
今年的 EMNLP 出了一篇讲使用对比学习做事实一致性的文本摘要任务的论文。
CLIFF: Contrastive Learning for Improving Faithfulness and Factuality in Abstractive Summarization
论文来自密歇根大学,作者是 Shuyang Cao 和 Lu Wang 。
利用对比学习提高生成文本的真实性确实是一个不错的思路,这里详细看下这篇论文是怎么做的。
论文概述
使用最大似然的训练目标可以生成流畅的文本,但无法确保模型能够区分参考文本中正确和错误的文本。
当前解决生成摘要中事实不一致目前有三种方法:
- 使用一个额外的组件对其进行纠错
- 使用去除噪声数据后的训练数据进行训练
- 修改 Transformer 结构
为此需要解决两个难点:
- 需要设计一个合理的训练目标避免引入负例样本的同时降低模型生成效果
- 需要构建“自然”的负例样本
为此论文设计了一个针对特定任务的对比学习优化计算公式,四种生成文本的策略。
CLIFF
论文设计了一个基于对比学习的文本摘要训练框架,文章x包含一组参考摘要P和一组错误摘要N,对比学习的优化目标为:
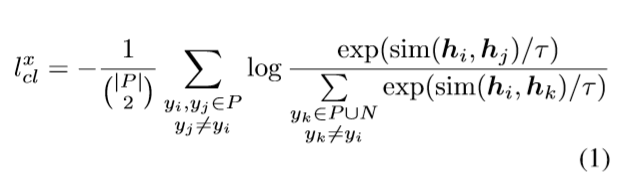
- $h_i$ 、$h_j$和$h_k$ 代表摘要$y_i$ 、$y_j$和$y_k$ 的语义表征
- $sim(.,.)$用于计算余弦相似度
- $τ$为超参数,默认设置为1.0
损失函数由交叉熵损失和对比学习损失函数组成:
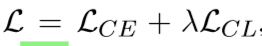
摘要文本的表征
获取解码器的最后一层输出,并通过 spaCy 获取到所有的实体和其他解析结果。
摘要文本有三种表示方式:
-
对所有 token 表征进行平均
-
对所有命名实体 token 表征进行平均
-
最后一个 token 的表征
在获取表征之后加上一个隐层的 MLP 计算得到最终的$h_∗$。
正例数据的处理
正例样本构建策略:
- 同义词替换
- 语言模型预测并替换被随机 MASK 的词
- 反译(保留更全的语义的同时能提供更多的语言变体)
负例数据的处理
方案1 :替换实体 SWAPENT
替换实体主要是模拟内部幻觉。将参考摘要中的实体与其他参考摘要中的实体进行替换。只有相同类型的实体进行替换。SWAPENT 不依赖于任何模型,但是这一方法只针对内部幻觉而没有覆盖到外部幻觉。
方案2 :使用 BART 模型填充 MASK
MASKENT
使用 MASK 和 BART 编码替换参考摘要中的每个实体。使用没有进行任何微调的 BART 对 MASK 进行预测。只保留至少存在一个与源文本和参考摘要都不存在的实体的摘要。
MASKREL
到目前为止,这两种引入策略都侧重于不正确的命名实体。为了涵盖更多多样化的外部和内部错误,本文对这一策略进行扩展到实体关系。本文将这一策略称为 MAKREL 。
