
论文地址:On Faithfulness and Factuality in Abstractive Summarization
论文来源于谷歌研究院。
一般进行文本生成任务时需要使用似然训练(likelihood training)和近似解码(approximate decoding objective),而这两者会使得模型产生不自然的文本。这篇文章对生成摘要中不忠实于输入文档的现象进行了研究。论文中将摘要中不忠实于源文档的部分称为幻觉(hallucinate)。
什么是幻觉(hallucinate)?

就以论文中的例子来说,TCONVS2S生成的摘要中提到了“Former London mayoral candidate Zac Goldsmith” ,这在原文中是没有提到的。同样的的还有TRANS2S生成的“Former London mayor Sadiq Khan”。除此之外,PTGEN中的“UKIP leader Nigel Goldsmith”,以及 GOLD summary 中的“2016”都属于错误的信息,都被称为幻觉。
文章中将错误来源于输入文档的幻觉称为内部幻觉(intrinsic hallucination),它将输入文档中的信息错误表达,产生不忠实于输入文档文本。而将信息来源于输入文本以外的称为外部幻觉(extrinsic hallucination)。“Former London mayoral candidate Zac Goldsmith” 和“Former London mayor Sadiq Khan”都属于内部幻觉,“UKIP leader Nigel Goldsmith”和“2016”属于外部幻觉。
这里文章提到了一点,输入文档质量差会导致内部幻觉,包含信息很少的解码器无法处理源文本和目标文本的分歧,容易产生外部幻觉。
当然幻觉都不一定都是错误的,有些幻觉包括源文本中不存在的信息,但是又是真实的,这类幻觉称为真实幻觉(factual hallucination)。
幻觉一定是不好的吗?
如果是自由文本生成任务,就需要大量的幻觉存在,但是如果是自动文本摘要的任务,这种幻觉的存在就没那么必要了。
但也不是说完全忠实于输入文档。构建摘要的时候需要一定的背景知识,而且文档编写者和摘要编写者的表达风格也存在一定的差异。尤其是一些面对特定受众的摘要,必须要平衡好作者跟读者的理解。
针对幻觉的分析
文章从四个方面对自动摘要存在的幻觉进行了研究:
- 生成式摘要模型生成幻觉的概率有多少?
- 模型生成幻觉的信息是否来源于输入文本?是内部幻觉还是外部幻觉?
- 有多少幻觉是真实的但不忠实于源文本的?
- 如何评测事实不一致的文本?
为此文章选择 XSum 数据集进行研究,主要包括三方面的原因:
- 短的摘要相比长的摘要更容易标注和分析
- 这个数据集只适合做生成式摘要
- 如果短的摘要存在幻觉问题可以推断出长的摘要也存在这个问题
在分析的摘要包括数据集的 gold summary 以及 PTGEN、TCONVS2S、GPT-TUNED、TRANS2S、BERTS2S 生成的摘要。
自动评估视角下的摘要质量
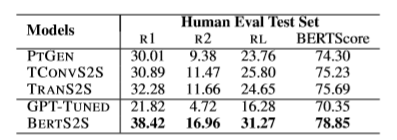
从 ROUGE 和 BERTScore 来看,使用预训练的 BERTS2S 比其他模型要好的多。PTGEN 、TCONVS2S 和 TRANS2S 这三个没有使用预训练的模型表现比较相近。这说明预训练对于模型效果的提升是很显著的。
摘要模型产生幻觉的概率
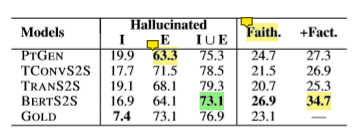
文章采用人工标注将摘要中幻觉片段全部标出,并判断幻觉属于内部幻觉还是外部幻觉。
根据标注结果可以看出来,模型普遍存在大量的外部幻觉。而且 gold summary 也存在大量的外部幻觉,这是这个数据集本身具有的特点。而且摘要原本就是需要根据原始输入文档和外部背景等因素共同生成。
有趣的是即使是 gold summary 也存在7%的内部幻觉。而这也往往是因为摘要编写者拥有输入文档中没有包括的背景知识得到的。文章给出的例子是,一篇报道可以描述一个跟“奥巴马”和“美国总统办公室”有关的事件,但是单纯从文档中并不能推断出“奥巴马是美国总统”,但是有背景知识的摘要编写人有可能使用“奥巴马总统”这样的表述。
模型生成摘要在内部幻觉的比例大于 gold summary ,文章给出的解释是模型缺少文档级的理解和推理,容易产生错误的表达。PTGEN 因为使用了覆盖机制(copy mechanism)可以从原文中复制信息,使得它的外部幻觉相比其他模型较少(63.3%)。但是由于覆盖机制缺少推理的能力,会使得生成与原文不相符的摘要(19.9%)。相比其他模型,使用预训练语言模型的 BERTS2S 产生更少的外部幻觉(16.9%)。
