
https://allenai.org/olmo
权重:https://huggingface.co/allenai/OLMo-7B
Dolma 数据:https://huggingface.co/datasets/allenai/dolma
arxiv: https://arxiv.org/abs/2402.00838
blog: https://blog.allenai.org/olmo-open-language-model-87ccfc95f580
github: https://github.com/allenai/OLMo
https://github.com/allenai/OLMo-Eval
https://github.com/allenai/open-instruct
OLMo和框架包括:
- 完整的预训练数据:预训练数据 Dolma数据集,包括 3 trillion token。分析预训练数据的 WIMBD。指令微调 Open Instruct 数据
-
训练代码和模型权重:模型的权重、训练日志、训练代码、消融实验、Weights & Biases训练指标、推理代码,每个模型至少训练了 2T token
- 评估工具:在 Catwalk 项目框架下完成。Paloma 评估基准
Paloma arxiv:https://arxiv.org/abs/2312.10523
数据集地址:https://huggingface.co/datasets/allenai/paloma
评估代码:https://github.com/allenai/OLMo-Eval
模型结构
模型在 Vaswani 的基础上,参考 PaLM 、LLaMA 、OpenLM 和 Falcon 做了改进。
模型大小和训练数据量如下:
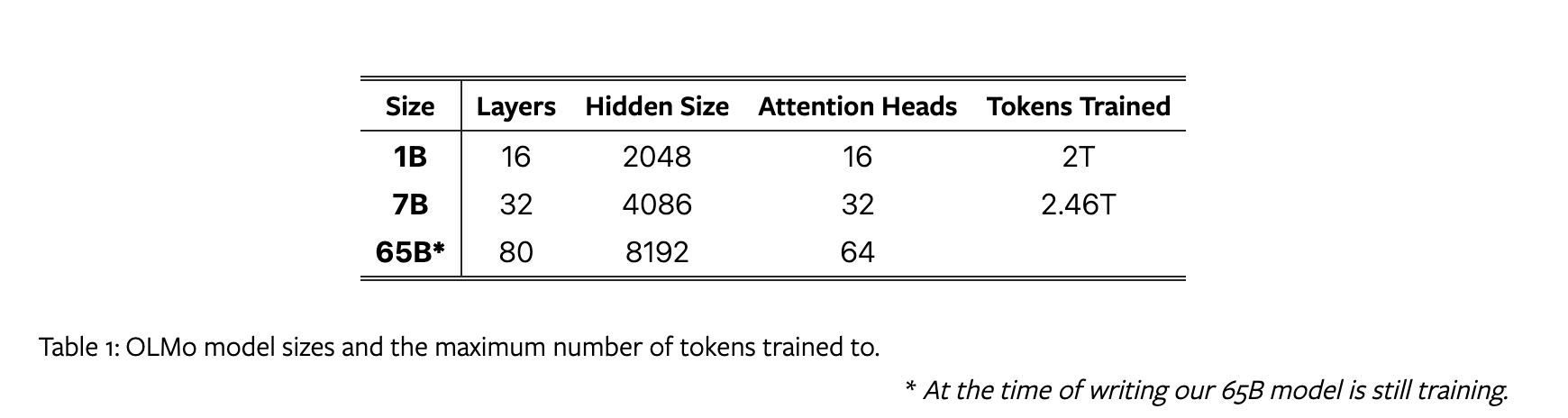
模型相比传统Transformer结构改动如下:
- 没有 bias:跟LLaMA、PaLM一样,去除所有的 bias,提高训练的稳定性
