
大厂真是不给活路啊,总能整出各种预训练模型的花活, 而我只能默默 fine-tuning 下游任务。 近期在看百度千言实施一致性文本生成的比赛, 官方给出的 baseline 采用了这个模型, 这就先看一下这篇论文吧(其实是我不能理解为啥这个模型的效果特别的好)。
这篇论文是百度在 ACL2021 上中的一篇论文。
论文概要
当前的预训练语言模型要么是单模态的(文本或者图像)、要么是多模态的(图像文本对), UNIMO 的目的是构建一个既可以完成单模态的理解和生成任务, 又可以完成多模态的理解和生成任务。 对此论文使用了一个跨模态对比学习(cross-model contrastive learning, CMCL)的方法, 将文本信息和图像信息编码进一个共同的语义空间。 这样使得文本和图像不需要严格配对,便有大量的数据可以进行训练。 文本知识和图像知识在共同的语义空间互相增强。
论文提及到了这一想法思路的来源,让我忍不住把原文沾上来了。属实是把我给唬住了。
The research in neuroscience by Van Ackeren et al.
(2018) reveals that the parts of the human brain responsible for
vision can learn to process other kinds of information,
including touch and sound. Inspired by thisresearch,
we propose to designaunified-modal architecture UNIMO
which aims to process multiscene and multi-modal data
input with one model, including textual,
visual and vision-and-language data.
CMCL
接下来看下这个 CMCL 是怎么做的。
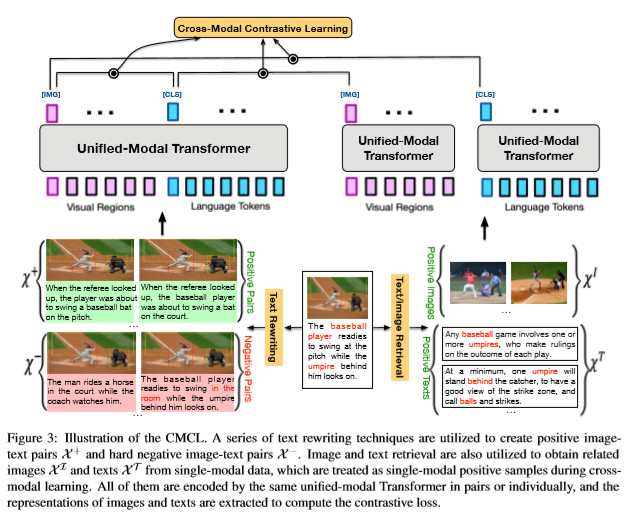
对于文本数据 $\mathrm{W}$ ,经过 BPE 分词后转换为 $\mathrm{W}={[CLS], w_1, …, w_n, [SEP]}$ 经过模型后获得深层语义表示 $h_{\mathrm{W}}={h_{[CLS]}, h_{w_1}, …, h_{w_n}, h_{[SEP]}}$ 。 图像 $\mathrm{V}$ 则需要经过 Fast R-CNN 提取关键区域的特征 $\mathrm{V}={[IMG],v_1, …, v_t}$ , 同样获得语义表示 $h_{\mathrm{V}}={h_{[IMG]}, h_{v_1}, …, h_{v_t}}$ 。 图像文本对 $(\mathrm{V}, \mathrm{W})$ 则是对两者进行拼接 ${[IMG],v_1, …, v_t, [CLS], w_1, …, w_n, [SEP]}$ 。 跟 BERT 一样, $h_{[IMG]}$ 和 $h_{[CLS]}$ 作为图像 $\mathrm{V}$ 和句子 $\mathrm{W}$ 的语义表示。 这样就可以把图像数据集 ${V}$ 、文本数据集 ${W}$ 、图像文本对 ${(V, W)}$ 编码到一个相同的语义空间内。 通过联合学习(joint learning)提高在这个语义空间上的任务。
跨模态对比学习
CMCL 的主要思想是使得成对的图像和文本在语义空间内拉近,非成对的在空间内拉远。 相比其他跨模态模型的做法,在做跨模态任务时,不仅需要简单的将图片和文本连接起来, 还需要将图像部分区域和文本部分文字建立起关系。
为此,论文在单词、短语和句子层次上重写(rewriting)了原始文本。 将这些重写的作为图像文本对的负例。 论文还在语料库中搜索到相似的图像和文本,这些图像和文本与原始图像和文本具有弱相关性, 不能作为图像文本对来进行训练,所以将其单独训练。 将这些正负例子使用对比学习进行语义对齐,对比学习的 loss 如下:
