
论文讨论了如何让模型具备更好的外推性,为此作者提出了一个简单的改变位置表示方式的方法ALiBi(Attention with Linear Biases)。ALiBi 不会增加位置编码(position embedding)到词嵌入(word embedding)中,它是通过 对 QK 注意力分数做一个与距离正相关的惩罚的偏置。这个惩罚会让那个模型在计算注意力分数的实际更加关注距离近的位置信息,减少对远距离位置信息的关注,从而改善模型在处理长序列的性能。这种方法通过调整注意力分布,以更好地适应不同长度的输入序列,实现了外推能力。
作者用ALiBi的方法训练了一个1.3B的模型,训练数据长度采用1024,在推理时可以将长度外推至2048。这个模型与采用2048训练长度、采用正弦位置编码的模型在2048长度上具有相同的困惑度。而且ALiBi的训练速度更快,内存占用更低,比后者快11%且占用内存少11%。
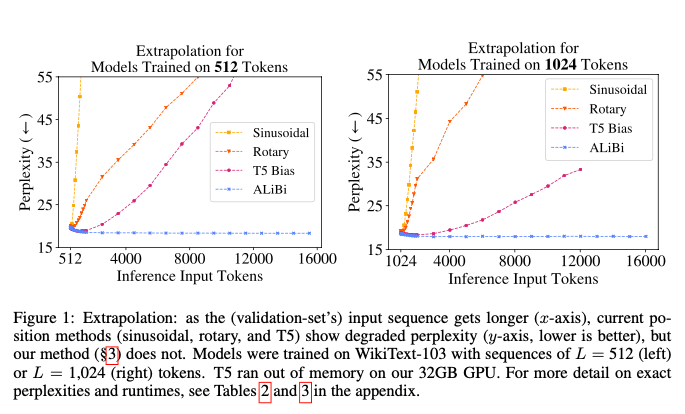
跟 sinusoidal 、 rope、T5 bias 相比 alibi 在困惑度上一直保持一个较低的值。
alibi计算过程

算法的核心是在注意力分数计算时,在Q、K计算内积时加上一个相对距离的矩阵,这个矩阵需要乘以一个坡度。
坡度的计算,论文中的描述如下:

当遇到m个头的情况,坡度分别为$\frac{1}{2^{\frac{8}{n}}} …\frac{1}{2^{\frac{8}{1}}}$。
实验
在WIKITEXT-103 和 TORONTO BOOKCORPUS的效果
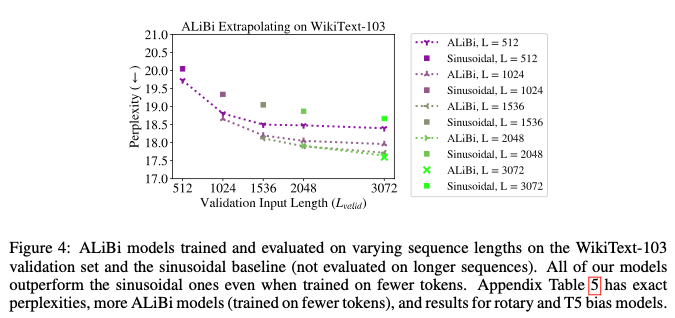
作者在 WikiText-103 数据集上验证了 AliBi 和 sinusoidal,前者普遍好于sinusoidal基线。
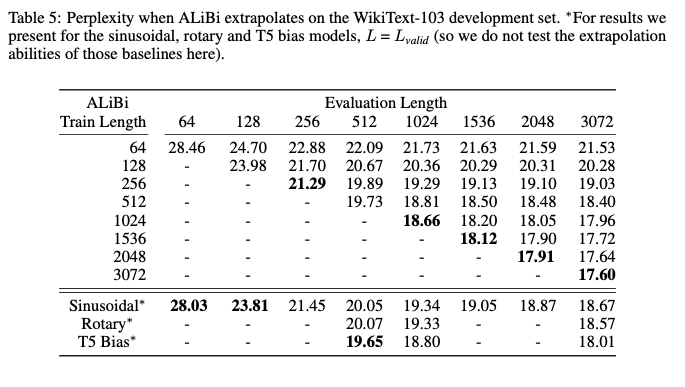