- Non-parametric layer norm:在 norm 时没有affine transformation,也就是没有 adaptive gain 或 bias。与 parametric layer norm 和 RMSNorm 相比,它的速度更快
- SwiGLU 激活函数:跟LLaMA 和 PaLM 一样。并且activation hidden size 跟 LLaMA一样约为 $\frac{8}{3}d$ ,但是将其增加到接近 128 的倍数以提高吞吐量(7B模型是11008)
- RoPE
- Vocabulary:基于 GPT-NeoX-20B 做了修改,增加屏蔽个人信息的额外 token,最终词汇表大小为 50280。为了最大化吞吐量,将其增加到 50304(128的倍数)
与LLaMA2、OpenLM、Falcon、PaLM对比如下:
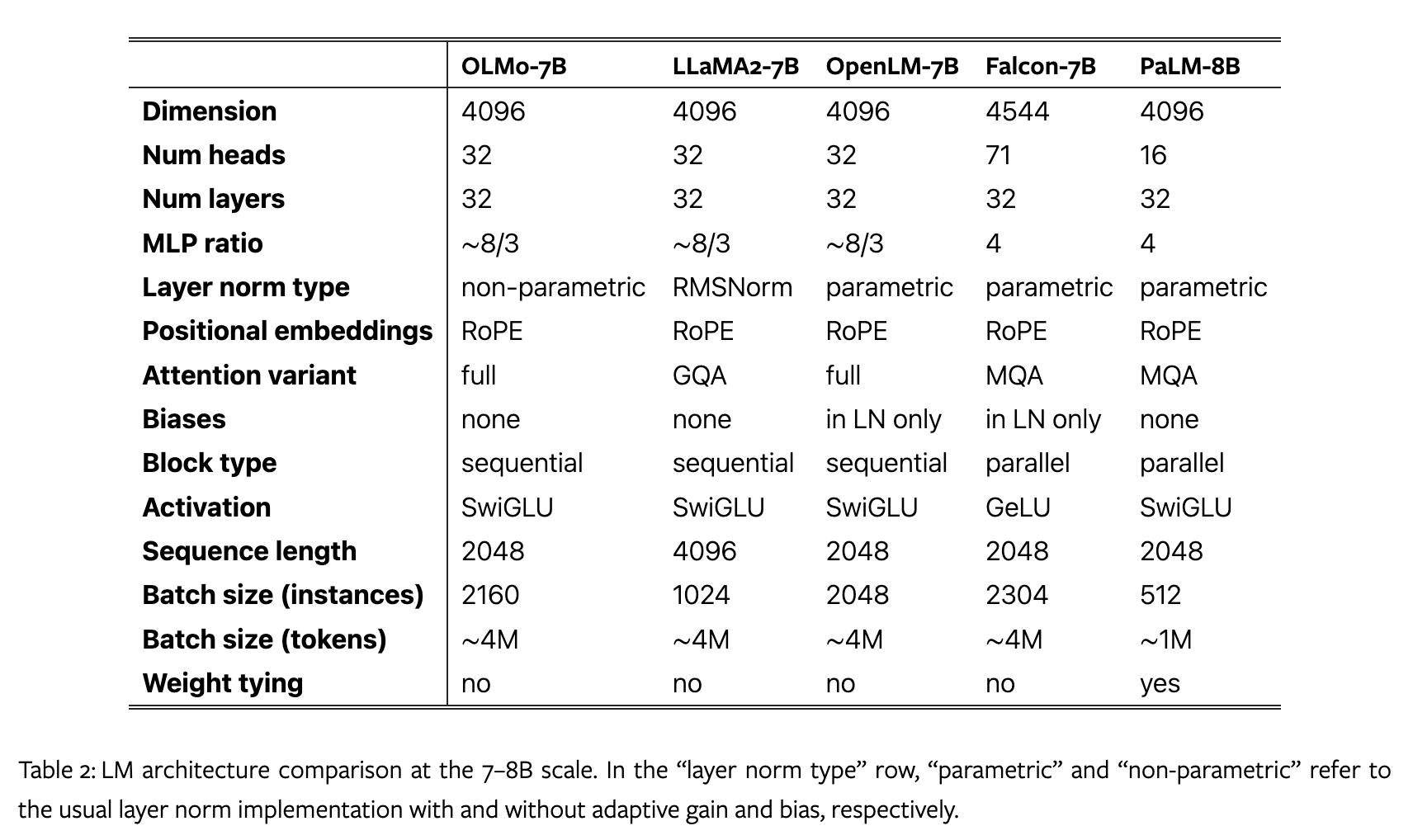
预训练数据集 Dolma
