
arxiv:https://arxiv.org/abs/2309.12307
github:https://github.com/dvlab-research/LongLoRA/tree/main
作者提出了一种高效微调长上下文的方法。
与2048长度的上下文相比,8192的训练需要16倍的训练资源。
作者的方法包括两个方面:
- 使用稀疏的局部注意力(移位短注意力 $S^2$-Attn)代替稠密的全局注意力。可以实现上下文扩展、节省计算资源、具有与传统注意力微调相似的效果。训练阶段只需要两行代码实现,推理阶段可以选择使用或者不使用。
- lora在上下文扩展上表现良好。
全量、lora和longlora之间性能和效率的比较:
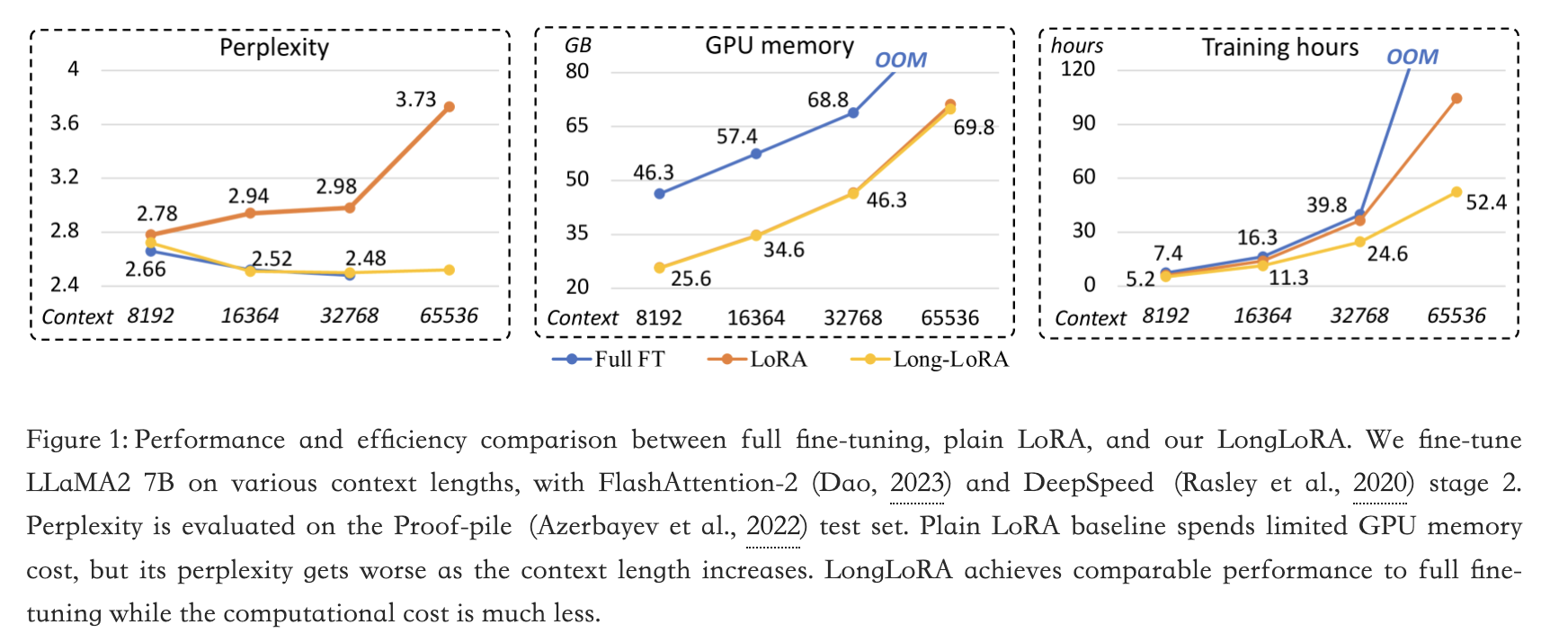