\[\mathrm{L}_{\mathrm{CMCL}}=-\mathrm{E}_{V,W}{-\mathrm{log}\frac{\sum_{(V^{+},W^{+}) \in \mathrm{X}^{(+,I,T)}} \mathrm{exp}(d(V^{+}, W^+ )/\tau)}{\sum_{(V',W') \in \mathrm{X}^{(-,+,I,T)}} \mathrm{exp}(d(V', W')/\tau)}}\]句子级别的重写可以直接使用回译。 在检索文本时使用 TF-IDF 向量计算相似度,查找最相似的文本。 对于短语以及单词级别的重写,首先将文本解析成为一个场景图(scene graph)。 用词汇表中不同的对象、属性、关系替换图内的对象、属性、关系。 这样不仅可以产生大量的负样本,还有助于文本和图像的对齐。
除此之外,作者还采用了检索的方法搜索了大量的相似图像和相似文本。 将检索到的图像和文本分别经过模型编码,然后提取表示进行跨模态对比学习 loss 计算。
图像的训练
图像的处理跟 BERT 相似,对图片中的区域进行随机采样,以15%的概率进行 MASK 。 因为图像中的区域通常是高度重叠的,所以通常选择重叠比例高的部分,以避免出现信息泄露。 具体做法是,在随机选择区域作为锚点(masking anchor),对与锚点重叠率大于0.3的区域进行 MASK 。 公式如下:
\[\mathrm{L}_{V}=\mathrm{E}_{V \in D}f_{\theta}(v_m|v_{\\m})\]对于图像文本对,则需要通过图像和文本的信息,对图像 MASK 的部分进行恢复:
\[\mathrm{L}_V=\mathrm{E}_{V,W \in D}f_{\theta}(v_m|v_{\\m}, W)\]因为视觉特征是高维且连续的,所以使用特征回归和区域分类能够学得更好的视觉语义特征表示。 特征学习的公式如下:
\[f_{\theta}(v_m|v_{\backslash m})=\sum_{i=1}^{M}||r(h_{v_i})-v_i||^2\]区域分类的计算:
\[f_{\theta}(v_m|v_{\backslash m})=\sum_{i=1}^{M}{\mathrm{softmax}(s(h_{v_i}), c(v_i))}\]文本的训练
文本的训练任务包括两个:双向预测(bidirectional prediction)和序列生成(sequence-to-sequence generation)。 训练时需要借助统一的 MASK 标识来控制预测任务。 在 MASK 时,最小的 MASK 单元是语义完整的短语。
在双向预测时,给定序列 $W={[CLS], w_1, w_2, …, w_n, [SEP]}$ , 按照15%的概率 MASK 文本片段。 跟 SpanBERT 一样按照几何分布进行采样。 被选中的部分80%被替换为 $[MASK]$ ,10%被替换为随机 token ,10%保持原始 token 。 训练计算公式如下:
\[\mathrm{L}_{\mathrm{Bidirectional}}=-\mathrm{E}_{W \in D}\mathrm{log}P_{\theta}(w_m|w_{\\m})\]在序列生成时,从序列中多次采样,直到达到25%。每次采样按照均匀分布采样。 所有被选择的文本从原文中删除,然后拼接作为目标序列。 剩余部分作为源序列。
\[\mathrm{L}_{Seq2Seq}=-\mathrm{E}_{(S, T)}\mathrm{log}P_{\theta}(T|S)\]实验部分
在预训练时,使用的文本语料库包括 BookWiki 和 OpenWebText (RoBEARTa), 图像集合包括 OpenImages 和无标签的 COCO, 图像文本对包括 COCO 、 Visual Genome 、 Conceptual Captions 和 SBU Captions 。
在预训练时, UNIMO-base 包括12层, UNIMO-large 包括24层,最大文本长度为512,最大图像长度为100。
base 和 large 模型分别从 RoBEARTa-base 和 RoBEARTa 开始进行训练,至少训练了500K步。
Adam优化器初始学习率为5e-5,并且学习率使用线性衰减。
base模型在使用16精度混合训练的情况下,使用32张32GB的V100训练了7天,large模型训练了10天。
有钱真好!