BERTS2S 产生幻觉的比例是最少的(73.1%)。相比其他模型甚至 gold summary ,BERTS2S 更加保守,在ROUGE上的得分也更接近 gold summary。预训练使得 BERTS2S 更加了解文档所在的领域,能够产生更少的语言模型上的错误,生成忠实度更高的摘要。
模型产生真实幻觉的概率
文章同时对摘要中的幻觉片段进行分析,标注出哪些是真实的哪些不少真实的。结果见上一部分的表,“Faith”代表忠实于输入文档的摘要所占的比例,“+Fact”代表忠实于输入文档和真实但不忠实的摘要所占的比例。文章没有对gold summary 的真实性进行分析,默认全部真实。
预训练能够帮助模型生成更多真实的摘要(34.7%)。但是预训练生成真实但不忠实的比例也是最高(7.8%)。虽然 PTGEN 外部幻觉只有63.3%,但是 BERTS2S 有6.6%的外部幻觉是真实的,而 PTGEN 只有2.2%。因此如果把真实但不忠实的摘要算作可以接受的摘要时,可以认为 BERTS2S 产生的无效的外部幻觉低于 PTGEN 。
BERTS2S 表现的效果要好的原因可能是由于模型在预训练阶段能够接触到大量的文本。但是即便如此,BERTS2S 超过 90% 的幻觉是错误的。
评估幻觉的方法
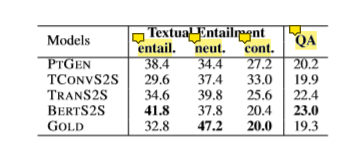
文章使用文本蕴含和问答两种语义推理的方法对生成摘要进行评估。
在文本蕴含方法上,直接使用 BERT large 在 Multi-NLI 数据集上训练了一个分类模型,将文档和摘要的关系分为包含、中立和矛盾。
BERTS2S 生成的摘要,包含关系的比例最高,甚至高于 gold summary 。与外部幻觉的表现一致, TCONVS2S 矛盾的比例也是最高的。gold summary 拥有最高的中立比例,相比之下 BERTS2S 的摘要更依赖于文档。原因可能是摘要编写者更倾向于添加感情色彩和大量有效的外部幻觉。
在问答方法上,使用一个问题生成的模型和一个答案抽取的模型生成问答对,最后使用一个阅读理解的模型回答这些问题。文章假设一个可靠的模型生成的摘要只包含文档的信息。依据这个假设可以认为,能用摘要回答的问题也可以用文档进行回答。
在这一评估方法下,BERTS2S获得了最高的分数,而 gold summary 的得分反而最低。
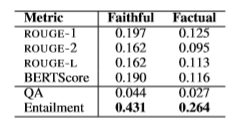
文章使用 spearman 对这几种评估方法与人工评价进行比较。
研究发现文本蕴含的方法在忠实度(0.431,中等程度相关)和真实度(0.264,弱相关)上相关程度最高。相比之下 ROUGE 和 BERTScore 的关联程度非常弱。问答的相关性是最弱的,只有0.431和0.264。原因可能是因为问题生成模型被用来从摘要中生成问题而不是人工编写的。而且在输入的摘要包含幻觉的情况下问题生成模型也很容易生成幻觉。文章假设原文和摘要相匹配的方法对于XSum数据集来说比较困难。文章认为使用更好的问题生成模型和更好的一致性度量方法可以缓解上述问题。
使用文本蕴含进行模型选择
使用文本蕴含可以判断生成文本是否忠实,但是这种方法也是存在问题的,它不依赖于参考文本,容易被“欺骗”(比如说采用文档的首句作为摘要)。需要跟 ROUGE 这种依靠参考文本的度量相结合使用。
因为这一方法不需要依赖参考文本,因此可以用来做模型选择或者在解码阶段使用。文章对前者进行了研究。
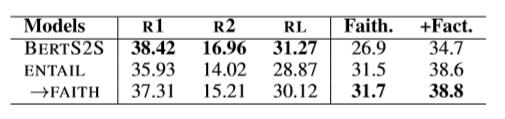
文章按照评估方法从 PTGEN、 TCONVS2S、TRANS2S、BERTS2S 四个模型生成的摘要中选择得分最高的摘要作为最终的摘要。
可以看出依据文本蕴含的方法选出的摘要在忠实度和真实度上都高于BERTS2S。但是在这样的情况下,ROUGE得分却低于BERTS2S。
文章进一步训练一个新的文本蕴含模型。采用评估阶段产生的数据,将标注为“忠实”的数据设置为“包含”,其他设置为“矛盾”。按照表中的结果在忠实度和真实度上有了一点提升,在ROUGE上明显高于前一个模型。因此可以认为这个模型一定程度平衡了ROUGE和忠实度/真实度。
结论
经过研究,论文提出的结论如下:
- 70%的单句摘要中都存在幻觉。
- 大部分事实不一致属于外部幻觉。
- 90%的外部幻觉是错误的。因此大量的摘要文本中存在事实不一致的现象。根据测试预训练模型是表现最好的,但是也生成了很多幻觉。
- ROUGE 和 BERTScore 与真实性和忠实性关联不大,因此需要更好的度量方法。文章尝试使用了文本蕴含模型进行度量。
Til next time,
gqjia
at 09:51