数据集通过(1)语言过滤;(2)质量过滤;(3)内容过滤;(4)去重;(5)多种来源混合;(6)tokenization 的流程构建。
开源了WIMBD工具进行数据集分析。
数据集组成如下:
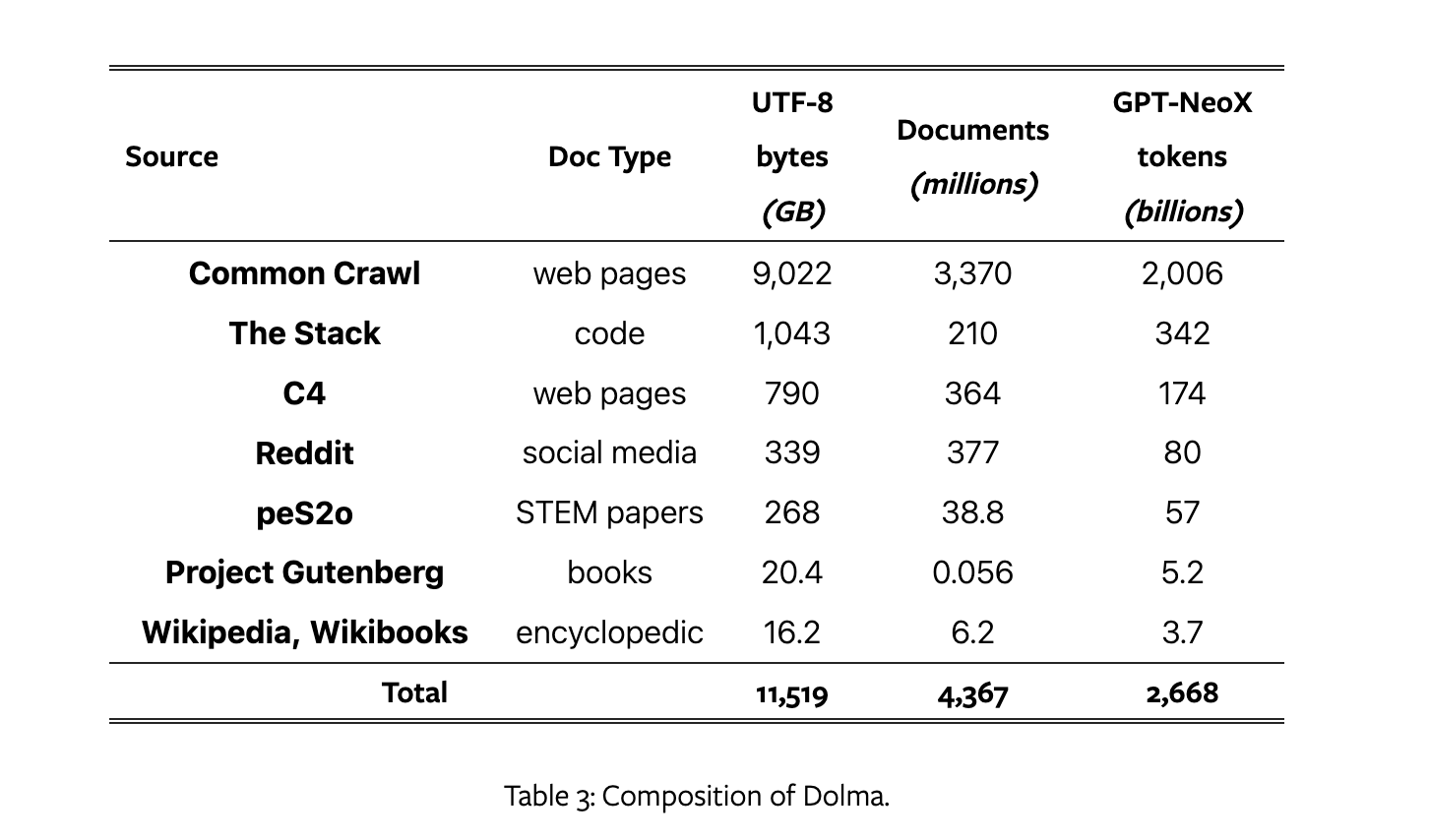
评估
online evaluation 在模型训练时进行评估,以便调整模型架构、初始化、优化器、学习率调度和数据混合。每 1000 training steps 或者 约 4B token 训练,进行一次评估。
offline evaluation 用Catwalk框架进行评估。使用 perplexity benchmark, Paloma
训练
分布式训练框架
使用 ZeRO 优化策略,通过 PyTorch 的 FSDP framework 训练模型。
7B规模下,每个GPU上 micro-batch size 为 4096 个 token。OLMo 1B 和 OLMo 7B 模型训练时设置了一个 4M 的恒定 batch size。