在以下几个下游任务进行了 fine-tuning :
CoQA:生成式对话型问答
SQuAD 1.1:问题生成
CNNDM:生成式摘要
Gigaword:句子压缩
SST-2:情感分析
MNLI:自然语言推理
CoLA:语言可接受性分析
SST-B:语义相似度分析
VQAv2.0:视觉问答
Microsoft COCO Captions:看图说话
SLNI-VE:视觉隐含
Flickr20k:图像文本检索
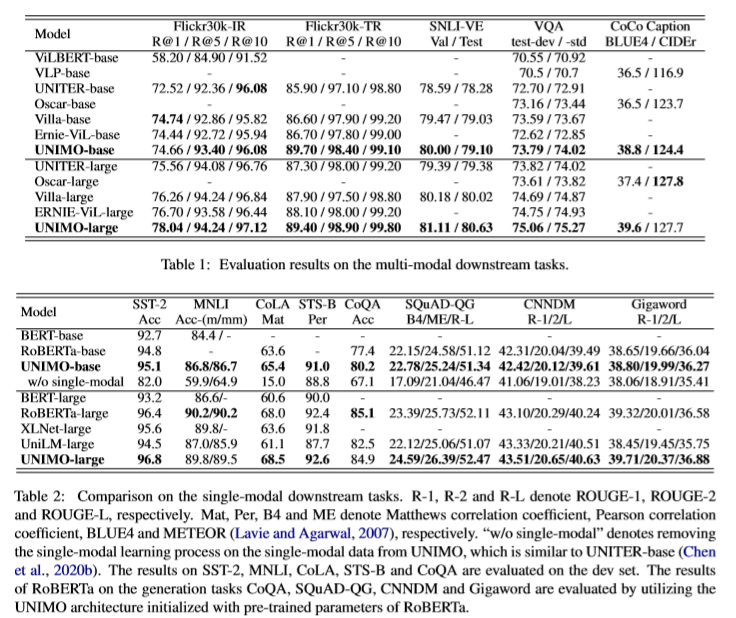
UNIMO 在所有的多模态任务上普遍超越了先前的结果,这一结果证明了统一模态学习体系结构的有效性。 在单模态对比实验上,加入了去除单模态训练的 UNIMO 模型进行了对比。 如图所示,加入去除单模态训练后反而使得模型效果大幅下降。 这说明多模态训练任务不能有效地适应单模态下游任务。 在单模态任务上相比其他预训练语言模型(BERT 、RoBEARTa 、UniLM),UNIMO 都取得了一定的提升。
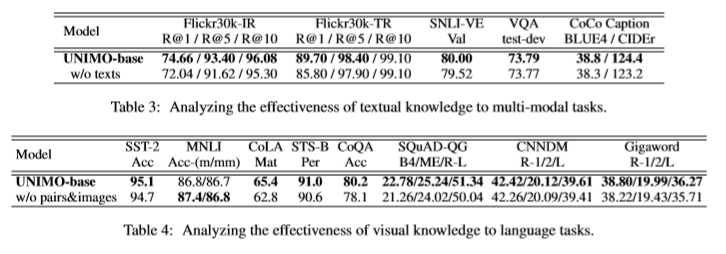
在去除文本训练的情况下,模型在多模态理解和生成任务上都持续下降。 说明文本训练有助于图像任务的效果。 在去除图像文本对训练任务和图像训练任务后,模型在单模态任务上与 BERT 和 UniLM 相似。 说明图像知识可以使模型在统一语义空间中学习到更健壮和可泛化的表示来增强文本的任务。
总的来说,这篇论文还是很强的。 虽说他声称自己灵感来自于生物,这就有点 CNN 的感觉了。 与其说是生物角度,不如说是之前很火的对比学习吧。 整篇论文像是多模态方向的 UniLM (包括模型名和实验都在对标 UniLM ), 想要建立一个统一形式的预训练模型。 但是在具体任务上应该是达不到 SOTA 的, 比如说生成式摘要任务在 CNNDM 上并没有超过微软 ProphetNet 的21.17, GSum 的22.32,SimCLS 的22.15。(NLP摘要任务的研究进展 )
话说,比赛开源的 UNIMO 模型是可以做中文任务的,论文也没提到中文任务的事情啊?!
咨询了一下竞赛负责答疑的人,说是中文语料不方便透露具体采用的什么。
应该是自己收集的语料吧。
Til next time,
gqjia
at 10:10
