
为了能够完成200种语言的翻译任务,作者构建了一个数据集和一个 MoE 模型。模型在 FLORES-200(40000种翻译) 上进行验证,相比之前的 SOTA 模型在 BLEU 上提高了 44%。
数据部分跳过。
模型部分
moe层公式如下:
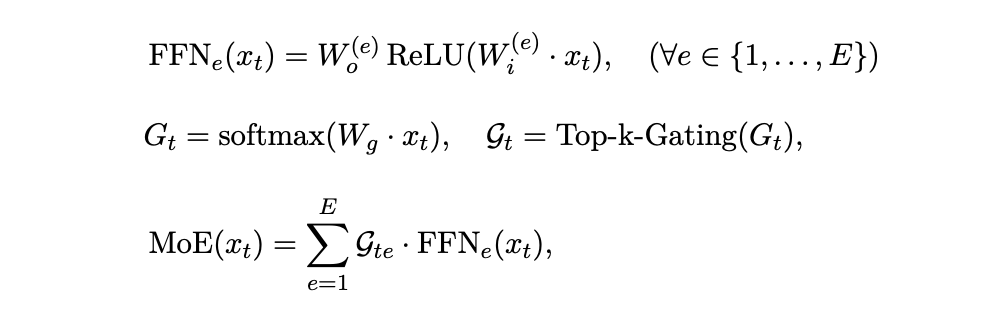
在 encoder 层上加上 MoE 层:
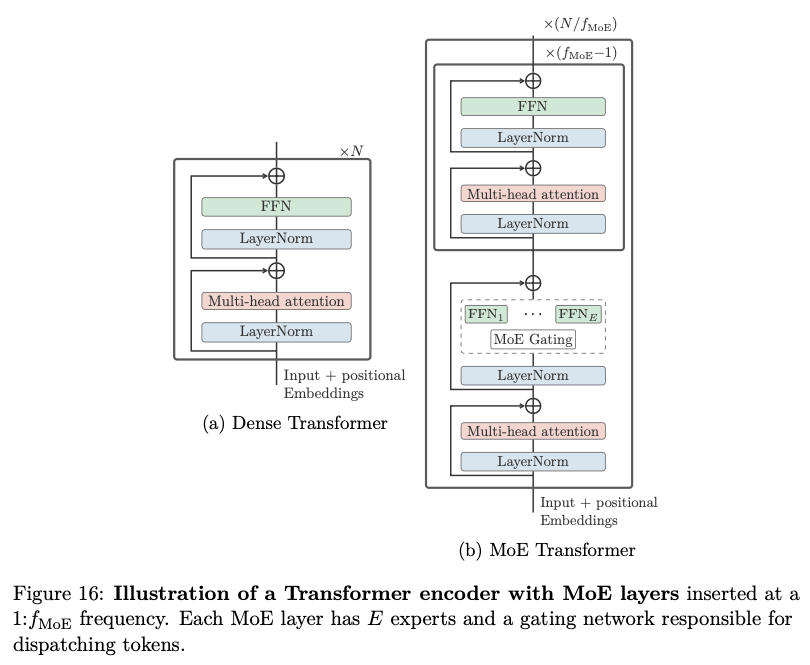
每个 MoE 层有 E 个expert 和 一个 gating network。在 gating network 部分 选择 top2 expert。
在 loss 计算部分 需要额外计算一个 LB loss :
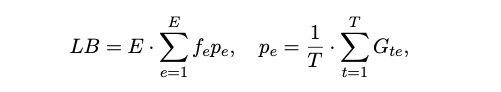
nllb_moe 模型代码
原本模型采用 m2m100 模型,其实就是单纯的 transformer结构,和mbart、bart一样。
MoE 部分添加到了 encoder 层中。原本 transformer encoder 层的代码如下(transformers中m2m100模型代码):
# Copied from transformers.models.mbart.modeling_mbart.MBartEncoderLayer with MBart->M2M100, MBART->M2M100
class M2M100EncoderLayer(nn.Module):
def __init__(self, config: M2M100Config):
super().__init__()
self.embed_dim = config.d_model
self.self_attn = M2M100_ATTENTION_CLASSES[config._attn_implementation](
embed_dim=self.embed_dim,
num_heads=config.encoder_attention_heads,
dropout=config.attention_dropout,
config=config,
)
self.self_attn_layer_norm = nn.LayerNorm(self.embed_dim)
self.dropout = config.dropout
self.activation_fn = ACT2FN[config.activation_function]
self.activation_dropout = config.activation_dropout
self.fc1 = nn.Linear(self.embed_dim, config.encoder_ffn_dim)
self.fc2 = nn.Linear(config.encoder_ffn_dim, self.embed_dim)
self.final_layer_norm = nn.LayerNorm(self.embed_dim)
def forward(
self,
hidden_states: torch.Tensor,
attention_mask: torch.Tensor,
layer_head_mask: torch.Tensor,
output_attentions: bool = False,
) -> torch.Tensor:
"""
Args:
hidden_states (`torch.FloatTensor`): input to the layer of shape `(batch, seq_len, embed_dim)`
attention_mask (`torch.FloatTensor`): attention mask of size
`(batch, 1, tgt_len, src_len)` where padding elements are indicated by very large negative values.