先通过 Stanza 获取实体关系三元组$ <gov,rel,dep>$。将 gov和 dep 包围的起来的名词短语同样使用 MASK 替换。只有包括与源文本和参考文本中都不包括的实体关系的生成文本才会被保存。
与其他策略相比, MASKENT 和 MASKREL 都可以产生更多的外部幻觉。因为这些负样本是在没有源文本的基础上产生的。这样构建的负样本很容易包含与源文本不同的主题,这样也会导致模型训练效果差。
方案3 :条件文本生成
REGENENT
将参考摘要每个命名实体前的文本视为 prompt。使用 BART 和 PEGASUS 微调后,使用编码器读取源文本,将 prompt 作为解码输出的前部分。如果生成文本引入新的实体则保留。
GERENREL
将处理片段从实体拓展到实体关系组。如果生成文本引入新的依赖关系则保留。
这样的方法产生的样本比方案2与源文章更加相关,但是仍然会错过一些类型的错误,不能涵盖真实场景下出现所有错误。
方案4 :使用模型生成 SYSLOWCON
使用 BART 和 PEGASUS 在训练集上进行微调和解码。检查每个生成摘要与原文本的可信度,低于阈值的标记为负例。
评估指标
QuestEval
给定一篇文章和摘要,首先根据两者之间共有的的实体和专有名词生成问题。使用一个QA模型使用文章回答来自摘要的问题,得到第一个分数。使用摘要回答来自文章的问题,得到另一个分数。将两个分数取调和平均,得到QuestEval的分数。与人工对一致性的判断有很高的相关性。
FactCC
判断摘要与文章是不是蕴含关系。
ROUGE-L
经典的ROUGE指标,用于判断生成文本是否流畅。
对比实验设计
CRSENTROPY 使用交叉熵损失。
ENRAILRANK 使用FactCC分数在解码时对beam得分进行重新排序。
采用三种策略提高生成文本的真实性:
-
CORRECTION 单独微调一个BART修正摘要中的错误
-
SUBSETFT 在一个去除错误的训练数据集上微调模型(XSum)
-
FASUM 结合知识图谱修改Transformer,以实现事实一致(CNN/DM)
诚然将likelihood作为训练目标,能得到强大的具有语言理解能力的模型。但是将似然作为目标会导致语言的平淡和奇怪的重复。而且基于强大的GPT2-117M,使用beam search,理论上beam size越大,生成的句子概率越大,效果越好才对。但事实却是反直觉的,beam size越大,语言的退化效果更明显。
对比非似然训练(unlikelihood training),将非似然训练目标与交叉熵使用相同的权重进行微调:
\[loss_{ull}=-\sum_{t=1}^{|y'|}log(1-p(y'_t|y'_{1:t-1},x))\]FCSAMPLE 负例策略结合FactCC分数。
BATCH 在训练时每个batch使用其他数据作为负例。
实验
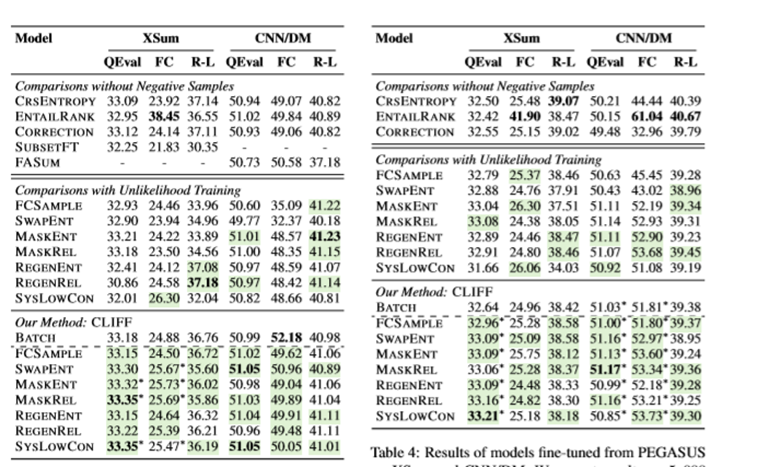
