLM(translation language modeling) 预训练任务, 在双语句子对上进行预训练。 除此之外,Unicoder 提出了两种预训练任务 CLWR 和 CLPC ; ALM 通过平行语料基于代码生成文本,然后在此基础上进行 MLM 预训练任务。 InfoXLM 从信息论的角度对 MMLM 和 TLM 进行了分析,使用对比学习进行训练。 HICTL 拓展了使用对比学习让模型学习句子级和单词级语义表征的想法。 ERNIE-M 提出了 BTMLM(back-translation masked language) 利用反译拓展了平行语料库的规模。
在 Seq2Seq 结构的预训练语言模型中, mBART 通过添加特殊符号使得 DAE(denoising autoencoding) 支持多语言; XNLG 则是提出了 XAE(cross-lingual autoencoding) 训练任务。
多模态
图像-文本的跨模态语言模型的主要难点在于如何将非文本信息集成到 BERT 框架中。 ViLBERT 通过对图像和文本数据进行预处理, 将 BERT 拓展为支持两个输入流的图像和文本的多模态模型。 它使用三个预训练任务:MLM、 SIA(sentence-image alignment) 和 MRC(masked region classification)。 下游任务包括五个: VQA(visual question answering)、 GRE(grounding referring expressions)、 ITIR(image-text retrieval)、 ZSIR(zero-shot imagetext retrieval)。 LXMERT 在 ViLBERT 的基础上使用了更多的与训练任务: MLM 、 SIA、 MRC、MRFR(masked region feature regression) 和 VQA 。 LXMERT 的下游任务只有三个: VQA、 GQA(graph question answering) 和 NLVR2(natural language for visual reasoning)。 VisualBERT 拓展了 BERT 的结构,预训练采用 MLM 和 IA ,下游任务有 VQA 、 VCR、 NLVR2 和 ITIR 。 Unicoder-VL、VL-BERT都在 VisualBERT 的基础上做了改进。 B2T2、VLP、UNITER则是针对特定下游任务做了优化。
X-GPT 则是面向生成任务, 它的预训练任务包括 IMLM(image-conditioned masked language modeling)、 IDA(image-conditioned denoising autoencoding)、TIFG( text-conditioned image feature generation), 下游任务只有 IC(image captioning)。 Oscar 使用目标检测得到的标签作为锚点,简化图像和文本的对齐。这一方法在六个下游任务上取得很好的效果: ITIR、 IC、 NOC(novel object captioning)、 VQA、 GCQ、 NLVR2。 图像到文本生成领域的研究有 DALLE、 CogView。
近期的研究主要有 CLIP 和 WenLan ,它们都在大规模的数据上进行了预训练。
知识上的预训练
对于结构化的知识,许多研究通过融入实体和关系的表征或者将其和文本进行对齐。 有些研究将知识图中的路径或者子图视为一个整体, 通过与对齐后的文本进行建模, 从而保留更多的结构化信息。 这种对齐工作往往非常的复杂, 为此也有研究工作研究文本和知识的自动对齐。
非结构化数据在包含更多的信息时,也有更多的噪声。 现有的工作一般通过预训练将知识隐含的存储于模型参数中。
计算效率方向的改进
这部分就简单讲一下。
提高计算效率可以从三个方面入手:系统上的优化;更高效的学习算法和模型压缩。
对于单卡计算效率的优化可以采用 fp16 ,虽然会损失部分精度,但是可以大幅度提高计算效率。 fp16 有时会遇到浮点截断和溢出的情况,为此可以采用混合精度计算。 对于预训练时内存消耗过大的问题,有些研究使用 ZeRO-Offload 的策略调度 CPU 内存和 GPU 内存, 让内存交换和设备计算尽可能重叠。
多卡训练可以采用模型并行的方案,将模型参数分布到不同的节点, 通过节点间的通信确保前向和反向计算的正确。 模型并行在进行通信时,不能同时进行计算,而数据并行时可以同时进行反向计算。 并且数据并行可以缓解对内存的需求。 数据并行时,优化器的状态存在冗余, 为此 ZeRO 优化器可以对数据并行的每个节点平均划分和分配优化器状态。
除去上述方法,还有一种并行方法是管道并行(pipeline parallelism), 它将神经网络划分为多层,将不同层放在不同的节点上, 计算完每个节点后将输出发送到下一层计算所在的节点上。 这样只需要相邻层的节点间保证通信即可。 这样的研究有 GPipe 和 Terapipe 。
在预训练算法上思路主要有两种, 一种是设计更高效的预训练学习方法, 一种是设计更高效的模型结构。
MLM 的预训练任务中 MASK token 时, 通常是从所有 token 中选择一个子集,对子集中的 token 进行 MASK, ELECTRA 使用了检测 token 是否被替换的训练任务,这样就可以利用所有的 token, 只需要较小的步就能达到类似的效果。 除此之外,也有研究在反向传播或者梯度计算时,根据 token 的重要性 MASK 部分 token 。
warmup 的策略可以缓解模型刚开始训练因为 batch 过大导致模型很难达到最优的问题。 一些研究表明预训练模型不同层可以共享自注意力模式, 因此可先训练一个较浅的模型,然后通过复制将其变为一个较深的模型。 在训练时也可以删除一些层以降低反向传播和权重更新的复杂性。 此外在 batch 较大的时候不同层使用不同的学习率可以加快收敛速度。