layer_head_mask (`torch.FloatTensor`): mask for attention heads in a given layer of size
`(encoder_attention_heads,)`.
output_attentions (`bool`, *optional*):
Whether or not to return the attentions tensors of all attention layers. See `attentions` under
returned tensors for more detail.
"""
residual = hidden_states
hidden_states = self.self_attn_layer_norm(hidden_states)
hidden_states, attn_weights, _ = self.self_attn(
hidden_states=hidden_states,
attention_mask=attention_mask,
layer_head_mask=layer_head_mask,
output_attentions=output_attentions,
)
hidden_states = nn.functional.dropout(hidden_states, p=self.dropout, training=self.training)
hidden_states = residual + hidden_states
residual = hidden_states
hidden_states = self.final_layer_norm(hidden_states)
hidden_states = self.activation_fn(self.fc1(hidden_states))
hidden_states = nn.functional.dropout(hidden_states, p=self.activation_dropout, training=self.training)
hidden_states = self.fc2(hidden_states)
hidden_states = nn.functional.dropout(hidden_states, p=self.dropout, training=self.training)
hidden_states = residual + hidden_states
if hidden_states.dtype == torch.float16 and (
torch.isinf(hidden_states).any() or torch.isnan(hidden_states).any()
):
clamp_value = torch.finfo(hidden_states.dtype).max - 1000
hidden_states = torch.clamp(hidden_states, min=-clamp_value, max=clamp_value)
outputs = (hidden_states,)
if output_attentions:
outputs += (attn_weights,)
return outputs
大致结构为:layernorm -> self-attention -> layernorm -> FFN
加上 MoE 层的代码如下(transformers中nllb_moe代码):
class NllbMoeEncoderLayer(nn.Module):
def __init__(self, config: NllbMoeConfig, is_sparse: bool = False):
super().__init__()
self.embed_dim = config.d_model
self.is_sparse = is_sparse
self.self_attn = NllbMoeAttention(
embed_dim=self.embed_dim,
num_heads=config.encoder_attention_heads,
dropout=config.attention_dropout,
)
self.attn_dropout = nn.Dropout(config.dropout)
self.self_attn_layer_norm = nn.LayerNorm(self.embed_dim)
if not self.is_sparse:
self.ffn = NllbMoeDenseActDense(config, ffn_dim=config.encoder_ffn_dim)
else:
self.ffn = NllbMoeSparseMLP(config, ffn_dim=config.encoder_ffn_dim)
self.ff_layer_norm = nn.LayerNorm(config.d_model)
self.ff_dropout = nn.Dropout(config.activation_dropout)
def forward(
self,
hidden_states: torch.Tensor,
attention_mask: torch.Tensor,
layer_head_mask: torch.Tensor,
output_attentions: bool = False,
output_router_logits: bool = False,
) -> torch.Tensor:
"""
Args:
hidden_states (`torch.FloatTensor`):
input to the layer of shape `(batch, seq_len, embed_dim)`
attention_mask (`torch.FloatTensor`):
attention mask of size `(batch, 1, tgt_len, src_len)` where padding elements are indicated by very
large negative values.
layer_head_mask (`torch.FloatTensor`): mask for attention heads in a given layer of size
`(encoder_attention_heads,)`.
output_attentions (`bool`, *optional*):
Whether or not to return the attentions tensors of all attention layers. See `attentions` under
returned tensors for more detail.
