
作者: 耶鲁大学 Yixin Liu
LLMs 在解决数学问题上一直存在问题,而且在 “一次就能通过” 和 “N次能通过” 之间存在巨大的差距。这表明 LLMs 已经倾向于找到正确的答案。作者探索了微调方法提高 LLMs 的效果。
作者研究了三种微调策略:
- 解答微调 Supervised step-by-step solution fine-tuning (SSFT)
- 解答类簇重排 solution-cluster re-ranking
- 多任务序列微调 multi-task sequential fine-tuning,将解答生成和评估任务结合
通过对PaLM2等模型进行研究,作者发现:
- 微调阶段使用的逐步解答数据的风格和质量会对模型性能有很大的影响;
- 解答重排和多数投票都能有效提高模型性能,可以一起使用;
- 多任务微调相比解答微调带来效果的提升
经过这些研究,作者设计了一个微调的方案,使用PaLM2-L 模型在 MATH 数据集上获得了58.8% 的准确性,提高了 11.2%。
用于比较的微调方案
Supervised step-by-step solution fine-tuning (SSFT)
基线,将 LLMs 微调为逐步生成解答方案和最终答案。
Solution-cluster Re-ranking (SCR)
将投票和重排结合,同时降低排序成本。将解答按照数学等效性讲候选答案分到不同的组内,进一步改善投票的结果。
Multi-task Sequential Fine-tuning
按照顺序微调模型:
- 作为解答生成器(SSFT)
- 作为解答评估器(SCR)
- 作为生成器(SSFT)
实验
数据集的选择:
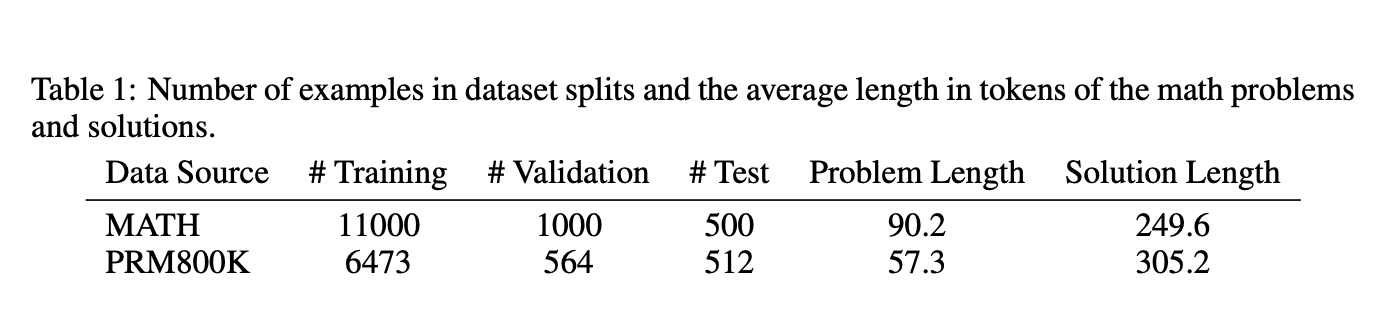
解码方案采用两种,贪心和top-p=0.95、temperature=0.9。
SSFT
作者对 PaLM2-S和PaLM2-L 上进行微调:1)使用原始的MATH数据集进行微调;2)使用PRM800K进行微调;3)同时使用两个数据集进行微调。
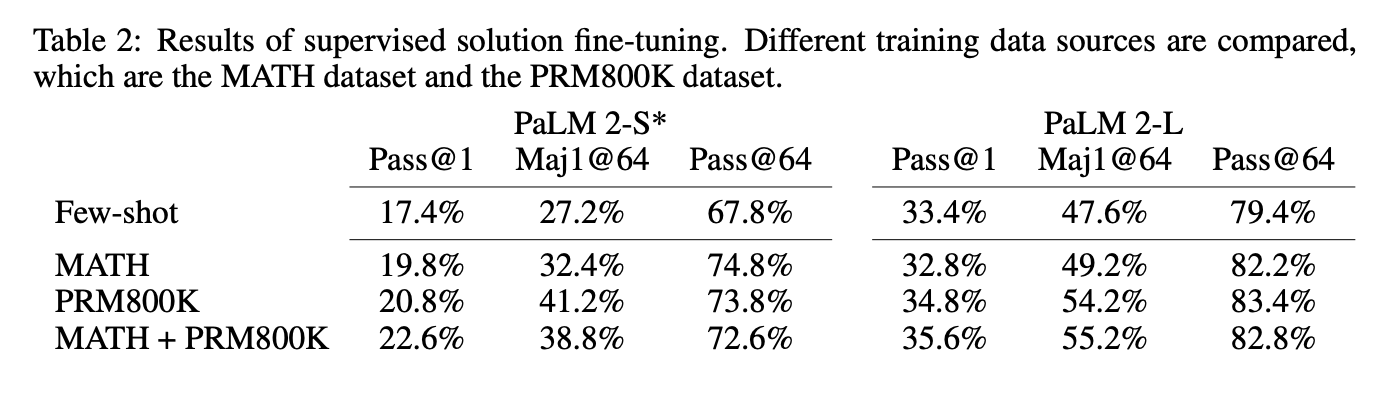
数据集的风格和数据会对模型微调效果产生影响。
SCR
之前的实验数据中pass@1和pass@64中存在巨大的效果差异,这表明模型具备解决问题的能力,但是无法区分不同的搜索结果。
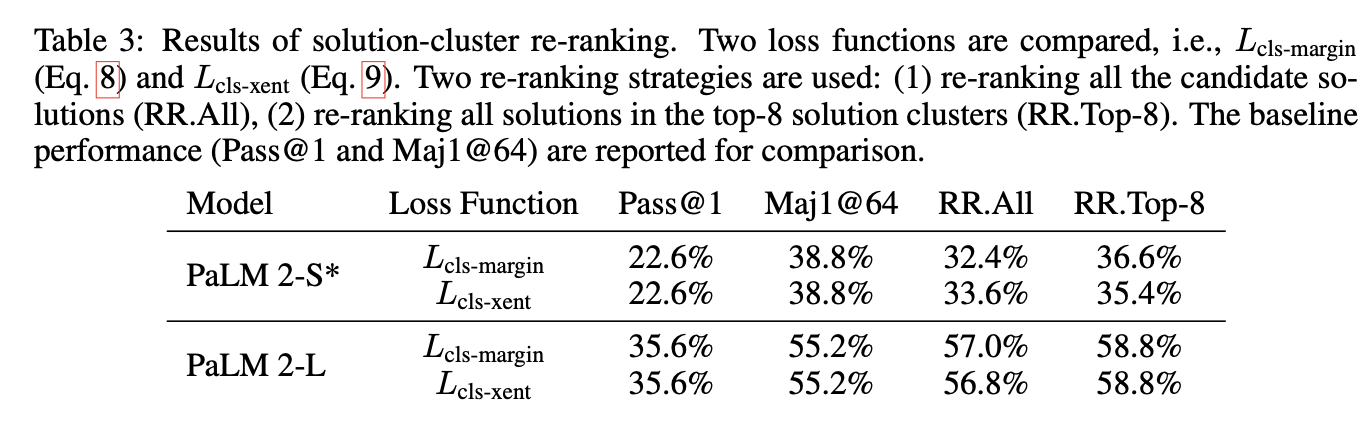
重新排名可以超越基线pass@1性能,然而只有PaLM-L模型才能超越大多数的基线,这说明较小的模型重排是个比较困难的任务。