在模型结构上,主要研究工作在降低 Transformer 结构的复杂度。 Tansformer 中注意力权重计算的复杂度是 $O(n^2)$ , 随着输入长度的增加,计算需要的时间和空间也会增加。 为此一些研究尝试设计 low-rank kernel , 只需要线性的复杂度就可以贴近原始注意力权重。 另外也有一些研究考虑增加计算时的稀疏性。 最近的 Switch Transformer 使用 MoE(Mix-of-expert) 的方法可以增加模型参数的同时保持计算开销不变。
模型压缩主要的研究有参数共享、模型剪枝、知识蒸馏、模型量化(Model Quantization)。
参数共享可以参见上文介绍的 ALBERT 。 模型剪枝可以剪掉模型没用的部分,在加速计算的同时保持模型效果。 可以在训练时有选择的丢弃一些 Transformer 层,可以在推理时得到一个比较浅的网络。 也有研究表明模型不需要过多的 attention head ,降低其数量对模型精度影响很小。 除此之外, CompressingBERT 尝试 prune 注意力层和线性层的权重, 从而在减少模型参数量的同时保持于原始模型相当的效果。
参数共享并不能减少推理阶段的计算开销, 而知识蒸馏使用一个小的模型模拟大模型的输出概率、隐状态和注意力矩阵, 可以同时减少推理阶段的开销。 典型的知识蒸馏的模型有 DistillBERT、 TinyBERT、 BERT-PKD、 MiniLM。
模型量化指对高浮点精度进行压缩, 这一方法在基于 CNN 的模型中得到了广泛的应用。 对于基于 Transformer 的模型来说, Q8BERT 证明 8-bit 的 quantization 对模型效果影响很小。 当降低到 1-bit 或者 2-bit 时候模型效果会急剧下降, 为此需要用其他方法保证模型精度。 Q-BERT 就使用了 mixed-bits 量化,高 Hessian spectrum 参数使用更高的精度。 TernaryBERT 将知识蒸馏用在模型量化上,用一个低 bit 的模型模拟原模型。 这种 low-bit 模型与硬件有更高的相关性, 这意味着只能在一个非常好的硬件设备上实现,在通用设备上不能做到。
分析
除了利用预训练语言模型最求更高的效果以外, 也有一些研究者在分析预训练语言模型如何实现这一效果的(understanding how PTMs work) 和预训练语言模型学到了什么(uncovering the patterns that PTMs capture)。 这部分的研究主要包括预训练语言模型学到的知识、 预训练语言模型的鲁棒性、 预训练语言模型的结构稀疏性(structural sparsity/modularity) 和建立在预训练语言模型之上的理论分析。
预训练语言模型学到的知识
预训练语言模型能够学到的知识分为两类: 语言上的知识(linguistic knowledge)和广义的知识(world knowledge)。
对语言上的知识的分析包括四个方面: 文本表征的调查(representation probing): 在 PTMs 的隐层表征上面加一个新的线性层用来做调查任务; 文本表征的分析:使用隐层表征计算距离或者相似度; 注意力的分析:分析注意力矩阵的统计量; 生成的分析:使用语言模型直接生成; 而广义的知识包括常识(commonsense knowledge)和事实(factual knowledge)。
鲁棒性
通常采用对抗性攻击(对原始数据加入细微的扰动)检验 PTMs 的鲁棒性。 现阶段的 PTMs 都存在严重的鲁棒性问题。 当前主要采用模型预测、预测概率和模型梯度查找对抗实例。 而且最近有研究采用 human-in-loop 的方法生成更加自然的对抗实例。 这对于预训练语言模型的鲁棒性来说又是一个严重的挑战。
预训练语言模型的结构稀疏
当前 PTMs 存在过度参数化的问题。 有研究表明在机器翻译、生成式摘要和语言理解任务中多头注意力结构存在冗余。 在删除一部分注意力头的情况下,反而取得更好的效果。 也有研究表明较低程度的剪枝(30-40%)不会影响模型预训练的损失和下游任务上的表现。 有研究在PTMs上验证了彩票假设(the lottery ticket hypothesis)并且找到一个与完整网络效果相当的子网络。 另外有研究表示可以通过简单的复制一些隐层提高模型效果,这说明冗余的参数有助于微调。
理论分析
还有研究对 PTMs 在理论解释上进行假设和分析:
有研究认为预训练之所以有效是因为存在更好的优化(better optimization) 和更好的正则(better regularization)。 前者使得模型相比随机初始化更接近全局最优, 后者使得模型有更好的泛化性。 实验结果更倾向于 PTMs 有更好的正则。
其他一些研究则在对比学习上, 对无监督的对比表征学习(contrastive unsupervised representation learning)进行了分析。 还有研究提出了一种框架弥补预训练和微调阶段的差别(gap)。 他们提出了一个 latent classes 的概念, latent classes 可以覆盖下游任务的所有 classes, 语义相似的文本对(pair)属于同一个 latent class 。 并且研究证明对比学习的 loss 是下游 loss 的上界, 因此优化预训练 loss 可以降低下游任务的 loss。
未来发展方向
目前看来 PTMs 的研究方向主要包括7个: 模型结构和预训练方法; 多语言和多模态的预训练; 模型效率; 理论基础; 模型边缘学习(Modeledge Learning); 认知学习(cognitive learning); 新的应用方向。
Til next time,
gqjia
at 17:55