"""
residual = hidden_states
hidden_states = self.self_attn_layer_norm(hidden_states)
hidden_states, attn_weights, _ = self.self_attn(
hidden_states=hidden_states,
attention_mask=attention_mask,
layer_head_mask=layer_head_mask,
output_attentions=output_attentions,
)
hidden_states = self.attn_dropout(hidden_states)
hidden_states = residual + hidden_states
residual = hidden_states
hidden_states = self.ff_layer_norm(hidden_states)
if self.is_sparse:
hidden_states, router_states = self.ffn(hidden_states, attention_mask)
else:
# router_states set to None to track which layers have None gradients.
hidden_states, router_states = self.ffn(hidden_states), None
hidden_states = self.ff_dropout(hidden_states)
hidden_states = residual + hidden_states
if hidden_states.dtype == torch.float16 and (
torch.isinf(hidden_states).any() or torch.isnan(hidden_states).any()
):
clamp_value = torch.finfo(hidden_states.dtype).max - 1000
hidden_states = torch.clamp(hidden_states, min=-clamp_value, max=clamp_value)
outputs = (hidden_states,)
if output_attentions:
outputs += (attn_weights,)
if output_router_logits:
outputs += (router_states,)
return outputs
模型大致结构:layernorm -> self-attention -> layer_norm -> FFN(nllb_moe_act_dense/nllb-moe_sparese_mlp)
可以看到有两种 FFN ,而 encoder 部分则定义了怎么使用:
class NllbMoeEncoder(NllbMoePreTrainedModel):
def __init__(self, config: NllbMoeConfig, embed_tokens: Optional[nn.Embedding] = None):
super().__init__(config)
self.dropout = config.dropout
self.layerdrop = config.encoder_layerdrop
embed_dim = config.d_model
self.padding_idx = config.pad_token_id
self.max_source_positions = config.max_position_embeddings
self.embed_scale = math.sqrt(embed_dim) if config.scale_embedding else 1.0
self.embed_tokens = nn.Embedding(config.vocab_size, embed_dim, self.padding_idx)
if embed_tokens is not None:
self.embed_tokens.weight = embed_tokens.weight
self.embed_positions = NllbMoeSinusoidalPositionalEmbedding(
config.max_position_embeddings,
embed_dim,
self.padding_idx,
)
sparse_step = config.encoder_sparse_step # config.json: "encoder_sparse_step": 4,
self.layers = nn.ModuleList()
for i in range(config.encoder_layers):
is_sparse = (i + 1) % sparse_step == 0 if sparse_step > 0 else False # 每隔sparse_step层使用稀疏MLP
self.layers.append(NllbMoeEncoderLayer(config, is_sparse))
self.layer_norm = nn.LayerNorm(config.d_model)
self.gradient_checkpointing = False
# Initialize weights and apply final processing
self.post_init()
def forward(
self,
input_ids: Optional[torch.Tensor] = None,
attention_mask: Optional[torch.Tensor] = None,
head_mask: Optional[torch.Tensor] = None,
inputs_embeds: Optional[torch.Tensor] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
output_router_logits: Optional[bool] = None,
return_dict: Optional[bool] = None,
):
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
output_hidden_states = (
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
)
return_dict = return_dict if return_dict is not None else self.config.return_dict
# retrieve input_ids and inputs_embeds
if input_ids is not None and inputs_embeds is not None:
raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time")
elif input_ids is not None:
self.warn_if_padding_and_no_attention_mask(input_ids, attention_mask)
input_shape = input_ids.size()
input_ids = input_ids.view(-1, input_shape[-1])
elif inputs_embeds is not None:
input_shape = inputs_embeds.size()[:-1]
else:
raise ValueError("You have to specify either input_ids or inputs_embeds")
if inputs_embeds is None:
inputs_embeds = self.embed_tokens(input_ids) * self.embed_scale
embed_pos = self.embed_positions(input_ids, inputs_embeds)
embed_pos = embed_pos.to(inputs_embeds.device)
hidden_states = inputs_embeds + embed_pos
hidden_states = nn.functional.dropout(hidden_states, p=self.dropout, training=self.training)
# expand attention_mask
if attention_mask is not None:
# [bsz, seq_len] -> [bsz, 1, tgt_seq_len, src_seq_len]
attention_mask = _prepare_4d_attention_mask(attention_mask, inputs_embeds.dtype)
encoder_states = () if output_hidden_states else None
all_router_probs = () if output_router_logits else None
all_attentions = () if output_attentions else None
# check if head_mask has a correct number of layers specified if desired
if head_mask is not None:
if head_mask.size()[0] != len(self.layers):
raise ValueError(
f"The head_mask should be specified for {len(self.layers)} layers, but it is for"
f" {head_mask.size()[0]}."