LoRA通过利用低秩矩阵修改自注意力块中的线性投影层,通常具有高效和减少可训练参数数量的特点。然而,作者实验发现,以这种方式训练长上下文模型既不够有效也不够高效。
longlora注意力:
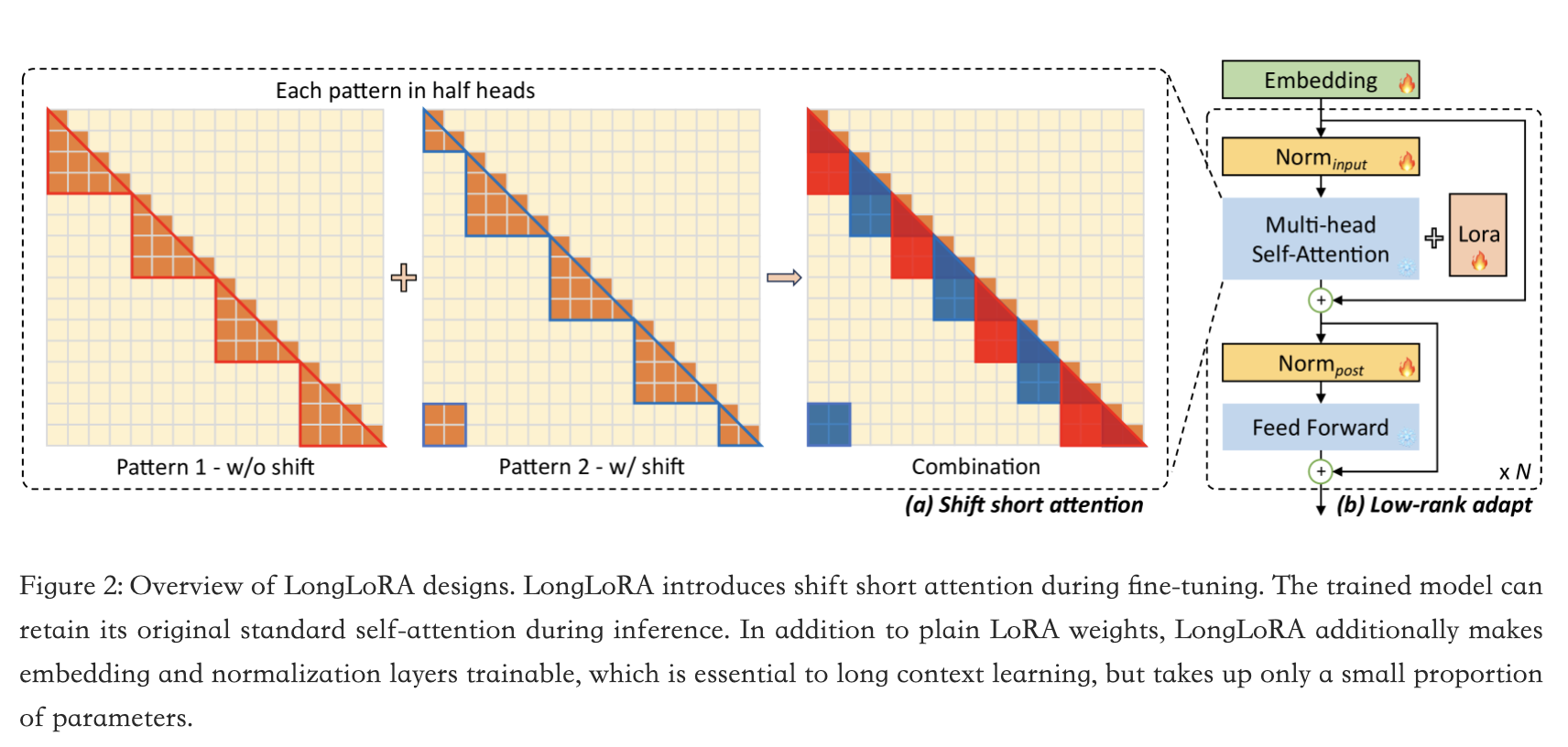
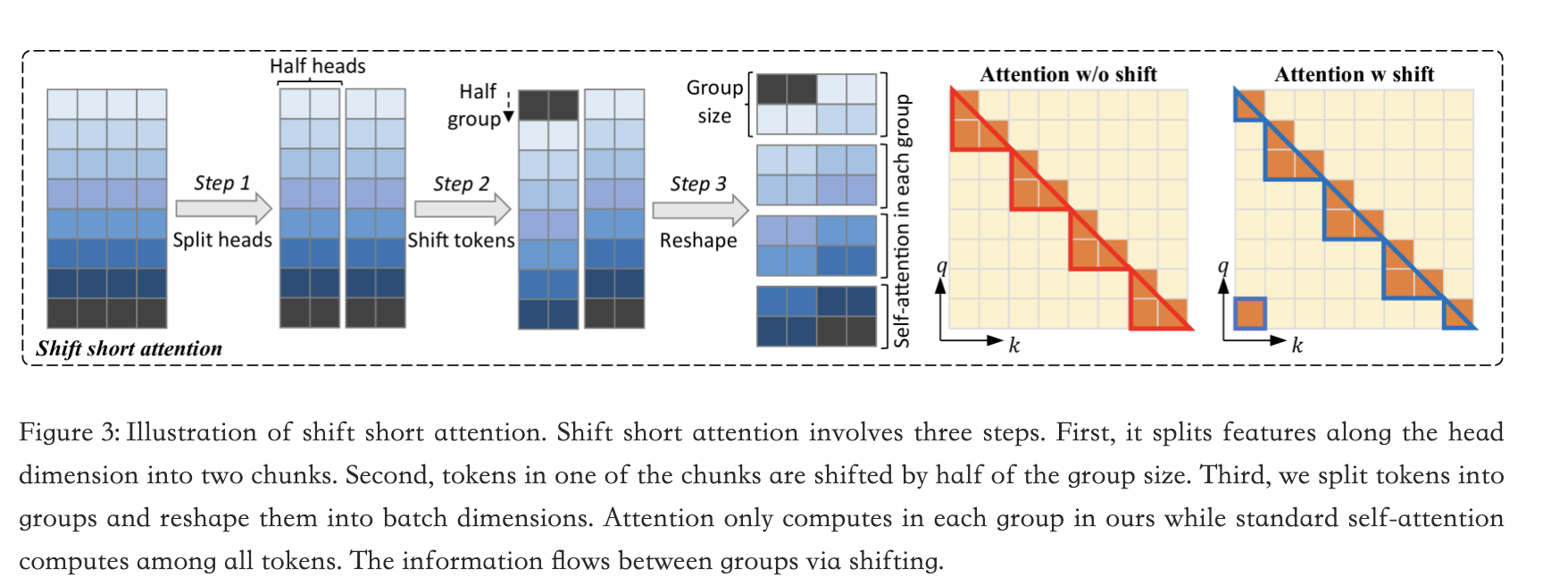
将上下文长度分成几个组,并在每个组中进行注意力计算。在一半的注意力头中,我们将标记向后移动半个组的大小,以确保相邻组之间的信息流动。
通过S 2 -Attn微调的模型在推理过程中保留了原始的注意力架构。
位移短注意力示意图:
Til next time,
gqjia
at 00:00
