
介绍地址:
https://deepmind.google/technologies/gemini/#introduction
博客地址:
Introducing Gemini: our largest and most capable AI model
How it’s Made: Interacting with Gemini through multimodal prompting
技术报告:
Gemini: A Family of Highly Capable Multimodal Models
博客 Introducing Gemini
博客提到了
Gemini is the result of large-scale collaborative efforts by teams across Google, including our colleagues at Google Research. It was built from the ground up to be multimodal, which means it can generalize and seamlessly understand, operate across and combine different types of information including text, code, audio, image and video.
只能说不愧是 google 。
在文本方向:
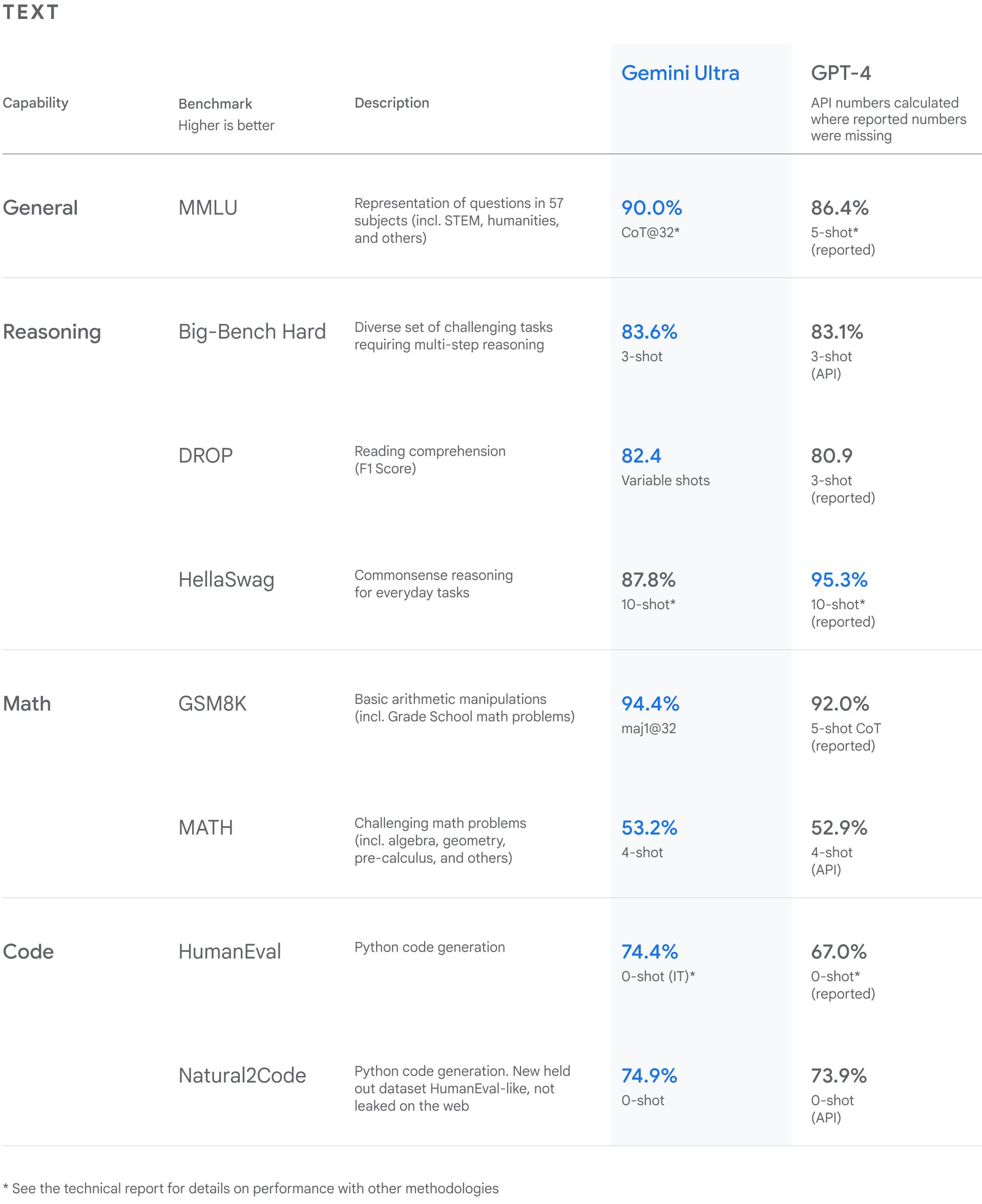
MMLU 上高达 90%,第一个超过人类的模型。
多模态方向:
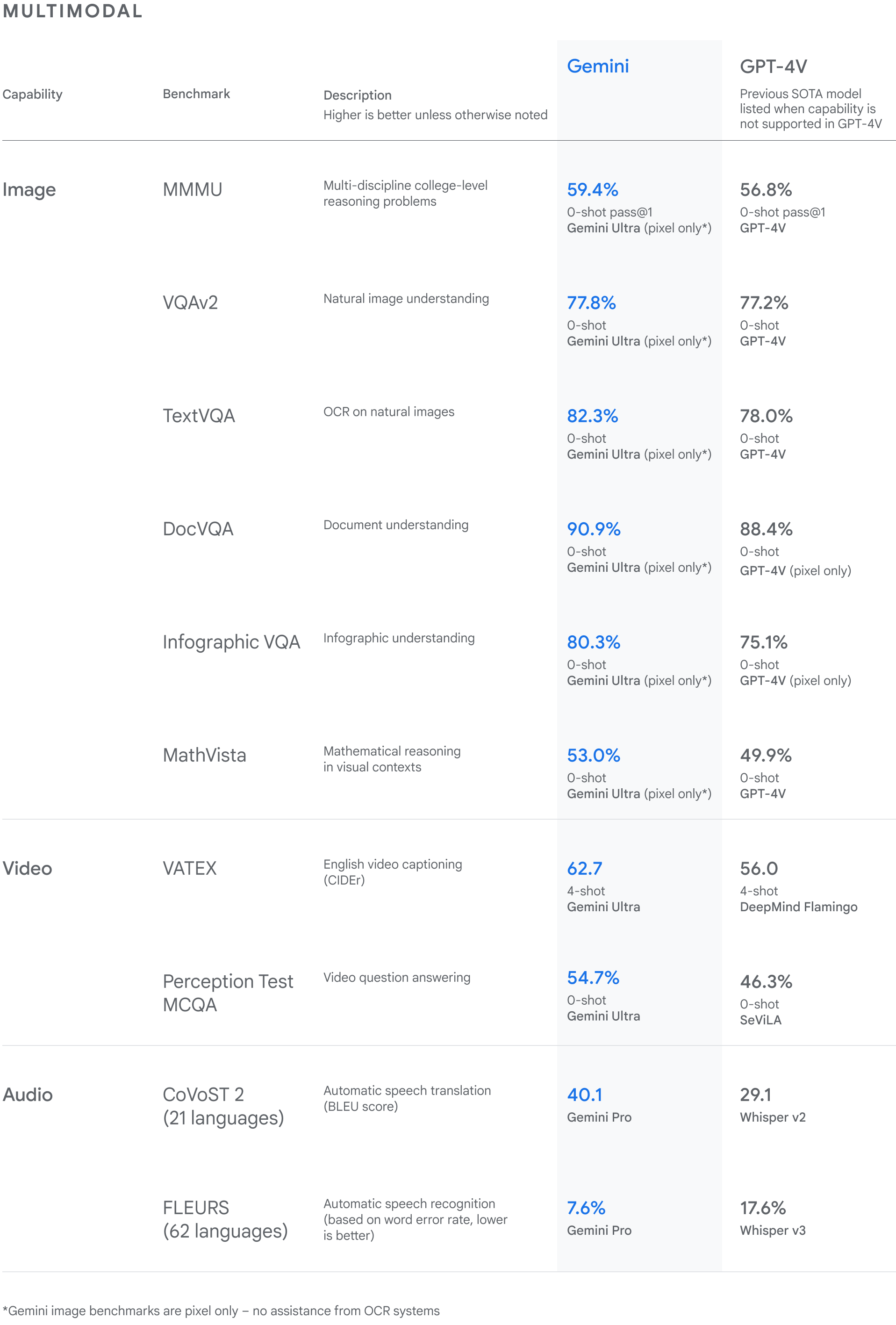
不仅暴打 GPT-4V 还要暴打 Flamingo、SeViLA、Whisper。
Until now, the standard approach to creating multimodal models involved training separate components for different modalities and then stitching them together to roughly mimic some of this functionality. These models can sometimes be good at performing certain tasks, like describing images, but struggle with more conceptual and complex reasoning.