)
for idx, encoder_layer in enumerate(self.layers):
if output_hidden_states:
encoder_states = encoder_states + (hidden_states,)
# add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
dropout_probability = torch.rand([])
if self.training and (dropout_probability < self.layerdrop): # skip the layer
layer_outputs = (None, None, None)
else:
if self.gradient_checkpointing and self.training:
layer_outputs = self._gradient_checkpointing_func(
encoder_layer.__call__,
hidden_states,
attention_mask,
(head_mask[idx] if head_mask is not None else None),
output_attentions,
)
else:
layer_outputs = encoder_layer(
hidden_states,
attention_mask,
layer_head_mask=(head_mask[idx] if head_mask is not None else None),
output_attentions=output_attentions,
output_router_logits=output_router_logits,
)
hidden_states = layer_outputs[0]
if output_attentions:
all_attentions += (layer_outputs[1],)
if output_router_logits:
all_router_probs += (layer_outputs[-1],)
last_hidden_state = self.layer_norm(hidden_states)
if output_hidden_states:
encoder_states += (last_hidden_state,)
if not return_dict:
return tuple(
v for v in [last_hidden_state, encoder_states, all_attentions, all_router_probs] if v is not None
)
return MoEModelOutput(
last_hidden_state=last_hidden_state,
hidden_states=encoder_states,
attentions=all_attentions,
router_probs=all_router_probs,
)
nllb-moe-54b 模型的config.json中 “encoder_sparse_step”: 4
每隔sparse_step层使用稀疏 NllbMoeSparseMLP,其余使用 NllbMoeDenseActDense
下面具体来看每个 FFN是怎么写的。
先看 NllbMoeDenseActDense:
class NllbMoeDenseActDense(nn.Module):
def __init__(self, config: NllbMoeConfig, ffn_dim: int):
super().__init__()
self.fc1 = nn.Linear(config.d_model, ffn_dim)
self.fc2 = nn.Linear(ffn_dim, config.d_model)
self.dropout = nn.Dropout(config.activation_dropout)
self.act = ACT2FN[config.activation_function]
def forward(self, hidden_states):
hidden_states = self.fc1(hidden_states)
hidden_states = self.act(hidden_states)
hidden_states = self.dropout(hidden_states)
if (
isinstance(self.fc2.weight, torch.Tensor)
and hidden_states.dtype != self.fc2.weight.dtype
and (self.fc2.weight.dtype != torch.int8 and self.fc2.weight.dtype != torch.uint8)
):
hidden_states = hidden_states.to(self.fc2.weight.dtype)
hidden_states = self.fc2(hidden_states)
return hidden_states
就是正常的 transformer ffn 的结构。
而 NllbMoeSparseMLP 的代码如下:
class NllbMoeSparseMLP(nn.Module):
r"""
Implementation of the NLLB-MoE sparse MLP module.
"""
def __init__(self, config: NllbMoeConfig, ffn_dim: int, expert_class: nn.Module = NllbMoeDenseActDense):
super().__init__()
self.router = NllbMoeTop2Router(config) # router
self.moe_token_dropout = config.moe_token_dropout
self.token_dropout = nn.Dropout(self.moe_token_dropout)
self.num_experts = config.num_experts # number of experts "num_experts": 128,
self.experts = nn.ModuleDict()
for idx in range(self.num_experts): # create experts
self.experts[f"expert_{idx}"] = expert_class(config, ffn_dim)
def forward(self, hidden_states: torch.Tensor, padding_mask: Optional[torch.Tensor] = False):
r"""
The goal of this forward pass is to have the same number of operation as the equivalent `NllbMoeDenseActDense`
(mlp) layer. This means that all of the hidden states should be processed at most twice ( since we are using a
top_2 gating mecanism). This means that we keep the complexity to O(batch_size x sequence_length x hidden_dim)
instead of O(num_experts x batch_size x sequence_length x hidden_dim).