OMLo 65B 从一个batch 开始预热,从2M个token(1024条数据)开始,每100B个token 翻倍一次,直到达到 16M token (8192条数据) 左右。
通过FSDP的内置设置和PyTorch的amp模块使用混合精度计算提高吞吐量。
训练设置
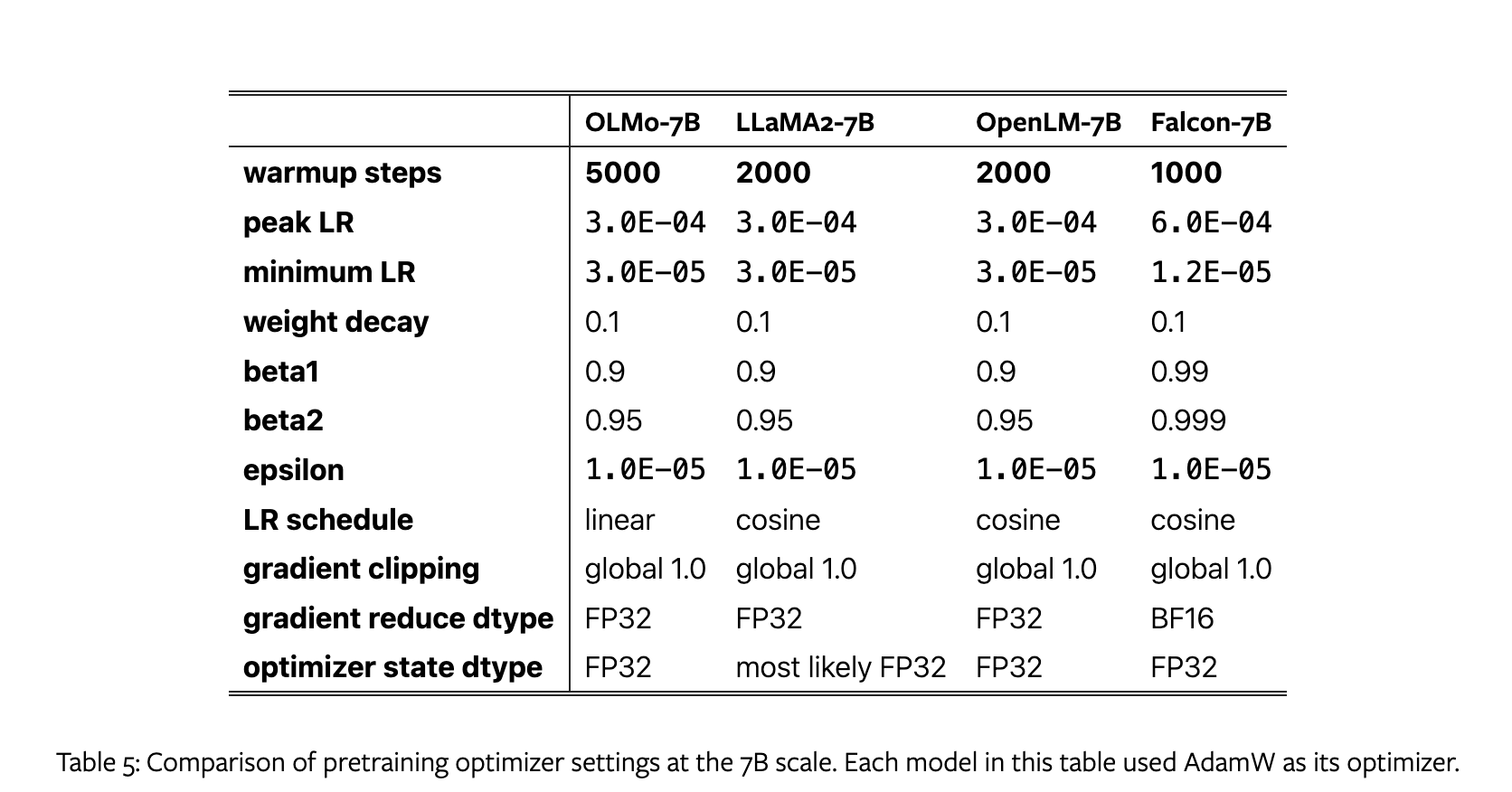
使用 AdamW 优化器,超参数设置如下:
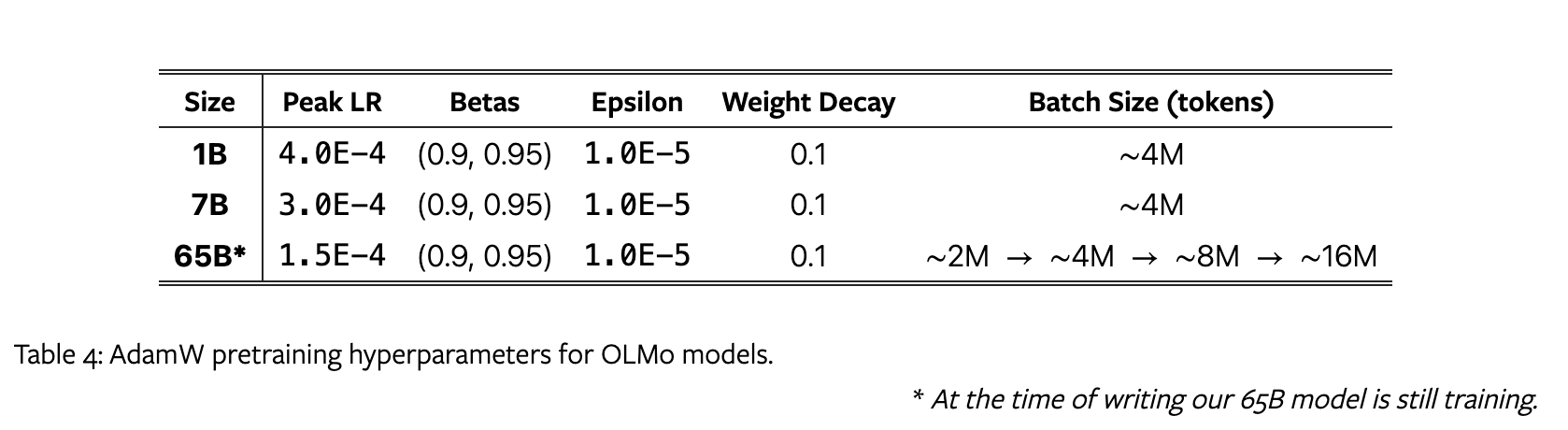
在5000个steps( ∼ 21B个token)内逐渐升高学习率,然后在训练的剩余部分中线性降低到峰值学习率的十分之一。
After the warm-up period, we clip gradients such that the total $l^2$-norm of the parameter gradients does not exceed 1.0.