只对前几个解答进行排序比全部排序要好,而且在计算上更有效率。
SOLUTION-CLUSTER RE-RANKING

多任务学习的模型可以获得比MLE训练的模型更好的效果。这表明评估方案的解决方案的训练目标可以为解答生成提供有用的监督信号。
分析

之前研究表明在PRM800K上的解答生成要比MATH数据集上要好。作者对这种差异是否会影响 few-shot的效果。实验表明,few-shot上的差异相差不大。

作者探索了重排方案是否可以用于其他模型,实验表明较小的模型无法对小模型和大模型进行重排,这说明重排是一个大模型才能做到任务。
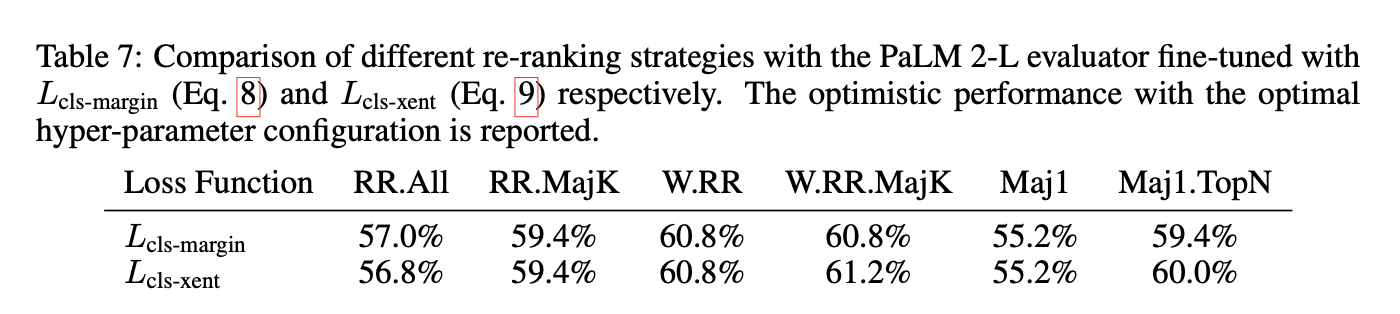
作者给出PaLM-L重排器和生成候选解答的参数配置。
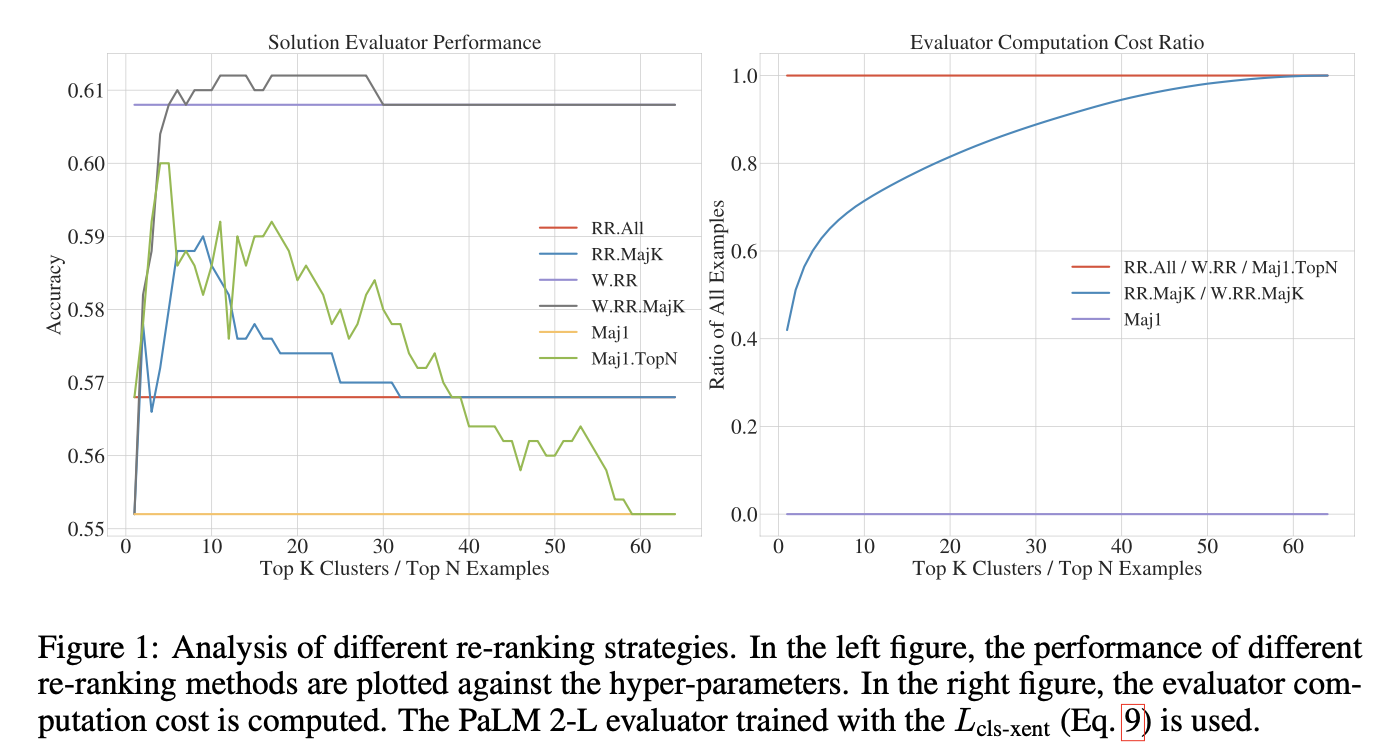
作者给出了重排和计算效率分析。实验表明加权重排的策略具有强大的性能,而作者提出的方案可以减少计算成本同时具有比较好的效果。
结论
作者研究了提高LLMs解决数学问题的微调方法。并且提出了一个重排的方案可以具备较好的准确性和计算效率。同时提出了一种多任务顺序微调的方案,具备较好的效果。
Til next time,
gqjia
at 00:00