1- Get the `router_probs` from the `router`. The shape of the `router_mask` is `(batch_size X sequence_length,
num_expert)` and corresponds to the boolean version of the `router_probs`. The inputs are masked using the
`router_mask`.
2- Dispatch the hidden_states to its associated experts. The router probabilities are used to weight the
contribution of each experts when updating the masked hidden states.
Args:
hidden_states (`torch.Tensor` of shape `(batch_size, sequence_length, hidden_dim)`):
The hidden states
padding_mask (`torch.Tensor`, *optional*, defaults to `False`):
Attention mask. Can be in the causal form or not.
Returns:
hidden_states (`torch.Tensor` of shape `(batch_size, sequence_length, hidden_dim)`):
Updated hidden states
router_logits (`torch.Tensor` of shape `(batch_size, sequence_length, num_experts)`):
Needed for computing the loss
"""
batch_size, sequence_length, hidden_dim = hidden_states.shape
top_1_mask, router_probs = self.router(hidden_states, padding_mask) # 获取路由概率 router_probs: [batch_size, sequence_length, num_experts] top_1_mask: [batch_size, sequence_length, num_experts]
router_mask = router_probs.bool()
hidden_states = hidden_states.reshape((batch_size * sequence_length), hidden_dim) # [batch_size, sequence_length, hidden_dim] -> [batch_size * sequence_length, hidden_dim]
masked_hidden_states = torch.einsum("bm,be->ebm", hidden_states, router_mask) # [batch_size * sequence_length, hidden_dim] * [batch_size * sequence_length, num_experts] -> [num_experts, batch_size * sequence_length, hidden_dim]
for idx, expert in enumerate(self.experts.values()):
token_indices = router_mask[:, idx] # [batch_size * sequence_length, num_experts] -> [batch_size * sequence_length]
combining_weights = router_probs[token_indices, idx] # [batch_size * sequence_length, num_experts] -> [batch_size * sequence_length]
expert_output = expert(masked_hidden_states[idx, token_indices]) # [batch_size * sequence_length, hidden_dim]
if self.moe_token_dropout > 0:
if self.training:
expert_output = self.token_dropout(expert_output)
else:
expert_output *= 1 - self.moe_token_dropout
masked_hidden_states[idx, token_indices] = torch.einsum("b,be->be", combining_weights, expert_output) # [batch_size * sequence_length, hidden_dim] * [batch_size * sequence_length, num_experts] -> [num_experts, batch_size * sequence_length, hidden_dim]
hidden_states = masked_hidden_states.sum(dim=0).reshape(batch_size, sequence_length, hidden_dim) # [num_experts, batch_size * sequence_length, hidden_dim] -> [batch_size, sequence_length, hidden_dim]
top_1_expert_index = torch.argmax(top_1_mask, dim=-1) # [batch_size, sequence_length, num_experts] -> [batch_size, sequence_length]
return hidden_states, (router_probs, top_1_expert_index)
流程如下: hidden_states -> router(top_1_mask, router_probs) -> masked_hidden_states -> [expert1, expert2, …] -> dropout -> masked_hidden_states -> hidden_states
路由代码如下:
class NllbMoeTop2Router(nn.Module):
"""
Router using tokens choose top-2 experts assignment.
This router uses the same mechanism as in NLLB-MoE from the fairseq repository. Items are sorted by router_probs
and then routed to their choice of expert until the expert's expert_capacity is reached. **There is no guarantee
that each token is processed by an expert**, or that each expert receives at least one token.
The router combining weights are also returned to make sure that the states that are not updated will be masked.
"""
def __init__(self, config: NllbMoeConfig):
super().__init__()
self.num_experts = config.num_experts
self.expert_capacity = config.expert_capacity
self.classifier = nn.Linear(config.hidden_size, self.num_experts, bias=config.router_bias)
self.router_ignore_padding_tokens = config.router_ignore_padding_tokens
self.dtype = getattr(torch, config.router_dtype)
self.second_expert_policy = config.second_expert_policy
self.normalize_router_prob_before_dropping = config.normalize_router_prob_before_dropping
self.batch_prioritized_routing = config.batch_prioritized_routing
self.moe_eval_capacity_token_fraction = config.moe_eval_capacity_token_fraction
def _cast_classifier(self):
r"""
`bitsandbytes` `Linear8bitLt` layers does not support manual casting Therefore we need to check if they are an
instance of the `Linear8bitLt` class by checking special attributes.