During gradient clipping all of the model’s parameters are treated as a single big vector (as if all parameters were flattened and concatenated together), and we take the ℓ2-norm over the corresponding single gradient vector. This is the standard way to clip gradients in PyTorch.在梯度裁剪期间,将模型的所有参数视为一个大向量(就好像所有参数被展平并连接在一起),并对相应的单个梯度向量进行 ℓ2 范数。这是在PyTorch中裁剪梯度的标准方法。
OLMo和其他模型优化器设置如下:
数据在 tokenization后 在每个文档的末尾加上 EOS token ,然后拼接在一起。按照 2048个token拆分为训练数据。
有些模型通过不同的打乱顺序,开始了数据第二周期的训练。根据之前的研究,这样的影响很小。
模型在两种集群上进行了训练(代码在 NVIDIA 和 AMD GPU上都能无损使用):
- LUMI:256个节点,每个节点由 4个 AMD MI250X GPU和128GB 内存组成,由 800 Gbps 网络连接
- MosaicML:27个节点,每个节点由8个NVIDIA A100 GPU组成,内存为40GB,互连速度为800Gbps。
实验结果
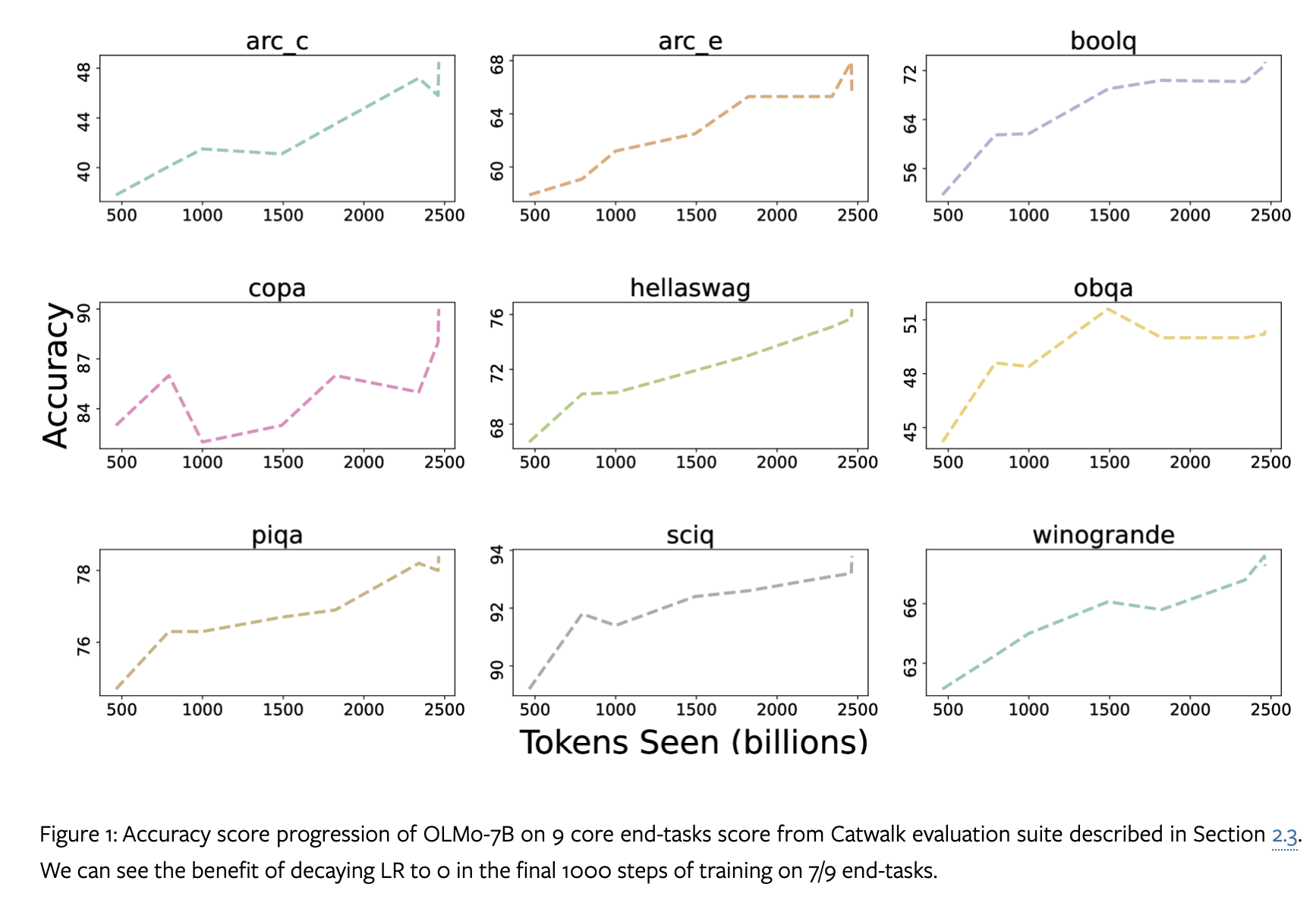
In our experiments, we find that tuning this checkpoint further on Dolma dataset for 1000 steps with the learning rate linearly decayed to 0 boosts model performance on perplexity and end-task evaluation suites described in Section 2.3.