We designed Gemini to be natively multimodal, pre-trained from the start on different modalities. Then we fine-tuned it with additional multimodal data to further refine its effectiveness. This helps Gemini seamlessly understand and reason about all kinds of inputs from the ground up, far better than existing multimodal models — and its capabilities are state of the art in nearly every domain.
原本以为是类似 NExT-GPT 的,但是看这段描述是直接从多模态开始预训练的。
Gemini 1.0 模型是拿 TPU v4 和 v5e进行训练的。并且模型进行了全面的安全评估。google 使用 真实毒性prompt 之类的基准进行了检验。有关这项工作的更多细节之后会推出。至于 Ultra 版本还在进行RLHF训练。
google内部的 bard 将使用 pro 版本进行微调,Pixel 也会接入 Gemini, Search Generative Experience (SGE)上也会开始实验。
至于开发者可以用 google ai studio 和 google cloud vertex ai 中的 api 使用 pro 版本。
技术报告
Gemini 的三个版本:Ultra 用来完成复杂的任务;pro用来大规模部署,并且在广泛的任务上都取得好的效果;nano用来做一些设备上的应用。
Nano 包含 1.8B(Nano-1)和3.25B(Nano-2)两个版本。他们是从更大的模型蒸馏得到, 可以 4-bit 量化部署。
模型结构

Gemini 模型是 transformer decoder 的基础上做了改进以适用 TPU 训练。技术报告还提到了他们使用了更高效的注意力机制,例如 mulit-query attention。模型能支持 32k 的上下文,目前的 LLM 比如 qwen 在 8k 长度上训练 通过插值后的长度也是 32K。
Gemini 模型的视觉编码部分的基础工作是 Flamingo 、CoCa和PaLI。视频信息被拆为一系列帧,然后进行编码。技术报告提到,视频帧或者图像可以很自然地与文本或者音频交织在一起作为模型输入的一部分。Gemini 可以直接从 USM(Universal Speech Model)获取到 16KHz 的语音信号,这可以减少从音频转为文本的信息丢失。
训练配置
Gemini 模型使用 TPUv5e 和 TPUv4 进行训练,甚至训练 Ultra 需要用多个数据中心的 TPUv4 accelerator 。代码用了 Jax 和 Pathways。
训练数据
Gemini 模型在多模态、多语言的数据集上进行训练。预训练数据包括:网站文档、书和代码,涵盖图像、语音和视频数据。
Gemini 用的 sentencepiece tokenizer ,从完整训练语料库中抽取一个大的采样,以此来训练 tokenizer。这样不仅可以提高效果,而可以高效的对 非拉丁语进行分词以及提高训练和推理速度。
模型训练的 token 量遵循 Hoffmann 的方案。小模型会在更多数据上训练以提高推理效果,类似 Touvron 的方案。
数据清洗部分:1)使用规则和基于模型的分类器对数据进行筛选;2)去除有害内容;3)从训练语料中筛出测试集。最终数据混合的比例和权重是通过对小模型进行消融实验得到。模型的训练是分阶段进行的,以便调整数据混合的比例,在训练的最终阶段增加专业领域的数据的权重。数据的质量对于训练模型非常重要,数据混合的比例也值得继续研究。