"""
if not (hasattr(self.classifier, "SCB") or hasattr(self.classifier, "CB")):
self.classifier = self.classifier.to(self.dtype)
def normalize_router_probabilities(self, router_probs, top_1_mask, top_2_mask):
top_1_max_probs = (router_probs * top_1_mask).sum(dim=1)
top_2_max_probs = (router_probs * top_2_mask).sum(dim=1)
denom_s = torch.clamp(top_1_max_probs + top_2_max_probs, min=torch.finfo(router_probs.dtype).eps)
top_1_max_probs = top_1_max_probs / denom_s
top_2_max_probs = top_2_max_probs / denom_s
return top_1_max_probs, top_2_max_probs
def route_tokens(
self,
router_logits: torch.Tensor,
input_dtype: torch.dtype = torch.float32,
padding_mask: Optional[torch.LongTensor] = None,
) -> Tuple:
"""
Computes the `dispatch_mask` and the `dispatch_weights` for each experts. The masks are adapted to the expert
capacity.
"""
nb_tokens = router_logits.shape[0] # batch_size * sequence_length
# Apply Softmax and cast back to the original `dtype`
router_probs = nn.functional.softmax(router_logits, dim=-1, dtype=self.dtype).to(input_dtype) # [batch_size * sequence_length, num_experts]
top_1_expert_index = torch.argmax(router_probs, dim=-1) # [batch_size * sequence_length]
top_1_mask = torch.nn.functional.one_hot(top_1_expert_index, num_classes=self.num_experts) # [batch_size * sequence_length, num_experts]
if self.second_expert_policy == "sampling": # sampling
gumbel = torch.distributions.gumbel.Gumbel(0, 1).rsample # 采样 gumbel分布
router_logits += gumbel(router_logits.shape).to(router_logits.device)
# replace top_1_expert_index with min values
logits_except_top_1 = router_logits.masked_fill(top_1_mask.bool(), float("-inf")) # [batch_size * sequence_length, num_experts] 去掉top_1_expert_index对应的值
top_2_expert_index = torch.argmax(logits_except_top_1, dim=-1) # [batch_size * sequence_length] 获取到top_2_expert_index
top_2_mask = torch.nn.functional.one_hot(top_2_expert_index, num_classes=self.num_experts) # [batch_size * sequence_length, num_experts]
if self.normalize_router_prob_before_dropping:
top_1_max_probs, top_2_max_probs = self.normalize_router_probabilities(
router_probs, top_1_mask, top_2_mask
)
if self.second_expert_policy == "random":
top_2_max_probs = (router_probs * top_2_mask).sum(dim=1)
sampled = (2 * top_2_max_probs) > torch.rand_like(top_2_max_probs.float()) # [batch_size * sequence_length]
top_2_mask = top_2_mask * sampled.repeat(self.num_experts, 1).transpose(1, 0)
if padding_mask is not None and not self.router_ignore_padding_tokens:
if len(padding_mask.shape) == 4:
# only get the last causal mask
padding_mask = padding_mask[:, :, -1, :].reshape(-1)[-nb_tokens:]
non_padding = ~padding_mask.bool()
top_1_mask = top_1_mask * non_padding.unsqueeze(-1).to(top_1_mask.dtype)
top_2_mask = top_2_mask * non_padding.unsqueeze(-1).to(top_1_mask.dtype)
if self.batch_prioritized_routing:
# sort tokens based on their routing probability
# to make sure important tokens are routed, first
importance_scores = -1 * router_probs.max(dim=1)[0]
sorted_top_1_mask = top_1_mask[importance_scores.argsort(dim=0)]
sorted_cumsum1 = (torch.cumsum(sorted_top_1_mask, dim=0) - 1) * sorted_top_1_mask
locations1 = sorted_cumsum1[importance_scores.argsort(dim=0).argsort(dim=0)]
sorted_top_2_mask = top_2_mask[importance_scores.argsort(dim=0)]
sorted_cumsum2 = (torch.cumsum(sorted_top_2_mask, dim=0) - 1) * sorted_top_2_mask
locations2 = sorted_cumsum2[importance_scores.argsort(dim=0).argsort(dim=0)]
# Update 2nd's location by accounting for locations of 1st
locations2 += torch.sum(top_1_mask, dim=0, keepdim=True)
else:
locations1 = torch.cumsum(top_1_mask, dim=0) - 1 # [batch_size * sequence_length, num_experts] -> [batch_size * sequence_length, num_experts] torch.cumsum()函数的作用是沿着指定维度计算累积和,比如说[1,2,3,4],沿着dim=0计算累积和,就是[1,3,6,10]
locations2 = torch.cumsum(top_2_mask, dim=0) - 1 # 这一步的作用是将top_1_mask和top_2_mask中的1的位置进行累加,得到每个expert的token数量
# Update 2nd's location by accounting for locations of 1st
locations2 += torch.sum(top_1_mask, dim=0, keepdim=True)
if not self.training and self.moe_eval_capacity_token_fraction > 0: # config: moe_eval_capacity_token_fraction: 1.0
self.expert_capacity = math.ceil(self.moe_eval_capacity_token_fraction * nb_tokens) # self.expert_capacity
else:
capacity = 2 * math.ceil(nb_tokens / self.num_experts) # 设置一个expert的容量,这里设置为2 * math.ceil(nb_tokens / self.num_experts)
self.expert_capacity = capacity if self.expert_capacity is None else self.expert_capacity
# Remove locations outside capacity from ( cumsum < capacity = False will not be routed)
top_1_mask = top_1_mask * torch.lt(locations1, self.expert_capacity) # torch.lt()函数的作用是逐元素比较input和other,即input < other,则返回True,否则返回False
top_2_mask = top_2_mask * torch.lt(locations2, self.expert_capacity)
if not self.normalize_router_prob_before_dropping:
top_1_max_probs, top_2_max_probs = self.normalize_router_probabilities(
router_probs, top_1_mask, top_2_mask
)
# Calculate combine_weights and dispatch_mask
gates1 = top_1_max_probs[:, None] * top_1_mask
gates2 = top_2_max_probs[:, None] * top_2_mask
router_probs = gates1 + gates2 # [batch_size * sequence_length, num_experts] + [batch_size * sequence_length, num_experts] -> [batch_size * sequence_length, num_experts]
return top_1_mask, router_probs
def forward(self, hidden_states: torch.Tensor, padding_mask: Optional[torch.LongTensor] = None) -> Tuple:
r"""
The hidden states are reshaped to simplify the computation of the router probabilities (combining weights for
each experts.)
Args:
hidden_states (`torch.Tensor`):
(batch_size, sequence_length, hidden_dim) from which router probabilities are computed.
Returns:
top_1_mask (`torch.Tensor` of shape (batch_size, sequence_length)):
Index tensor of shape [batch_size, sequence_length] corresponding to the expert selected for each token
using the top1 probabilities of the router.
router_probabilities (`torch.Tensor` of shape (batch_size, sequence_length, nump_experts)):
Tensor of shape (batch_size, sequence_length, num_experts) corresponding to the probabilities for each
token and expert. Used for routing tokens to experts.
router_logits (`torch.Tensor` of shape (batch_size, sequence_length))):
Logits tensor of shape (batch_size, sequence_length, num_experts) corresponding to raw router logits.
This is used later for computing router z-loss.
"""
self.input_dtype = hidden_states.dtype
batch_size, sequence_length, hidden_dim = hidden_states.shape
hidden_states = hidden_states.reshape((batch_size * sequence_length), hidden_dim) # [batch_size, sequence_length, hidden_dim] -> [batch_size * sequence_length, hidden_dim]
hidden_states = hidden_states.to(self.dtype)
self._cast_classifier()
router_logits = self.classifier(hidden_states) # [batch_size * sequence_length, hidden_dim] -> [batch_size * sequence_length, num_experts]
top_1_mask, router_probs = self.route_tokens(router_logits, self.input_dtype, padding_mask) # top_1_mask: [batch_size * sequence_length, num_experts] router_probs: [batch_size * sequence_length, num_experts]
return top_1_mask, router_probs
先通过线性层和softmax 获取到 top1 的expert 。top2的expert 就比较复杂,如果是通过采样,代码设置了Gumbel采样,然后获取到除top1 expert外概率最大的expert。
Til next time,
gqjia
at 00:00