CLIFF在使用摘要的表征时使用MLP计算得到所有token表征的平均。与其他提高模型事实一致性的策略相比,几乎所有的CLIFF模型在QuestEval上都取得了更高的分数,在XSum上更为明显。CLIFF模型的ROUGE分数与使用交叉熵训练的基线相当或者更好,在CNN/DM数据集上。FactCC也具有类似的趋势,特别是是在使用PEGASUS作为基础模型时。
ENTAILRANK倾向于生成更高的FactCC分数,相比其他使用交叉熵的基线在QuestEval。经过人工检查发现,ENTAILRANK在每个beam可以挑选出FactCC得分高的词,而不会提高真实性。
基于后矫正的FASUM只提供增量收益,SUBSETFT明显牺牲了ROUGE的得分。总体而言,CLIFF具有更高的通用性。
相比非似然训练,CLIFF具有更为有效也具有更高的鲁棒性在两个数据集上使用了七种负样本构建的方式。CLIFF在14个比较中有12个取得了更高的QuestEval分数使用PEGASUS时,CLIFF也有11种取得了更高的分数。在FactCC和ROUGE-L上也有类似的趋势。
CLIFF在抽象程度更高的数据集上取得了更好的效果。负例不仅提高了FactCC在两个数据集上的得分,而且提高了ROUGE-L。这说明系统生成的摘要创造了更多错误,特别适合使用CLIFF。使用关系创建的负例取得更好的效果,后续可以将实体驱动的方法引导到更注意关系的方向。
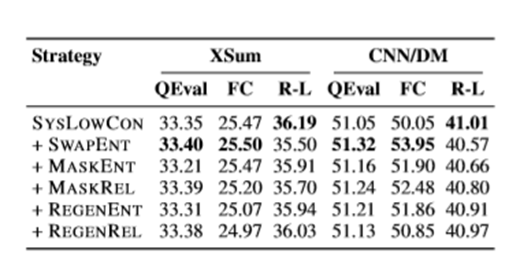
组合策略,结合SYSLOWCON和其他策略,比任何单一策略训练的负样本模型获得更好的QuestEval分数(MASKENT和REGENENT除外)。这说明在负样本中覆盖不同类型错误的重要性。
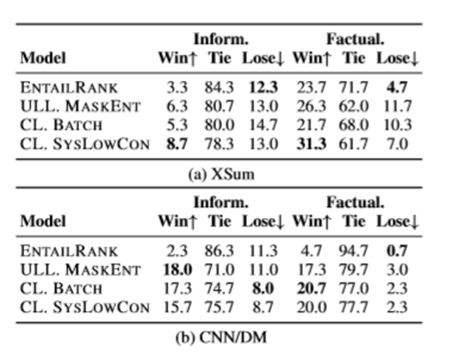
在信息含量和事实一致性方面优于、等于、低于CRSENTROPY。在抽象程度更高的数据集XSum上,低置信度的CL方法在信息和事实一致性上取得了更好的评价。CLIFF采用了BATCH和SYSYLOWCON两种方法设计。
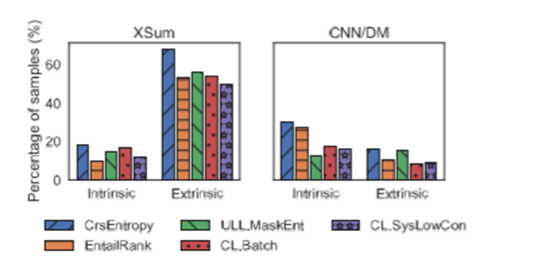
在CNNDM上所有使用负例的模型都能产生信息量和真实性高的文本。相比之下,ENTAILRANK摘要和CRSENTROPY两个数据集上的输出区别更小。
在生成摘要的错误方面,CL减少了两种错误比ULL更为有效观察发现生成摘要在世界知识上也有一定的减少。
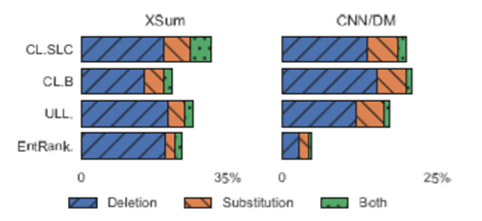
对CRSENTROPY,采用人工标注判断是否删除/修改了不正确的内容。使用CL在使用专用名词和数字替换错误上比 ULL 和 隐含信息重新排序 更加频繁。
数据如何表示对于CL来说很重要。这里就需要回答两个问题:
-
使用所有的token还是部分token?
-
是否需要MLP?
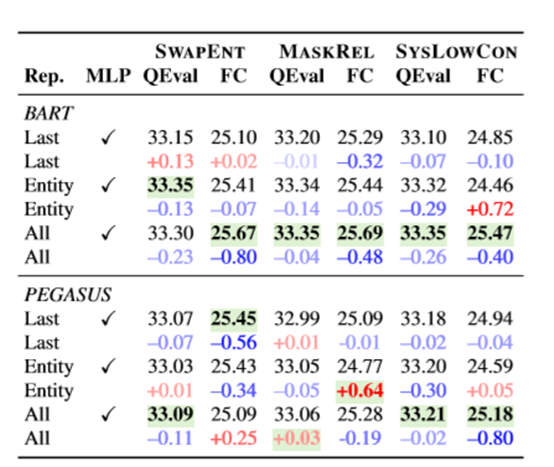
根据实验,采用所有token表征的平均和MLP能取得最好的效果。
Til next time,
gqjia
at 10:03