作者发现将检查点在Dolma数据集上进一步调整1000步,学习率线性衰减至0,可以提高模型在困惑度和终端任务评估套件上的性能。
zero-shot:
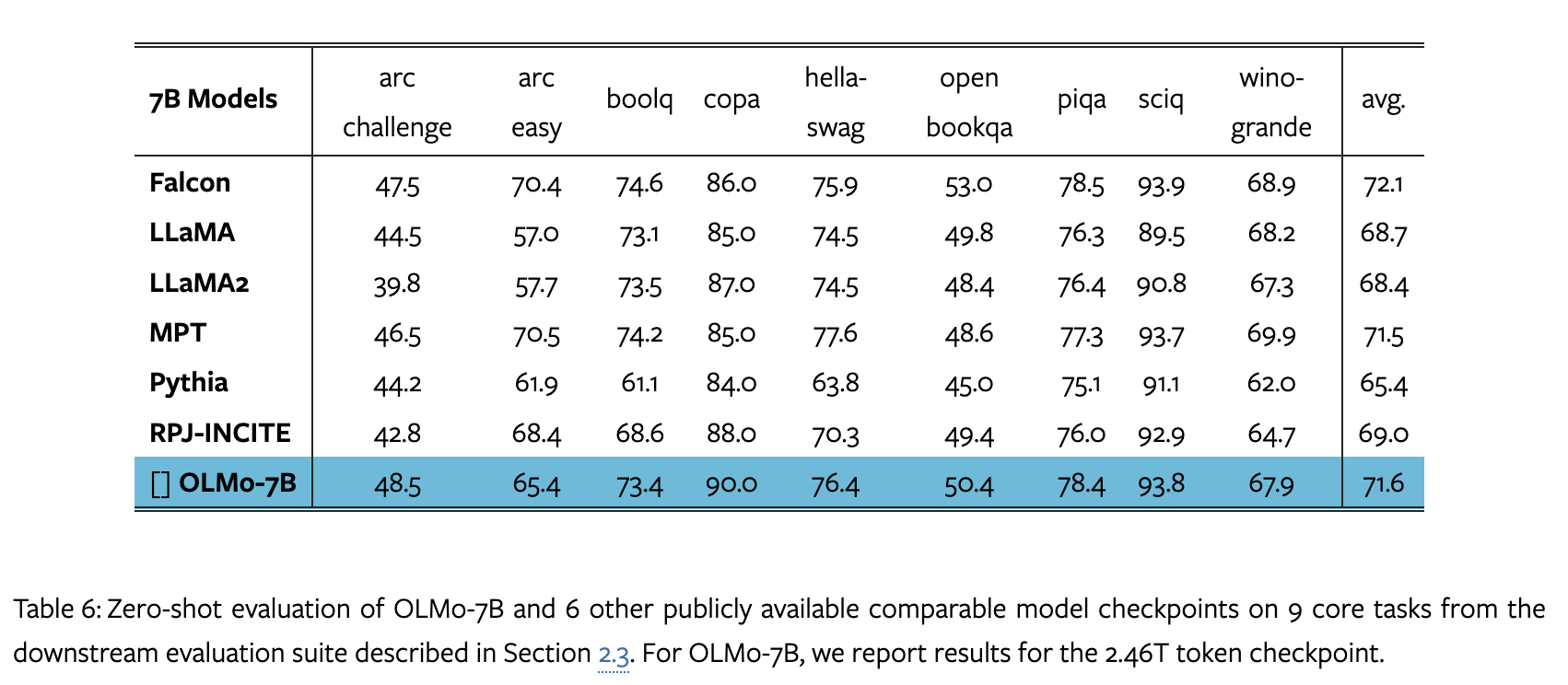
9个任务的准确度得分变化:
Til next time,
gqjia
at 00:00