作者在不同输入长度训练后,测试不同输出长度的PPL。无论哪个长度,ALiBi的优势都非常明显。
在 CC100 和 ROBERTA CORPUS 的效果
作者研究了 ALiBI能否应用在更大的数据集上。实验表明在一些比较有难度的任务上,ALiBi与 sinusoidal 有相似的效果。但是 ALiBi 使用了更短的序列长度,使用内存明显更小。
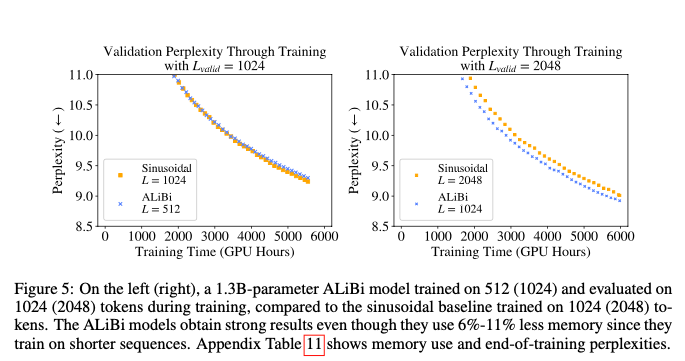
作者比较了在训练过程中,两者在验证集上的困惑度,ALiBi在整个训练过程度都好于 sinusoidal ,而且训练速度更快,内存越少。
作者指出,因为ALiBi可以使用更少的内存,意味着可以堆叠更多的层以进一步提高性能。这里作者病没用给模型加额外的层。
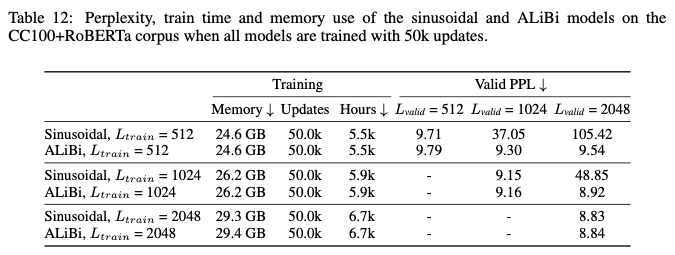
在相同的序列长度上训练,ALiBi 与 sinusoidal 相似。这与前一个实验结果不同,这说明ALiBi可以在少资源的场景中有更好的表现。
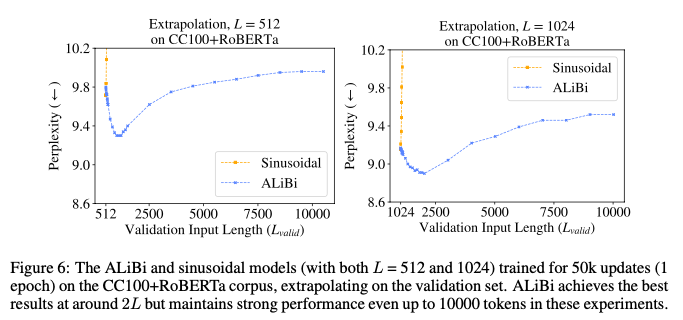
实验表明,当推理长度是训练长度两倍的时候,模型能取得最好的效果。L = 512模型在Lvalid = 512时获得9.79的困惑度,但在推断到1012令牌时达到最佳得分(9.3);而L = 1024模型在Lvalid = 1024时获得9.16的困惑度,在推断到2024令牌时得分最佳(8.9)。这可能是因为模型在训练期间观察到的子序列长达L令牌,而在推断2L长度的子序列时,模型处理的一半子序列与训练期间看到的示例一样长。当在2L + 1或更长的子序列上进行推断时,模型做出的不到一半的预测是在训练期间看到的长度上,这可能会降低性能。而 sinusoidal在 超过训练长度时候就已经无法进行正常推理。
Til next time,
gqjia
at 00:00