评估
文本任务上:
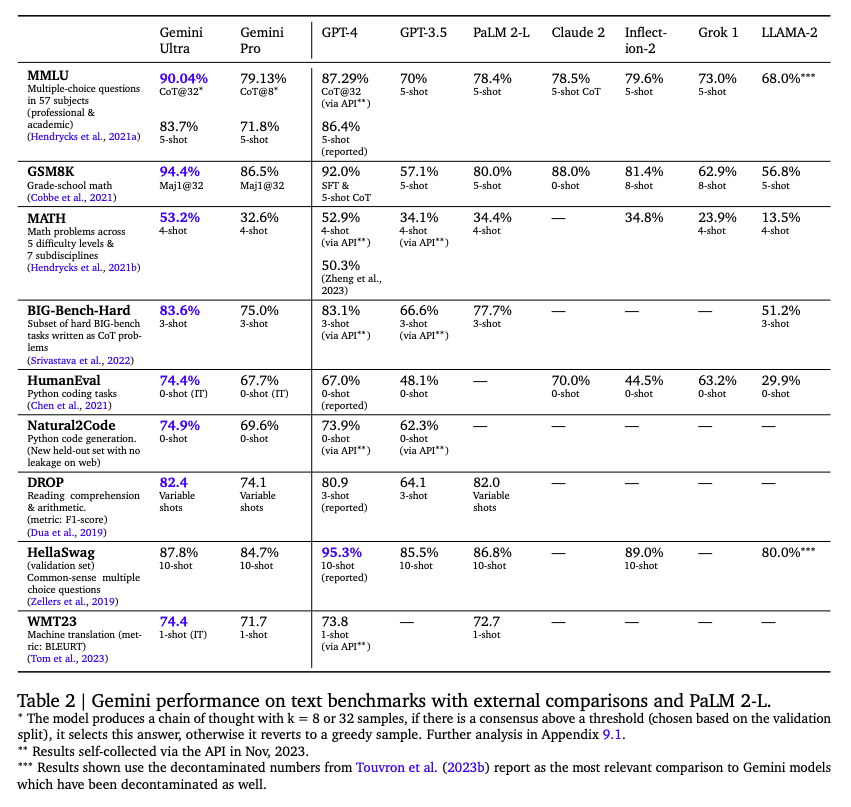
在多语言上,翻译任务1-shot 的效果:
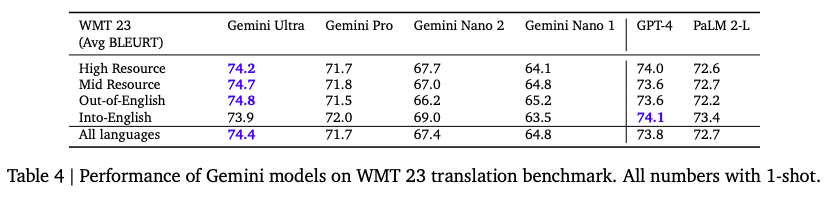
看起来像差没有太多。
但是在多语言的数学和摘要任务上:

在 8-shot MGSM 比 GPT4 高不少。
Gemini 模型是在 32768 token 长度的序列上进行训练的!
作者证明 Gemini 充分利用了上下文的实验如下:将 key-value 对放到上下文的开头,填充长文本,然后训练特定 key 对应的 value。
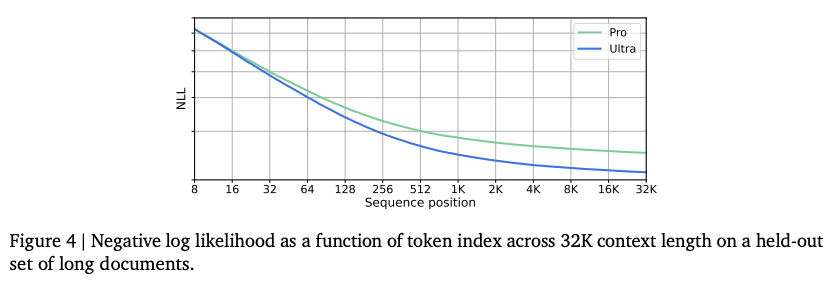
多模态任务上:
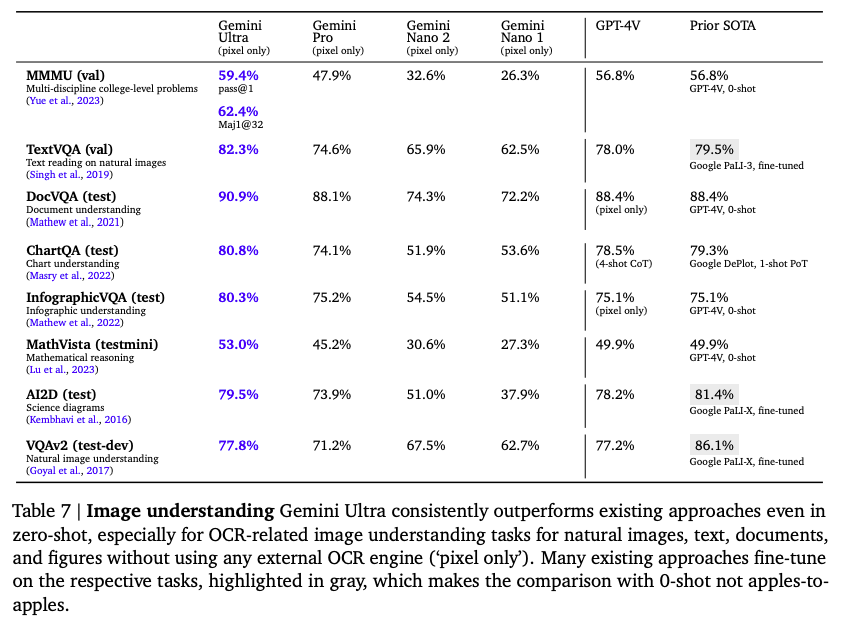
图像理解任务:
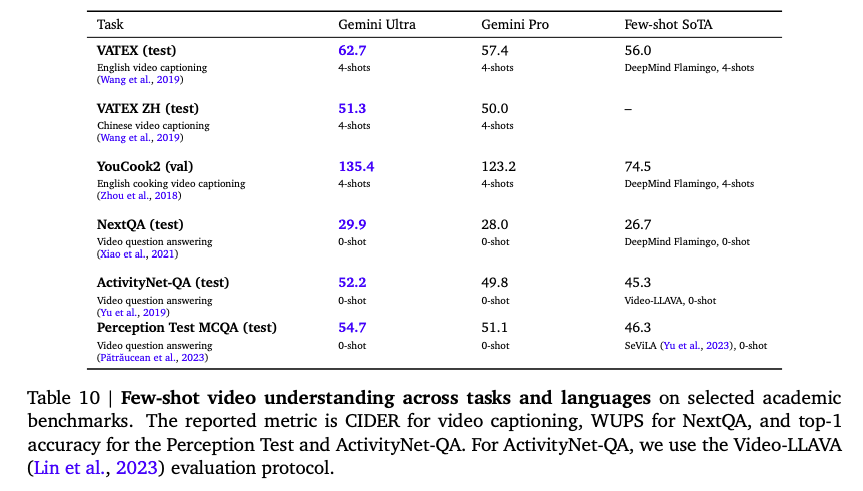
视频理解任务:
图像生成任务:

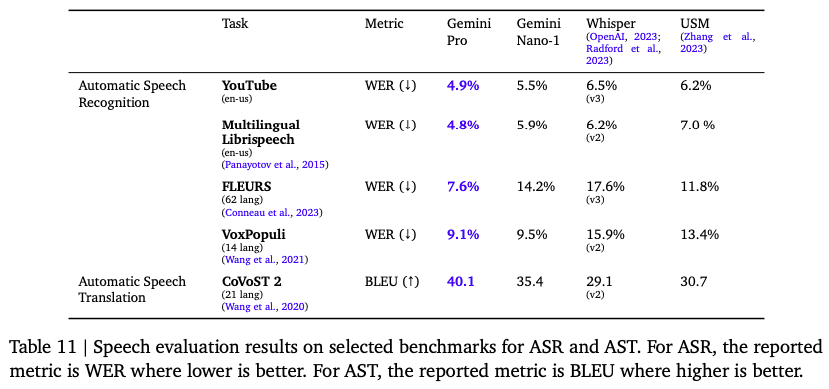
语音理解:
多模态结合的任务:

附录 9.1 Chain-of-Thought Comparisons on MMLU benchmark
作者提出了一个新的 CoT 方法 uncertainty-routed chain-of-thought,模型先生成 K 个CoT 样例,如果模型的信心高于阈值,则选择投票最多的,否则则使用贪心的结果。
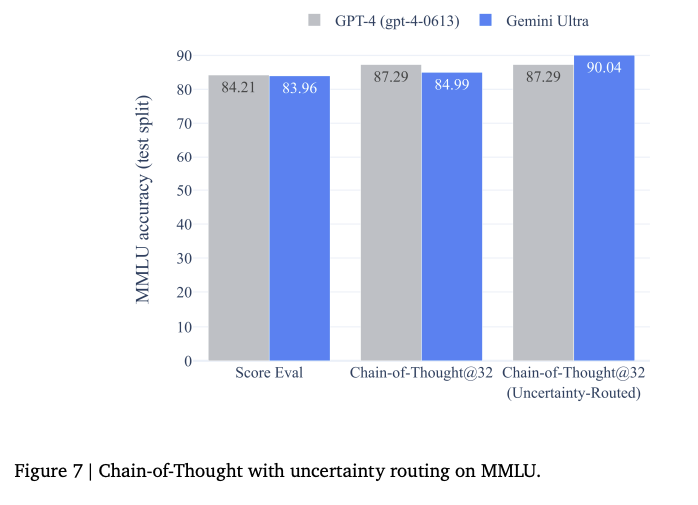
这分数,在不用这种 CoT 方法时,也没超过GPT4呀。
Til next time,
gqjia
at 00:00
